1. 安装 sshpass
sshpass 是一个可以自动输入密码的工具。如果未安装,运行以下命令安装:
• 对于 Debian/Ubuntu 系统:
bash展开代码apt update && apt install sshpass
• 对于 CentOS/RHEL 系统:
bash展开代码yum install sshpass
使用SSH密钥认证是一种比密码认证更安全的方式,因为它依赖于加密的密钥对,而不是容易被暴力破解的密码。以下是详细步骤,帮助您在服务器上配置SSH密钥认证并禁用密码认证。
Gitea 和 GitLab 的主要差异
| 对比项 | Gitea | GitLab |
|---|---|---|
| 核心定位 | 轻量级 Git 仓库管理 | 全功能 DevOps 平台 |
| 资源占用 | 低(内存:100MB+,CPU:单核即可) | 高(内存:4GB+,CPU:多核推荐) |
| 安装复杂度 | 简单,依赖少 | 复杂,依赖多(PostgreSQL、Redis 等) |
| 代码管理 | 基础 Git 仓库管理 | 强大的 Git 仓库管理,支持代码审查、合并请求等 |
| CI/CD | 无内置 CI/CD,需通过插件或外部工具 | 内置完整的 CI/CD 流水线,支持自动化构建、测试和部署 |
| 项目管理 | 基础问题跟踪和 Wiki | 完整的项目管理工具,包括看板、里程碑、时间跟踪等 |
| 用户权限管理 | 基础权限控制 | 细粒度的权限管理和角色控制 |
| 监控与运维 | 无内置监控工具 | 内置监控、日志管理和性能分析工具 |
| 容器镜像仓库 | 不支持 | 支持内置容器镜像仓库(Container Registry) |
| 集成与扩展 | 支持 Webhook 和插件扩展 | 支持丰富的 API 和插件,生态更完善 |
| 社区与生态 | 社区活跃,生态较小 | 社区和生态非常强大,文档丰富 |
| 开源与商业版 | 完全开源,免费使用 | 提供开源社区版(GitLab CE)和商业版(GitLab EE) |
| 适用场景 | 个人开发者、小型团队、资源有限环境 | 中大型团队或企业,需要完整 DevOps 工具链 |
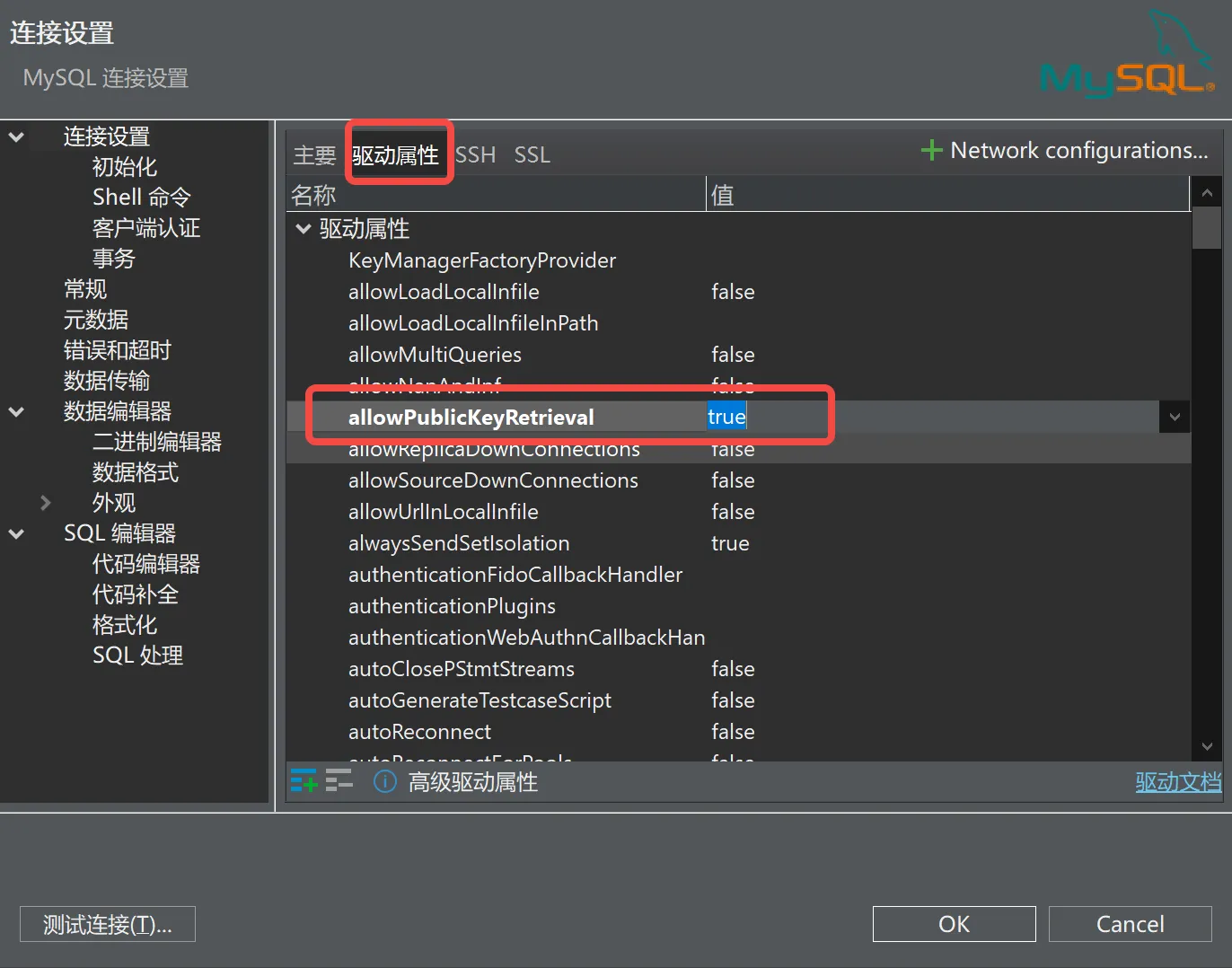
点驱动属性,然后设置图里这个allowPublicKey Retrieval为true。
如何在 Docker Compose 中检查服务连通性
在使用 Docker Compose 部署多容器应用时,确保服务之间的连通性非常重要。以下是一个简单的方法,教你如何进入一个容器并检查另一个服务是否通。
建议使用官方的 Ubuntu 镜像。
bash展开代码docker run -it ubuntu:22.04 bash
然后在容器内安装 Python 和 pip:
bash展开代码apt-get update
apt-get install -y python3 python3-pip
pip install 'litellm[proxy]'
1. 关闭 Cloudflare 代理(DNS only)和打开 Cloudflare 代理(Proxied)的区别
关闭 Cloudflare 代理(DNS only)
• 工作原理:Cloudflare 仅作为 DNS 解析服务,将域名解析到你的服务器 IP。用户的请求会直接访问你的服务器,不经过 Cloudflare 的 CDN 网络。 • 优点: • 用户直接连接到你的服务器,延迟更低。 • 适合不需要 CDN 加速或 DDoS 防护的场景。 • 缺点: • 你的服务器 IP 会暴露在公网,可能会受到攻击。 • 没有 Cloudflare 的 DDoS 防护和缓存功能。
