目录
个人总结
预训练阶段用对比学习,清洗后的数据用于预训练。题目-内容文本对、输入-输出文本对、问题-答案文本对、提示-响应文本对,都是训练数据。
动态困难负样本挖掘:训练过程中,困难样本会不断改变,重新挖掘。
跨GPU批次平衡损失:以往都是不同embedding任务交替训练,认为这样会震荡,直接多个任务一起BP。
摘要
随着RAG(检索增强生成)技术的日益流行,嵌入模型的能力也引起了越来越多的关注。嵌入模型通常通过对比学习进行训练,其中负样本是关键组成部分。以往的研究提出了多种困难负样本挖掘策略,但这些策略通常作为预处理步骤来应用。在本文中,我们提出了conan-embedding模型,旨在最大化利用更多、更高质量的负样本。具体来说,由于模型处理预处理负样本的能力会随着训练的进行而演变,我们提出了动态困难负样本挖掘方法,旨在使模型在训练过程中暴露于更多具有挑战性的负样本。其次,对比学习需要尽可能多的负样本,但由于GPU内存的限制,这一需求受到了制约。因此,我们使用跨GPU平衡损失(Cross-GPU balancing Loss)来提供更多的负样本进行嵌入训练,并平衡多个任务的批量大小。此外,我们还发现来自大型语言模型(LLM)的提示-响应对(prompt-response pairs)可以用于嵌入训练。我们的方法有效提升了嵌入模型的能力,目前在中文大规模文本嵌入基准(MTEB)排行榜上排名第一。
1 引言
随着自然语言处理技术的快速发展,嵌入模型(Su 等, 2022;Xiao 等, 2023;Wang 等, 2023)在文本表示、信息检索和生成任务中发挥了关键作用。嵌入模型将单词、句子或文档映射到高维连续空间中,使得相似文本具有更接近的向量表示。这种表示不仅增强了文本数据的可操作性,还显著提高了各种下游任务的性能。特别是在检索增强生成(RAG)技术中,嵌入模型的能力直接影响生成结果的质量。
