Transformer模型中的位置编码
Transformer模型中的位置编码(Positional Encoding)用于为模型提供序列中单词的位置信息,因为Transformer本身是一个无序列的模型,它并不像RNN那样具有顺序处理的能力。
位置编码的公式通常分为两种形式:正弦和余弦函数,具体形式如下:
WO、AWQ、GPTQ 与 SQ 的对比
随着深度学习模型规模的不断扩大,模型的部署和推理变得更加昂贵。量化技术通过降低模型的计算精度(如从浮点数到整数)显著减少模型的存储需求和计算复杂度,是优化大模型的重要手段。目前有多种量化方法被提出,它们各自有针对性的特点和适用场景。本文将介绍以下四种主流量化技术及其差异:
- WO:仅权重量化(Weight Only Quantization)
- AWQ:激活感知权重量化(Activation-aware Weight Quantization)
- GPTQ:生成预训练 Transformer 量化(Generative Pretrained Transformer Quantization)
- SQ:平滑量化(Smooth Quantization)
https://arxiv.org/abs/2308.02223
ESRL: Efficient Sampling-based Reinforcement Learning for Sequence Generation
论文的核心贡献主要包括两方面:
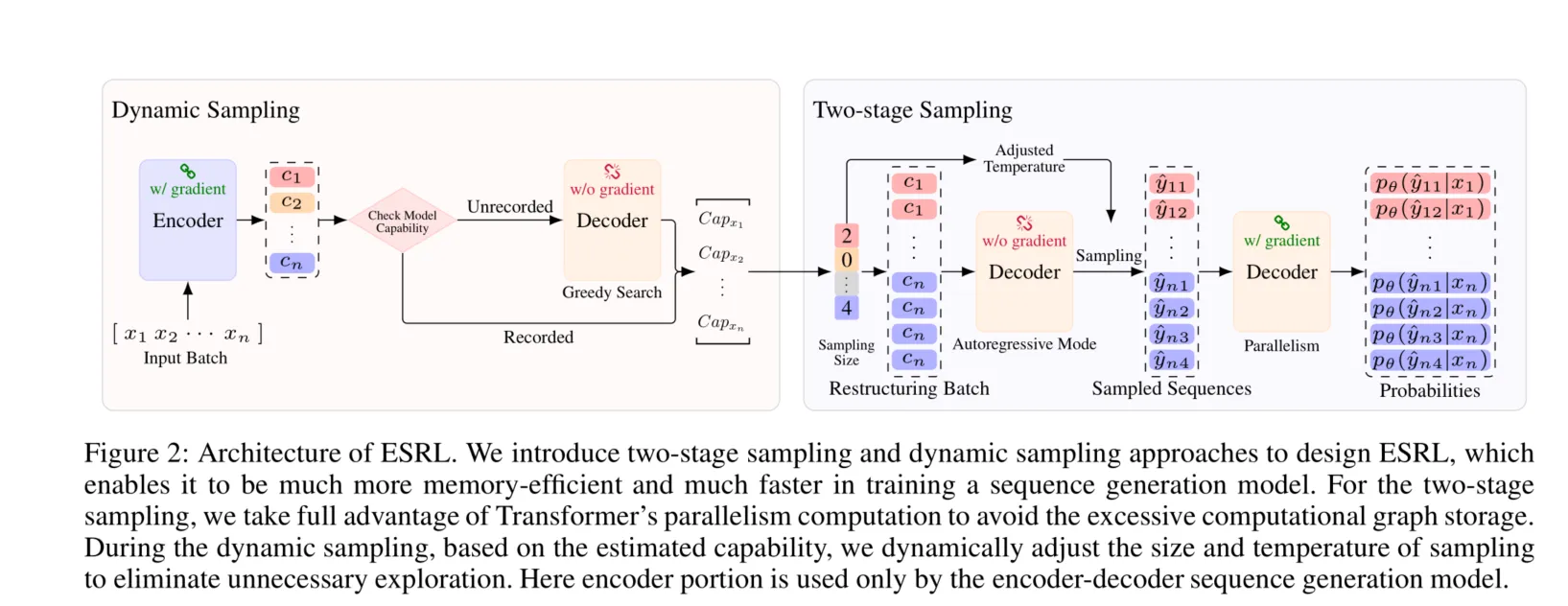
两阶段采样:传统的RL训练在序列生成任务中通常需要为每个生成的候选序列存储计算图,而这会消耗大量内存。为了优化这一点,ESRL采用了两阶段采样方法:在第一阶段,模型采用自回归方式生成候选序列,但不进行反向传播,避免了计算图的存储。第二阶段是计算这些候选序列的概率,利用Transformer的并行计算能力减少了计算图存储的需求。尽管增加了计算时间,但减少了内存消耗。
动态采样:ESRL还引入了动态采样机制,通过估计模型的能力(例如使用BLEU或熵值等度量)来调整采样的大小和温度。具体来说,当模型的能力较强时,减少采样数量;而当能力较弱时,增加采样量以提高探索效果。通过这种方法,ESRL避免了过度采样,从而进一步提高了训练效率。
一切都在此图中,以往模型的采样没有技巧,花费显存和时间,ESRL让这个过程变得高效:
https://arxiv.org/abs/2411.10323
