Moshi 结合了一个大规模文本 LLM(Helium)和一个小型音频语言模型,实现了语音到语音的直接理解和生成。通过分层流式架构和多流音频处理,模型首次实现了全双工对话能力(可以在边输出对话的时候,同时还在监听说话人说话,可以做到打断)。
https://arxiv.org/abs/2402.05755
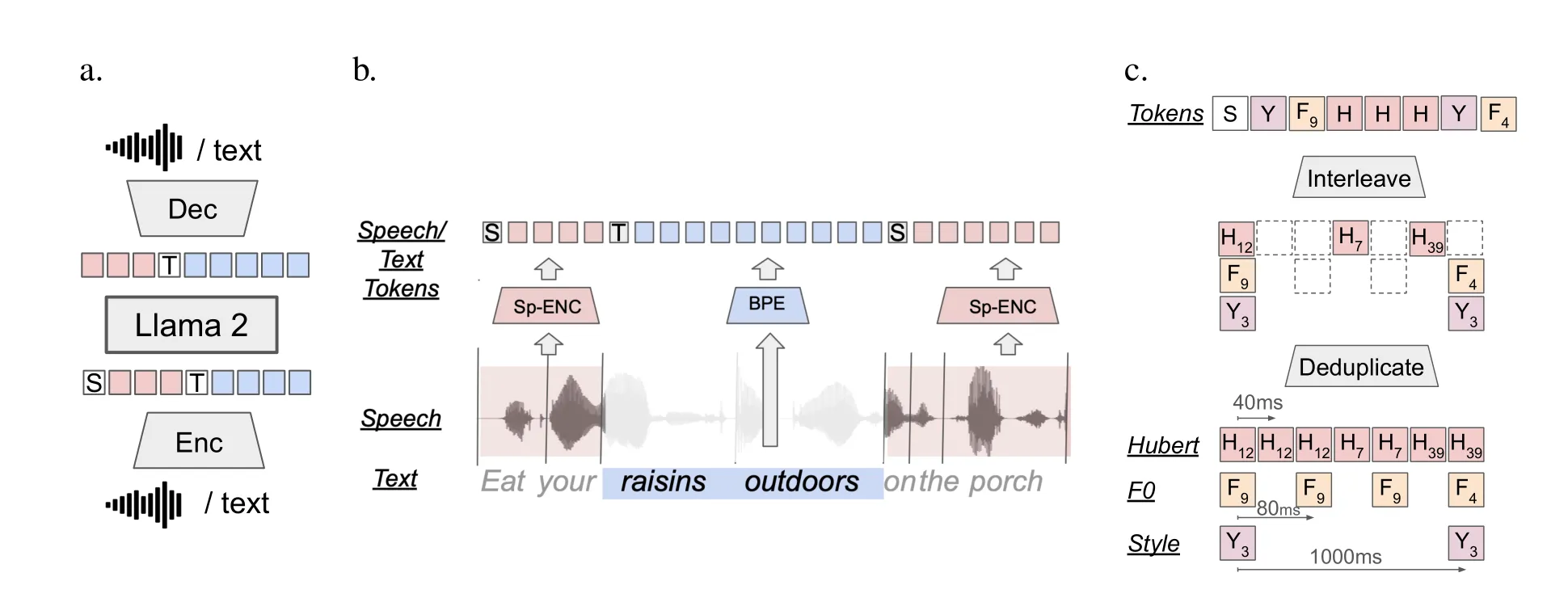
图1:
a. SPIRIT LM架构。一个通过下一个词预测训练的语言模型;令牌通过编码器从语音或文本中提取,并通过解码器以原始模态恢复。SPIRIT LM模型在文本-only序列、语音-only序列和交替语音-文本序列的混合数据上进行训练。
b. 语音-文本交替方案。语音通过聚类语音单元(Hubert、Pitch或Style令牌)被编码为令牌(粉色),文本通过BPE编码为令牌(蓝色)。我们使用特殊令牌[T EXT]为文本加前缀,使用[S PEECH]为语音令牌。在训练过程中,模态变化在对齐的语音-文本语料库中的单词边界处随机触发。语音令牌去重后,在模态变化边界处与文本令牌交替。
c. 富表现语音令牌。对于SPIRIT LM EXPRESSIVE,音高令牌和风格令牌在去重后交替排列。
贡献包括以下几点:
(i) 我们提出了 SPIRIT LM,这是一种单一的语言模型,能够生成语音和文本。SPIRIT LM 基于持续预训练的 LLaMA 2,并通过交替的语音和文本数据进行训练。
(ii) 类似于文本 LLM,我们发现 SPIRIT LM 可以在文本、语音和跨模态设置(即语音到文本和文本到语音)中通过少样本学习新任务。
(iii) 为了评估生成模型的表现力,我们引入了语音-文本情感保留基准(SPIRIT-TEXT SENTIMENT PRESERVATION,简称 STSP),该基准衡量生成模型在语音和文本的同模态和跨模态条件下,保持情感的一致性。
(iv) 我们提出了 SPIRIT LM 的表现力版本(SPIRIT LM EXPRESSIVE)。通过 STSP,我们展示了 SPIRIT LM 是首个能够在文本和语音提示的同模态与跨模态之间保持情感一致性的语言模型。
(v) 最后,我们量化了模型在生成过程中可能增加的有害内容,无论是在语音还是文本中。如同所有预训练基础模型(Bender 等,2021;Solaiman 等,2023),SPIRIT LM 也可能生成有害内容。因此,所有使用我们工作的面向用户的应用程序应当整合必要的安全性测试,并进行安全指令微调以满足安全标准(Touvron 等,2023b)。
运行以下命令安装 Docker Compose:
bash展开代码sudo curl -L "https://github.com/docker/compose/releases/download/v2.22.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
docker-compose.yml 写到:
bash展开代码wget https://github.com/milvus-io/milvus/releases/download/v2.3.1/milvus-standalone-docker-compose.yml -O docker-compose.yaml
使用 Docker 部署 MySQL 数据库
随着 Docker 技术的广泛应用,使用容器化技术来管理数据库变得更加简单和高效。MySQL 是最流行的关系型数据库管理系统之一,通过 Docker 部署 MySQL 能够为开发人员提供便捷的环境部署和管理方式。在本文中,我们将介绍如何通过 Docker 来部署 MySQL 数据库。
看到一个资料:
https://github.com/QwenLM/Qwen2.5/blob/main/docs/source/framework/LlamaIndex.rst
微调模型的时候有加一些标记,所以后面用的时候给入标记会是一种很强的监督:
bash展开代码from sentence_transformers import SentenceTransformer
model = SentenceTransformer("/data/xiedong/Conan-embedding-v1")
sentences = [
"今天天气真好。",
"外面的阳光真灿烂!",
"他开车去了体育馆。",
"The weather is really nice today."