尽管嵌入模型取得了显著进展,但现有方法在负样本选择方面仍存在不足。通常,嵌入模型通过对比学习进行训练,而负样本的质量对模型性能至关重要。先前的研究(Wang 等, 2022;Moreira 等, 2024)提出了各种困难负样本挖掘策略,在一定程度上提高了模型性能。然而,这些策略大多作为预处理步骤使用,限制了模型在处理复杂多变的训练数据时的性能。
为了解决这些问题,本文提出了Conan-Embedding模型,最大化地利用更多和更高质量的负样本。具体来说,我们在训练过程中迭代挖掘困难负样本,使模型能够动态适应变化的训练数据。此外,我们引入了跨GPU平衡损失,以平衡多任务中的负样本数量,提高训练效率和效果。我们还发现,大型语言模型(LLMs)的提示响应对可以用作训练数据,进一步增强嵌入模型的性能。通过这些改进,我们的方法在中文大规模文本嵌入基准(CMTEB)排行榜上取得了第一名,展示了其出色的性能和广泛的应用前景。
2 方法
2.1 训练流程
2.1.1 预训练
参考Li 等(2023a),我们也采用了多阶段的训练方法。我们将训练分为预训练和微调阶段。如图1(a)所示,在预训练阶段,我们使用Cai 等(2024)描述的标准数据过滤方法。经过过滤后,我们使用bge-large-zh-v1.5模型(Xiao 等, 2023)进行评分,然后丢弃所有得分低于0.4的数据。为了高效、充分地利用预训练数据,我们使用带In-Batch Negative的InfoNCE损失进行训练:
表示正样本的查询,表示正样本的段落,表示同一批次中其他样本的段落,这些被视为负样本。
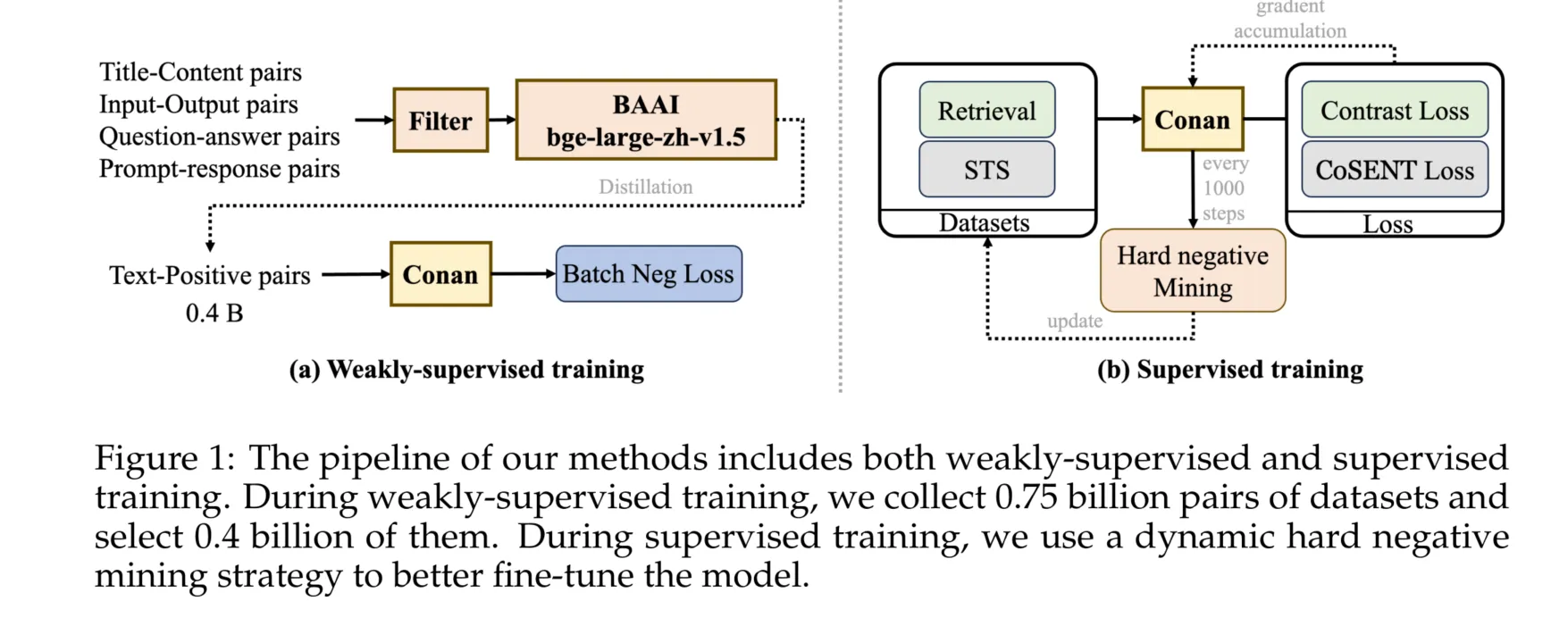
In-Batch Negative InfoNCE Loss(Gutmann 和 Hyvärinen, 2010)是一种用于对比学习的损失函数,它利用小批次中的其他样本作为负样本来优化模型。具体来说,在每个小批次中,目标样本的正对以外的所有样本都被视为负样本。通过最大化正对的相似性和最小化负对的相似性,In-Batch Negative InfoNCE Loss可以有效增强模型的判别能力和表示学习性能。该方法通过充分利用小批次中的样本,提高了训练效率,并减少了生成额外负样本的需求。