摘要
最近发布的Claude 3.5计算机使用模型脱颖而出,成为首个在公开测试版中提供计算机使用功能的图形用户界面(GUI)代理。作为一个早期测试版,其在复杂的现实环境中的能力仍然未知。在这项探索Claude 3.5计算机使用的案例研究中,我们精心设计并组织了一系列跨越多个领域和软件的任务。通过这些案例的观察,我们展示了Claude 3.5计算机使用在从语言到桌面操作的端到端能力上的前所未有的表现。与此同时,我们还提供了一个开箱即用的代理框架,方便用户部署基于API的GUI自动化模型并轻松实现。本案例研究旨在展示Claude 3.5计算机使用的能力和局限性的基础工作,并通过详细的分析提出关于规划、行动和批判的问题,这些问题必须考虑在内以推动未来的改进。我们希望这项初步探索能激发未来在GUI代理领域的研究。本文中的所有测试案例可以通过以下项目进行尝试:https://github.com/showlab/computer_use_ootb 。
个人总结
LLaVA-o1把问题的回答拆解为这四个阶段:
- 总结阶段:简要概述问题和任务
- 描述阶段:详细描述图像中的相关部分
- 推理阶段:系统化地分析问题并进行推理
- 结论阶段:给出最终答案
https://arxiv.org/html/2406.12793v1
ChatGPT和GLM系列模型的发展
ChatGPT展现了卓越的能力,其最初在2022年11月由GPT-3.5模型[25]驱动,后来在2023年3月升级为GPT-4[27]。根据OpenAI的说法,GPT-3.5系列通过整合指令调优、监督微调(SFT)和/或来自人类反馈的强化学习(RLHF)[28],在GPT-3的基础上进行了改进。最初的GPT-3在2020年发布[3],标志着从GPT-1的1.17亿参数和GPT-2的15亿参数大幅提升至1750亿参数。这种规模的提升使GPT-3具备了上下文学习和通用能力,推动了大型语言模型(LLMs)的出现[6; 41]。
https://arxiv.org/abs/2310.11441
SoM(Set-of-Mark)提示是一种新的提示机制,具体来说,就是在图像的不同区域上添加一组视觉标记。通过在输入图像上覆盖数字、字母、掩码或框等各种格式的标记,SoM帮助模型更好地理解和定位图像中的语义上有意义的区域。这样做的目的是增强模型在视觉内容上的定位能力,使其能够更准确地将答案与相应的图像区域关联起来。
也就是改了图的。