]
embeddings = model.encode(sentences)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
print(similarities.shape)
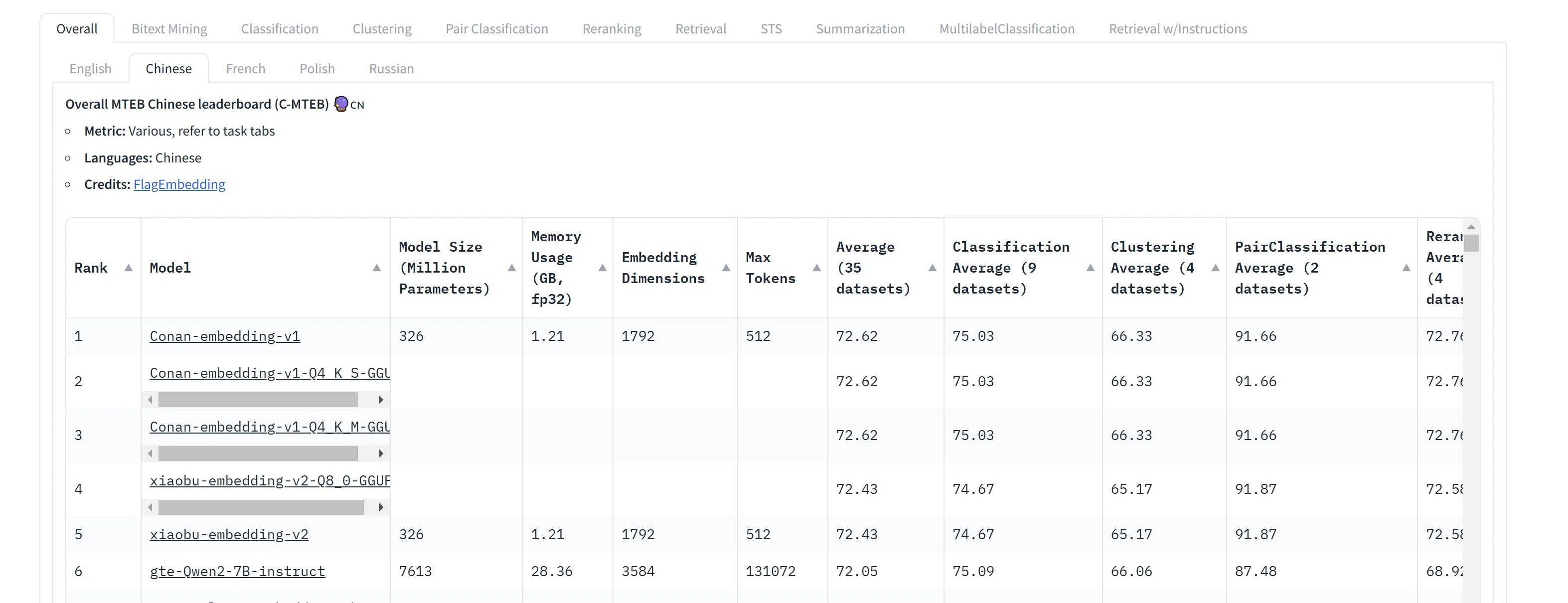
个人总结
预训练阶段用对比学习,清洗后的数据用于预训练。题目-内容文本对、输入-输出文本对、问题-答案文本对、提示-响应文本对,都是训练数据。
动态困难负样本挖掘:训练过程中,困难样本会不断改变,重新挖掘。
跨GPU批次平衡损失:以往都是不同embedding任务交替训练,认为这样会震荡,直接多个任务一起BP。
摘要
随着RAG(检索增强生成)技术的日益流行,嵌入模型的能力也引起了越来越多的关注。嵌入模型通常通过对比学习进行训练,其中负样本是关键组成部分。以往的研究提出了多种困难负样本挖掘策略,但这些策略通常作为预处理步骤来应用。在本文中,我们提出了conan-embedding模型,旨在最大化利用更多、更高质量的负样本。具体来说,由于模型处理预处理负样本的能力会随着训练的进行而演变,我们提出了动态困难负样本挖掘方法,旨在使模型在训练过程中暴露于更多具有挑战性的负样本。其次,对比学习需要尽可能多的负样本,但由于GPU内存的限制,这一需求受到了制约。因此,我们使用跨GPU平衡损失(Cross-GPU balancing Loss)来提供更多的负样本进行嵌入训练,并平衡多个任务的批量大小。此外,我们还发现来自大型语言模型(LLM)的提示-响应对(prompt-response pairs)可以用于嵌入训练。我们的方法有效提升了嵌入模型的能力,目前在中文大规模文本嵌入基准(MTEB)排行榜上排名第一。