CFG Scale(Classifier-Free Guidance Scale)是如何控制文生图的
CFG Scale(Classifier-Free Guidance Scale,无分类器指导缩放)是Stable Diffusion中的一个关键参数,它控制生成图像在遵循文本提示的严格程度。
Stable Diffusion WebUI 噪声采样的调度器的原理
噪声调度器(Noise Schedulers)是扩散模型生成过程中的关键组件,它们决定了扩散过程中噪声水平如何随时间变化。合适的噪声调度可以显著提高生成质量和效率。我将详细解析 SD WebUI 中的各种调度器,包括其数学原理和具体实现。
Stable Diffusion 采样器的数学原理
Stable Diffusion 采样器是扩散模型去噪过程的核心组件,不同采样器采用不同的数学方法来逐步将纯噪声转换为有意义的图像。下面我将详细介绍几种主要采样器的工作原理、数学公式和代码实现。
Read file: modules/processing.py
Read file: modules/sd_samplers.py
Read file: modules/sd_samplers_kdiffusion.py
StableDiffusionProcessingTxt2Img: 文本到图像生成过程详解
StableDiffusionProcessingTxt2Img 是 stable-diffusion-webui 中实现文本到图像生成的核心类。整个生成过程是一个复杂的管道,下面我将分步骤详细解析这个过程。
使用ControlNet的Recolor模型为黑白图片上色
本文的代码: https://github.com/xxddccaa/stable-diffusion-webui-contorlnet-recolor
1. Recolor Control-LoRA简介
用途:专为黑白照片上色设计的轻量化模型
核心特点:
• 老照片修复/历史影像彩色化的理想选择
• 基于ControlNet架构,采用LoRA(低秩适应)技术实现模型瘦身:
• 原版ControlNet:4.7GB → Control-LoRA:仅738MB/377MB
• 训练时覆盖多样化图像概念和比例,具备优秀泛化能力
技术文档:HuggingFace项目页
展开代码apt update apt-get install libglib2.0-0 -y
要做什么
全量微调Qwen2.5-VL-7B-Instruct的参数,用于图片转公式LaTex。
模型地址:https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct
数据集
数据集:https://modelscope.cn/datasets/AI-ModelScope/LaTeX_OCR/summary
数据集下载,约有1.1G大小数据:
bash展开代码modelscope download --dataset AI-ModelScope/LaTeX_OCR --local_dir AI-ModelScope/LaTeX_OCR
该Python脚本用于处理/ssd/xiedong/vlm-r1-train-tasks-json-ui-docto/tasks_json目录下的数据,将其中所有图片等比例缩小(最长边为1024像素),并连同JSON文件一起复制到新目录/ssd/xiedong/vlm-r1-train-tasks-json-ui-docto/tasks_json_small_size中。
功能说明
- 遍历源目录下所有子文件夹(如"200932"等)
- 处理每个子文件夹中的所有.jpg图片文件,等比例缩放至最长边为1024像素
- 同时复制所有step_*.json文件到对应目录
- 使用Python多进程技术并行处理,大幅提高处理速度
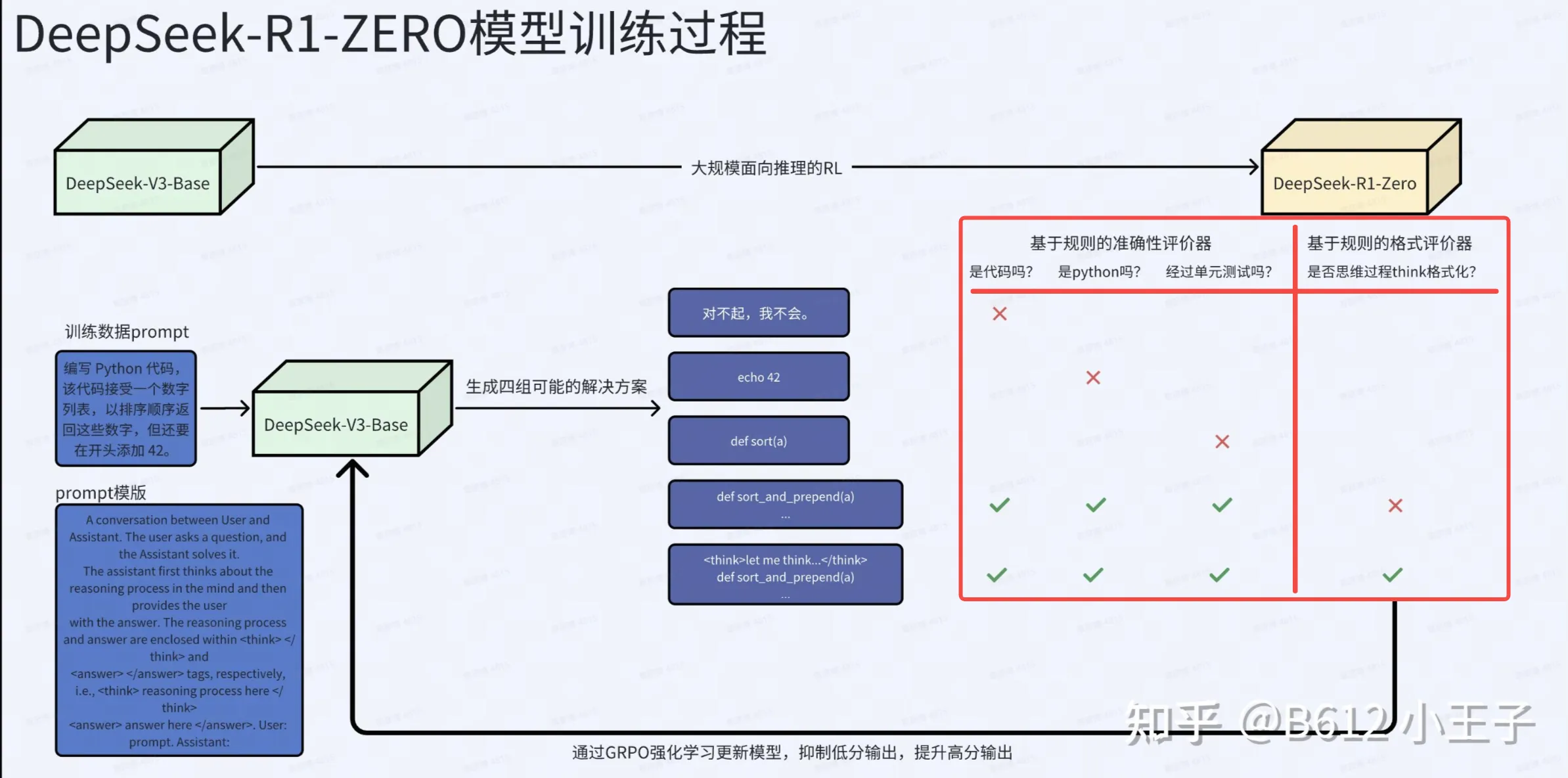
一篇很好的DeepSeek R1 解读: https://zhuanlan.zhihu.com/p/20844750193
DeepSeek R1 论文: https://arxiv.org/abs/2501.12948
如何从DeepSeek-V3-Base得到DeepSeek-R1-Zero,可以看下面这图。编写一个指导性的提示词,让DeepSeek-V3-Base输出一组回答,用奖励模型进行奖励RL训练,这样就可以训练出DeepSeek-R1-Zero。