https://arxiv.org/abs/2402.05755
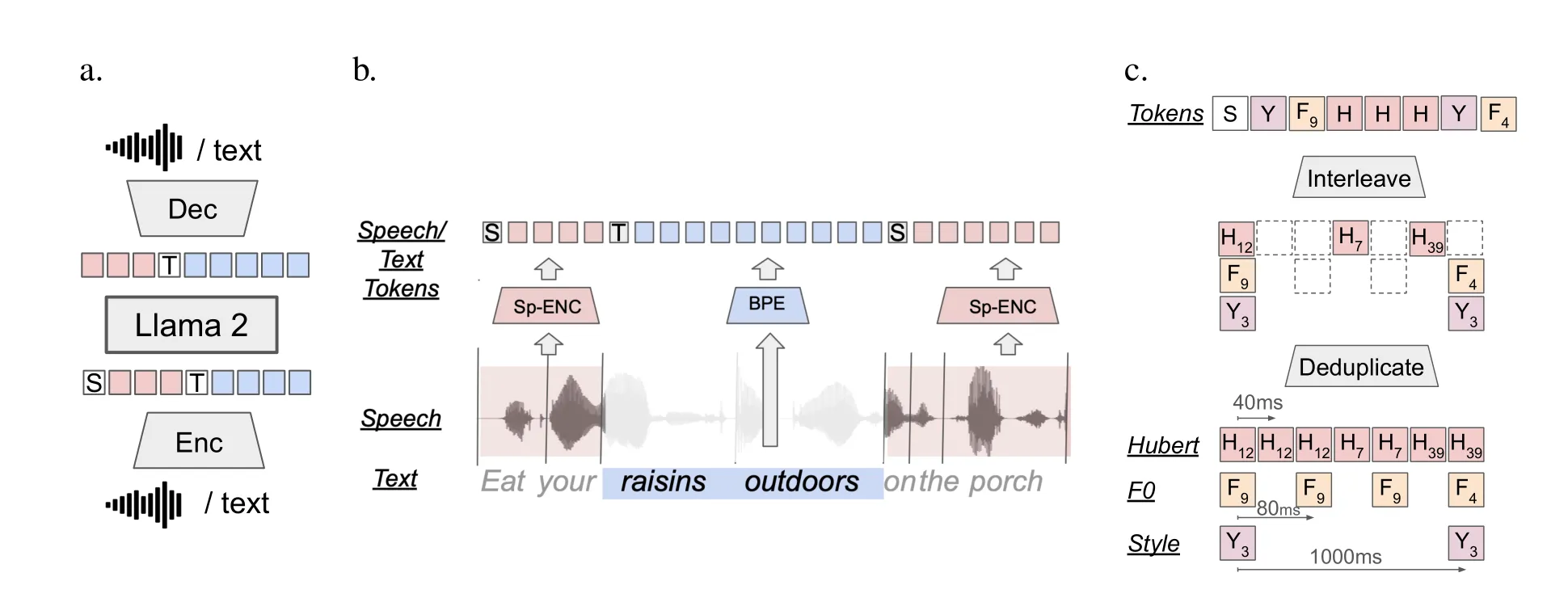
图1:
a. SPIRIT LM架构。一个通过下一个词预测训练的语言模型;令牌通过编码器从语音或文本中提取,并通过解码器以原始模态恢复。SPIRIT LM模型在文本-only序列、语音-only序列和交替语音-文本序列的混合数据上进行训练。
b. 语音-文本交替方案。语音通过聚类语音单元(Hubert、Pitch或Style令牌)被编码为令牌(粉色),文本通过BPE编码为令牌(蓝色)。我们使用特殊令牌[T EXT]为文本加前缀,使用[S PEECH]为语音令牌。在训练过程中,模态变化在对齐的语音-文本语料库中的单词边界处随机触发。语音令牌去重后,在模态变化边界处与文本令牌交替。
c. 富表现语音令牌。对于SPIRIT LM EXPRESSIVE,音高令牌和风格令牌在去重后交替排列。
贡献包括以下几点:
(i) 我们提出了 SPIRIT LM,这是一种单一的语言模型,能够生成语音和文本。SPIRIT LM 基于持续预训练的 LLaMA 2,并通过交替的语音和文本数据进行训练。
(ii) 类似于文本 LLM,我们发现 SPIRIT LM 可以在文本、语音和跨模态设置(即语音到文本和文本到语音)中通过少样本学习新任务。
(iii) 为了评估生成模型的表现力,我们引入了语音-文本情感保留基准(SPIRIT-TEXT SENTIMENT PRESERVATION,简称 STSP),该基准衡量生成模型在语音和文本的同模态和跨模态条件下,保持情感的一致性。
(iv) 我们提出了 SPIRIT LM 的表现力版本(SPIRIT LM EXPRESSIVE)。通过 STSP,我们展示了 SPIRIT LM 是首个能够在文本和语音提示的同模态与跨模态之间保持情感一致性的语言模型。
(v) 最后,我们量化了模型在生成过程中可能增加的有害内容,无论是在语音还是文本中。如同所有预训练基础模型(Bender 等,2021;Solaiman 等,2023),SPIRIT LM 也可能生成有害内容。因此,所有使用我们工作的面向用户的应用程序应当整合必要的安全性测试,并进行安全指令微调以满足安全标准(Touvron 等,2023b)。
论文:https://arxiv.org/abs/2402.05755 代码:https://github.com/facebookresearch/spiritlm