打开 Cloudflare 代理(Proxied)
• 工作原理:Cloudflare 作为反向代理,用户的请求会先经过 Cloudflare 的 CDN 网络,再由 Cloudflare 转发到你的服务器。 • 优点: • 隐藏了你的服务器 IP,增强了安全性。 • 提供 DDoS 防护、缓存加速和 HTTPS 支持。 • 可以配置 Cloudflare 的防火墙规则,过滤恶意流量。 • 缺点: • 用户的请求需要经过 Cloudflare 的 CDN 网络,可能会增加延迟。 • 某些服务(如 Let's Encrypt 的 HTTP 验证)可能无法通过 Cloudflare 代理正常工作。
复制所有指令在命令行执行:
bash展开代码#!/bin/bash
# 检查是否已经安装了 Docker
if ! command -v docker &> /dev/null; then
echo "Docker 未安装,开始安装 Docker..."
# 更新系统软件包
sudo apt-get update -y
# 安装必要的依赖包
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
# 添加 Docker 的官方 GPG 密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 添加 Docker 的官方仓库
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 更新软件包索引
sudo apt-get update -y
# 安装 Docker 引擎
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
# 启动并启用 Docker 服务
sudo systemctl start docker
sudo systemctl enable docker
# 验证 Docker 安装
sudo docker run hello-world
else
echo "Docker 已安装,跳过安装步骤。"
fi
# 检查是否已经安装了 Docker Compose
if ! command -v docker-compose &> /dev/null; then
echo "Docker Compose 未安装,开始安装 Docker Compose..."
# 下载 Docker Compose 二进制文件
sudo curl -L "https://github.com/docker/compose/releases/download/$(curl -s https://api.github.com/repos/docker/compose/releases/latest | grep -Po '"tag_name": "\K.*?(?=")')/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 为 Docker Compose 二进制文件添加执行权限
sudo chmod +x /usr/local/bin/docker-compose
# 创建符号链接(可选)
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
# 验证 Docker Compose 安装
docker-compose --version
else
echo "Docker Compose 已安装,跳过安装步骤。"
fi
echo "Docker 和 Docker Compose 安装完成"
