Moshi 结合了一个大规模文本 LLM(Helium)和一个小型音频语言模型,实现了语音到语音的直接理解和生成。通过分层流式架构和多流音频处理,模型首次实现了全双工对话能力(可以在边输出对话的时候,同时还在监听说话人说话,可以做到打断)。
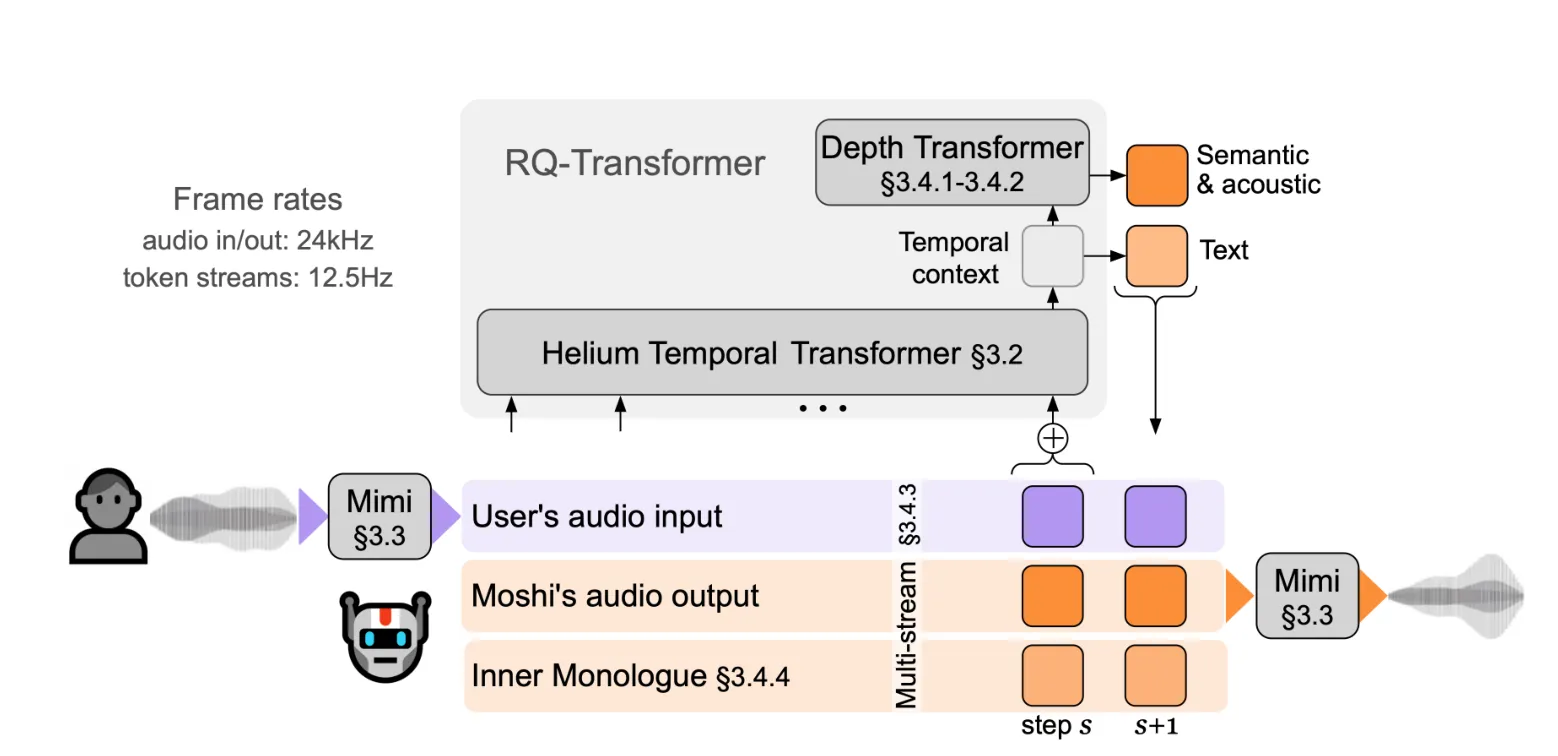
Moshi 是一款多流式语音到语音的 Transformer 模型,凭借其创新的架构(如图 1 所示),能够实现与用户的全双工语音对话。
Moshi 构建于 Helium 之上,Helium 是一款我们从零开始构建的文本大语言模型(见第 3.2 节),通过依赖高质量的文本数据来为模型提供强大的推理能力。
我们还提出了 Inner Monologue(见第 3.4.4 节),一种训练和推理过程,在此过程中,我们将文本和音频标记联合建模。这使得模型能够充分利用文本模态所传递的知识,同时保持语音到语音的系统特性。
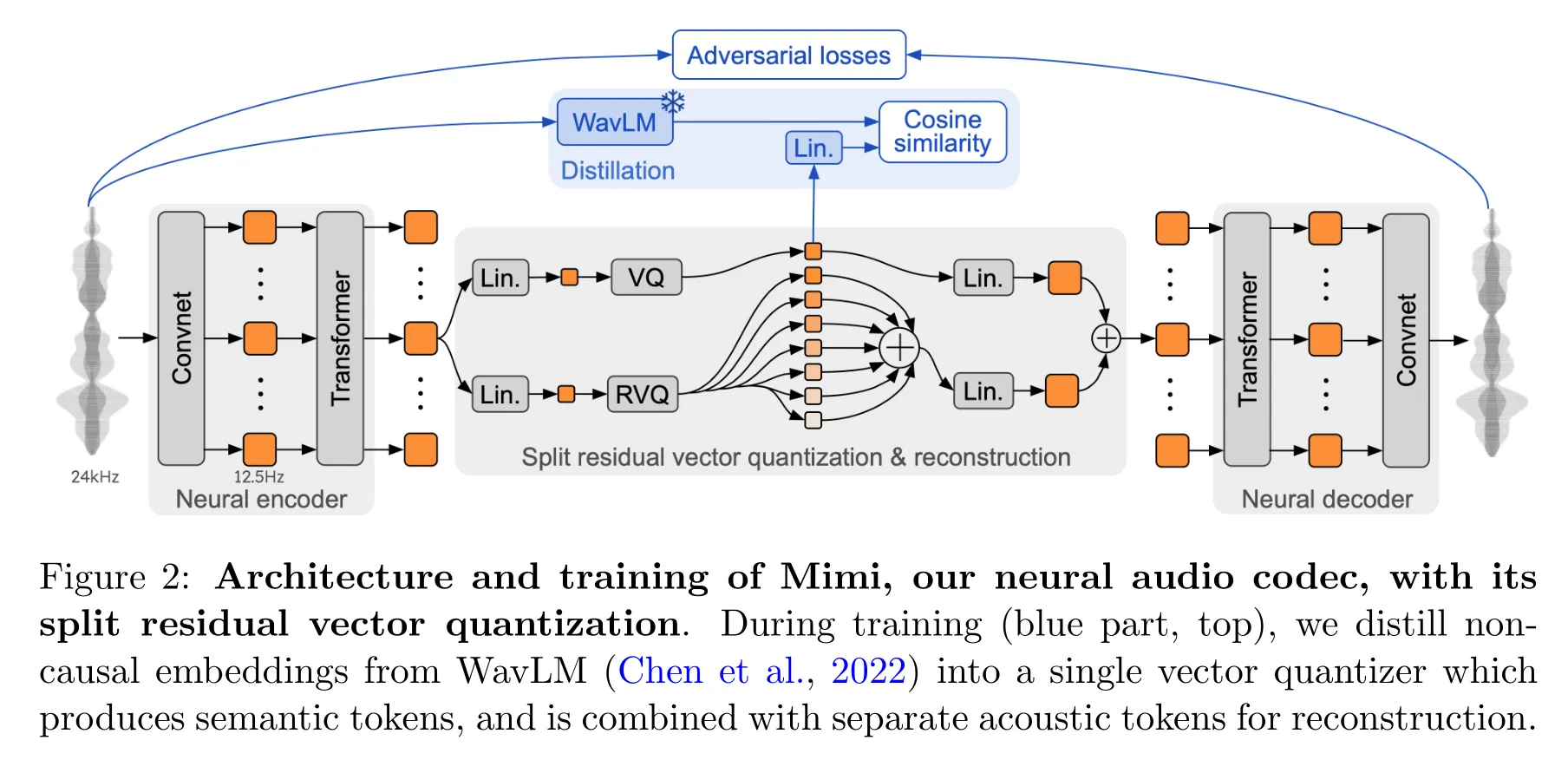
为了实现实时对话,我们从一开始就将 Moshi 设计为多流架构(见第 3.4.3 节):该模型能够同时与用户讲话和倾听,不需要显式地建模说话者轮次。此外,为了以高质量和高效的方式捕捉输入的用户音频并输出 Moshi 的语音,我们提出了 Mimi(见第 3.3 节),一种神经音频编解码器,它通过使用残差向量量化和知识蒸馏,将语义和声学信息结合成一个单一的标记器。为了联合建模来自 Moshi 和用户的音频流以及 Moshi 的文本标记,我们依赖于兼容流式推理的 Depth Transformer(见第 3.4.1 和 3.4.2 节)。
Mimi模型架构图如下,是一个编解码模型,用对抗损失+潜空间的余弦损失。潜空间的离散声学标记会被用到Helium模型里去,也会被用于后期的音频解码器里生成音频。
技术报告太长了,全是自己做的模型,昂贵的数据,昂贵的模型。
用户输入语音,这一套下来,因为存在内部的Helium去自省,输出将会有条有理。而Mimi解码后的音频就可以给人听了。输入语音,输出也是语音。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!