SPIRIT LM 是一种能够自由混合文本和语音的基础多模态语言模型。它基于 70 亿(7B)参数的预训练文本语言模型,通过持续训练使其扩展到语音模态。语音和文本序列被连接成一个单一的标记流,并使用一个小型自动整理的语音-文本平行语料库,采用词级交错方法进行训练。
下图中:
图中a部分:使用 70 亿参数的预训练文本语言模型 LLAMA 2 作为基础模型。扩展 LLAMA 2 的词嵌入空间,以包含新的语音标记和模态标记。这也正是SPIRIT LM 模型的架构,输入的可以是语音+文本,输出的也可以是语音+文本。
图中b部分:展示了SPIRIT LM 的语音-文本交替方案。语音通过聚类语音单元(Hubert、音调或风格标记)编码为标记(粉色),文本通过BPE编码为标记(蓝色)。我们使用特殊标记[T EXT]作为文本的前缀,[S PEECH]作为语音标记。在训练过程中,在对齐的语音-文本语料库中的单词边界处随机触发模态变化。语音标记在去重后与文本标记交替,并在模态变化的边界处插入。那把BPE是分词算法,可理解为tokenizer。
图中c部分:展示了SPIRIT LM EXPRESSIVE模型(在SPIRIT LM 基础之上增加表现力语音标记)的表达性建模。对于SPIRIT LM EXPRESSIVE,音调标记和风格标记在去重后交替排列。
HuBERT模型提取因素
VQ-VAE 模型提取音调
k-means 聚类模型提取风格标记
下图展示了SPIRIT LM的一些推理数据:
论文里的SPIRIT LM模型类似于Qwen2.5等一些大语言模型(LLM)的基础模型,其主要训练任务是通过语句补全来使模型学习文本与语音之间的对齐关系。

数据准备:
- 文本数据: 从 LLaMA 训练数据集中选择与语音相关的文本数据,总规模约为 3000 亿个文本标记。
- 语音数据: 使用开源的大型语音数据集,总时长约为 460K 小时,转换为 300 亿个语音标记(HuBERT)。
- 语音-文本平行数据: 使用带有文本转录的语音数据集,并进行词级对齐,总时长约为 110K 小时,转换为 70 亿个语音标记(HuBERT)和 15 亿个文本标记。
数据采样:
- 为了确保模型在训练过程中能够均匀地看到语音、文本和语音-文本平行数据,需要对不同类型的数据进行采样权重调整。
- 随机选择文本序列和语音序列的长度,以平衡语音标记和文本标记在输入序列中的比例。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!