目录
使用 vllm 部署 Qwen2VL API
参考资料:
官方文档:vllm 部署指南
使用官方镜像部署:
可以直接使用官网提供的 Docker 镜像,命令如下:
bash展开代码docker run --runtime nvidia --gpus device=0 \ -p 8006:8000 \ --ipc=host \ -v /root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4:/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4 \ vllm/vllm-openai:latest \ --model /root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4
运行后的界面如下图所示:
Dockerfile 说明:
Dockerfile 的最后一行是:
bash展开代码ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server"]
因此,通过这个命令我们可以直接传入参数 --model /root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4 来启动模型。
关于 Dockerfile 的详细逻辑可以参考官方文档:Dockerfile 说明
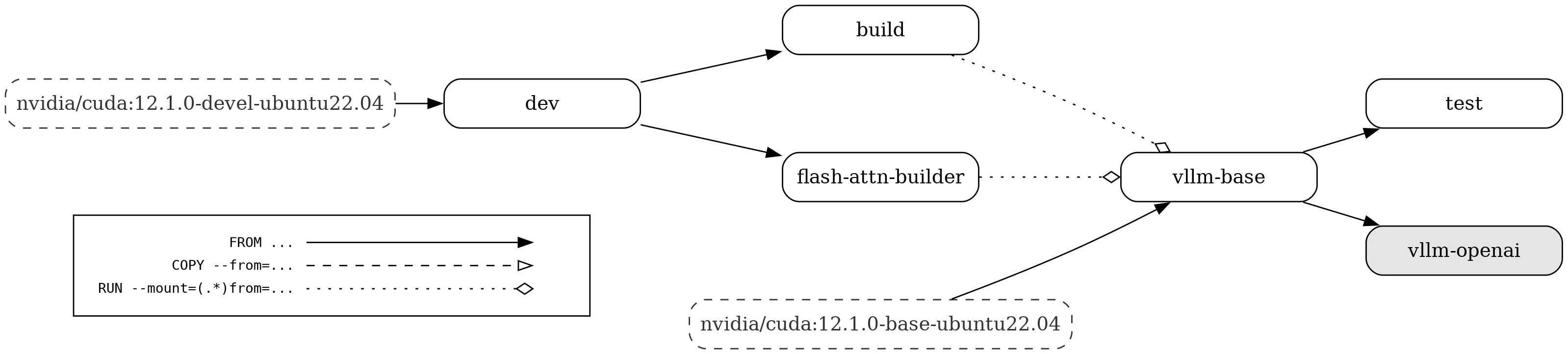
构建流程图如下:
自定义编译镜像:
如果你希望自己构建镜像,可以执行以下步骤:
bash展开代码git clone --branch v0.6.3 --depth 1 https://github.com/vllm-project/vllm.git
cd vllm
docker build -f Dockerfile . --target vllm-openai --tag vllm/vllm-openai
官方还提供了多种镜像选择,可以在 Docker Hub 中查看。
测试 API 性能:
可以使用以下代码测试 API 的响应速度:
python展开代码import time
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://101.136.22.140:8006/v1')
model_name = client.models.list().data[0].id
promptx = r"Describe this image."
# 图片文件列表
image_files = [
'http://101.136.22.140:8007/demo1024.jpeg',
'http://101.136.22.140:8007/demo1280.jpeg',
'http://101.136.22.140:8007/demo256.jpeg',
'http://101.136.22.140:8007/demo2560.jpeg',
'http://101.136.22.140:8007/demo512.jpeg',
'http://101.136.22.140:8007/demo768.jpeg'
]
# 存储每张图片的平均时间
average_times = {}
for image_file in image_files:
total_time = 0.0
successful_requests = 0
for i in range(10):
start_time = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{
'role': 'user',
'content': [{
'type': 'text',
'text': promptx,
}, {
'type': 'image_url',
'image_url': {
'url': image_file,
},
}],
}],
temperature=0.8,
top_p=0.8
)
print(response.choices[0].message.content)
end_time = time.time()
total_time += (end_time - start_time)
successful_requests += 1
average_times[image_file] = total_time / successful_requests
print(f"{image_file} 的平均时间: {average_times[image_file]:.2f} 秒\n")
# 打印摘要
print("平均时间摘要:")
for image, avg_time in average_times.items():
if avg_time is not None:
print(f"{image}: {avg_time:.2f} 秒")
else:
print(f"{image}: 所有请求均失败。")
测试结果分析:
针对不同尺寸的图片,我们测试了不同的 max_pixels 设置下的执行时间,结果如下:
max_pixels 设置 1280*28*28
| 图片尺寸(像素) | 尺寸(宽x高) | 平均执行时间(秒) |
|---|---|---|
| 256 | 384 x 256 | 3.69 |
| 512 | 768 x 512 | 3.73 |
| 768 | 1152 x 768 | 5.19 |
| 1024 | 1536 x 1024 | 5.19 |
| 1280 | 1920 x 1280 | 4.79 |
| 2560 | 3840 x 2560 | 6.44 |
max_pixels 设置 2560*28*28
| 图片尺寸(像素) | 尺寸(宽x高) | 平均执行时间(秒) |
|---|---|---|
| 256 | 384 x 256 | 3.69 |
| 512 | 768 x 512 | 4.42 |
| 768 | 1152 x 768 | 4.73 |
| 1024 | 1536 x 1024 | 5.83 |
| 1280 | 1920 x 1280 | 6.12 |
| 2560 | 3840 x 2560 | 6.28 |
max_pixels 设置 1024*28*28
| 图片尺寸(像素) | 尺寸(宽x高) | 平均执行时间(秒) |
|---|---|---|
| 256 | 384 x 256 | 3.65 |
| 512 | 768 x 512 | 3.86 |
| 768 | 1152 x 768 | 4.75 |
| 1024 | 1536 x 1024 | 4.78 |
| 1280 | 1920 x 1280 | 4.55 |
| 2560 | 3840 x 2560 | 5.22 |
一些结论
显存占用
显存占用约为 60G,如下图所示:

版本信息
当前使用的版本为:
展开代码vllm 0.6.3.post1+cu124
Docker 镜像保存
我已经将该镜像推送到 Docker 仓库,您可以使用以下命令获取该镜像:
bash展开代码docker pull kevinchina/deeplearning:vllm-openai-0.6.3.post1-cuda124
优化推理速度
为了提升推理速度,可以修改 preprocessor_config.json 文件中的参数。具体步骤如下:
bash展开代码# 编辑 preprocessor_config.json 文件
vim /path/to/Qwen2-VL-72B-Instruct-GPTQ-Int4/preprocessor_config.json
原始配置文件内容:
json展开代码{
"do_convert_rgb": true,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_processor_type": "Qwen2VLImageProcessor",
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"max_pixels": 802816,
"merge_size": 2,
"min_pixels": 3136,
"patch_size": 14,
"processor_class": "Qwen2VLProcessor",
"resample": 3,
"rescale_factor": 0.00392156862745098,
"size": {
"max_pixels": 1003520,
"min_pixels": 3136
},
"temporal_patch_size": 2,
"vision_token_id": 151654
}
参数优化建议:
max_pixels参数控制图像的最大尺寸。将其值修改为1024*28*28=802816可以显著提升推理速度,同时保证图像处理效果不受太大影响。
优化后,推理速度会有明显提升。
bash展开代码docker run --runtime nvidia --gpus device=0 \ -p 8006:8000 \ --ipc=host \ -v /root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4:/Qwen2-VL-Any \ vllm/vllm-openai:latest \ --model /Qwen2-VL-Any
现在Dockerfile 的最后一行是:
bash展开代码ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server"]
构建新的控制max_pixels镜像
您需要创建一个新的 Dockerfile,并添加自定义的入口脚本。
bash展开代码FROM kevinchina/deeplearning:vllm-openai-0.6.3.post1-cuda124
# 安装必要的依赖(如果需要)
# 例如,如果您的 Python 脚本需要额外的库,可以在这里安装
# RUN pip install --no-cache-dir <your-required-packages>
# 将自定义的入口脚本复制到镜像中
COPY entrypoint.sh /entrypoint.sh
# 赋予入口脚本可执行权限
RUN chmod +x /entrypoint.sh
EXPOSE 8000
# 设置容器启动时运行的入口脚本
ENTRYPOINT ["/entrypoint.sh"]
创建入口脚本 entrypoint.sh
set -e 是 Bash 脚本中的一个选项,用于控制脚本的执行行为。具体来说:
作用:当脚本中的任何一个命令以非零状态(即执行失败)退出时,set -e 会导致整个脚本立即退出,而不是继续执行后续的命令。
exec 是一个 Shell 内置命令,用于替换当前的 Shell 进程。具体来说:
作用:exec 后面的命令会取代当前的 Shell 进程,而不是在当前 Shell 中启动一个子进程来执行。这意味着执行 exec 后,原来的 Shell 不再存在,取而代之的是被 exec 执行的命令。 目的:
资源优化:减少进程数量,因为不需要额外的子进程。 信号传递:在 Docker 容器中,使用 exec 启动主应用程序(如 API 服务器)可以确保信号(如 SIGTERM)能够正确传递给该应用程序,便于容器的优雅关闭。
bash展开代码#!/bin/bash
set -e
# 设置默认值
DEFAULT_MAX_PIXELS=802816
# 获取环境变量中的 MAX_PIXELS,如果未设置则使用默认值
MAX_PIXELS=${MAX_PIXELS:-$DEFAULT_MAX_PIXELS}
# 配置文件路径
CONFIG_FILE=/Qwen2-VL-Any/preprocessor_config.json
# 检查配置文件是否存在
if [ ! -f "$CONFIG_FILE" ]; then
echo "配置文件 $CONFIG_FILE 不存在!"
exit 1
fi
# 使用 Python 修改配置文件中的 max_pixels 值
python3 - <<EOF
import json
config_path = "$CONFIG_FILE"
# 读取现有配置
with open(config_path, 'r') as f:
config = json.load(f)
# 修改 max_pixels 值
config['max_pixels'] = $MAX_PIXELS
# 写回配置文件
with open(config_path, 'w') as f:
json.dump(config, f, indent=4)
# 打印最终使用的值
print(f"使用的 max_pixels 值: {config['max_pixels']}")
EOF
# 启动 API 服务器
exec python3 -m vllm.entrypoints.openai.api_server --model /Qwen2-VL-Any
构建自定义 Docker 镜像
bash展开代码docker build -t kevinchina/deeplearning:vllm-openai-0.6.3.post1-cuda124-api .
运行 Docker 容器
bash展开代码docker run -d --runtime nvidia --gpus device=0 \ -p 8006:8000 \ --ipc=host \ -v /root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4:/Qwen2-VL-Any \ -e MAX_PIXELS=802816 \ kevinchina/deeplearning:vllm-openai-0.6.3.post1-cuda124-api
调试:如果在运行容器时遇到问题,可以使用以下命令启动容器并进入交互式 shell 以进行调试:
bash展开代码docker run --runtime nvidia --gpus device=0 \ -p 8006:8000 \ --ipc=host \ -v /root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4:/Qwen2-VL-Any \ -it --entrypoint /bin/bash \ vllm-custom:latest
push
bash展开代码docker push kevinchina/deeplearning:vllm-openai-0.6.3.post1-cuda124-api


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!