2.1.2 有监督微调
在有监督微调阶段,我们对不同的下游任务进行特定的任务微调。如图1(b)所示,我们将任务分为两类:检索和STS(语义文本相似性)。检索任务包括查询、正文本和负文本,经典的损失函数是InfoNCE损失。STS任务涉及区分两个文本之间的相似性,经典的损失函数是交叉熵损失。根据Su(2022)和其他研究(Wang Yuxin, 2023),CoSENT损失比交叉熵损失稍好。因此,我们也采用CoSENT损失来优化STS任务,其公式如下:
其中,是缩放温度,是余弦相似性函数,是和之间的相似性。
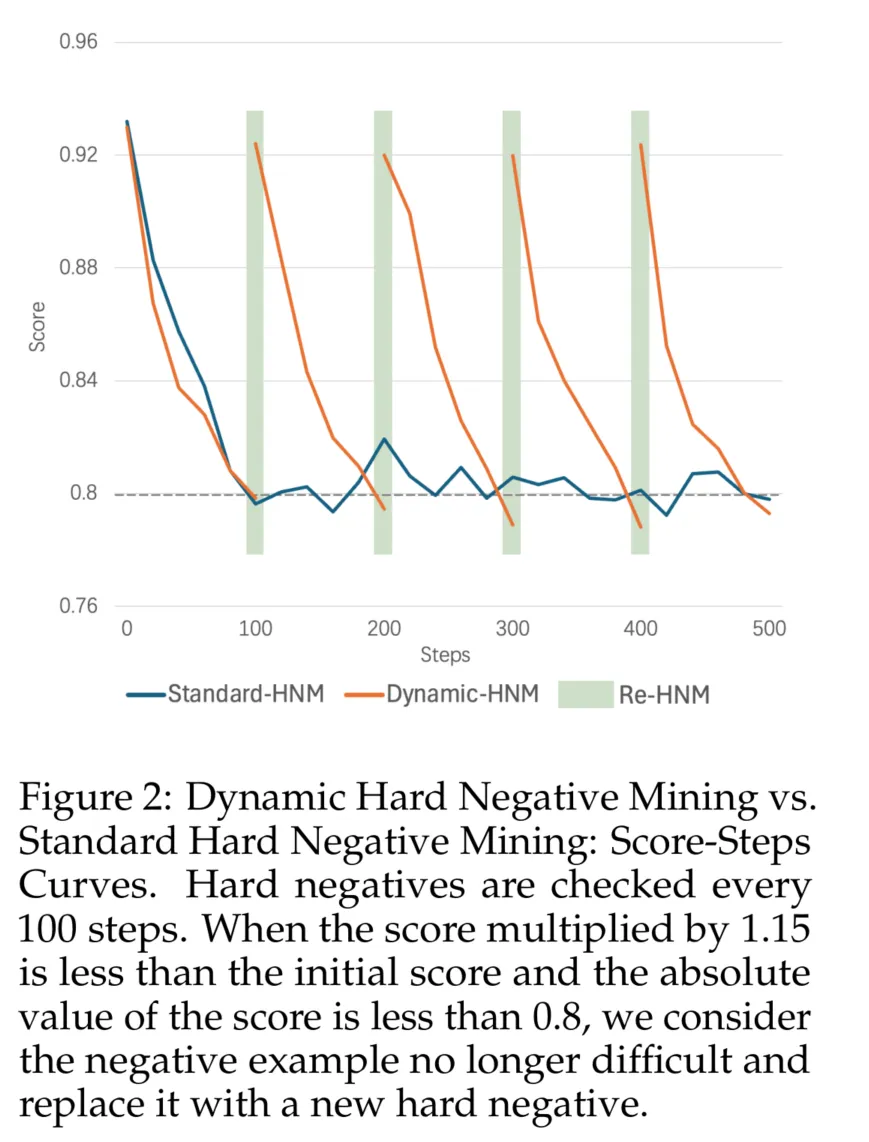
2.2 动态困难负样本挖掘
先前的工作主要集中在数据预处理阶段的困难负样本挖掘。对于具有给定权重的嵌入模型,困难负样本是固定的。然而,随着训练的进展和模型权重的更新,与当前权重对应的困难负样本会发生变化。在预处理阶段挖掘的困难负样本经过几次训练迭代后可能不再具有挑战性。
基于这一观点,我们提出了一种动态困难负样本挖掘方法。对于每个数据点,我们记录困难负样本相对于查询的当前平均得分。每100次迭代,如果得分乘以1.15小于初始得分且得分的绝对值小于0.8,我们认为该负样本不再困难,并进行新一轮的困难负样本挖掘。在每次动态困难负样本挖掘期间,如果需要替换困难负样本,我们使用到的案例作为负样本,其中表示第次替换,表示每次使用的困难负样本数量。整个过程的成本相当于一步迭代。
与In-Batch Negative InfoNCE Loss相比,我们认为更高质量的困难负样本(与当前模型权重更一致)更为重要。图2.2展示了动态困难负样本挖掘与标准困难负样本挖掘的正负样本得分-步数曲线。如图所示,随着步骤的增加,标准困难负样本挖掘中的负样本得分停止下降并开始振荡,这表明模型已经从该批负样本中学习完毕。相比之下,动态困难负样本挖掘在检测到负样本对模型不再具有挑战性时替换困难负样本。
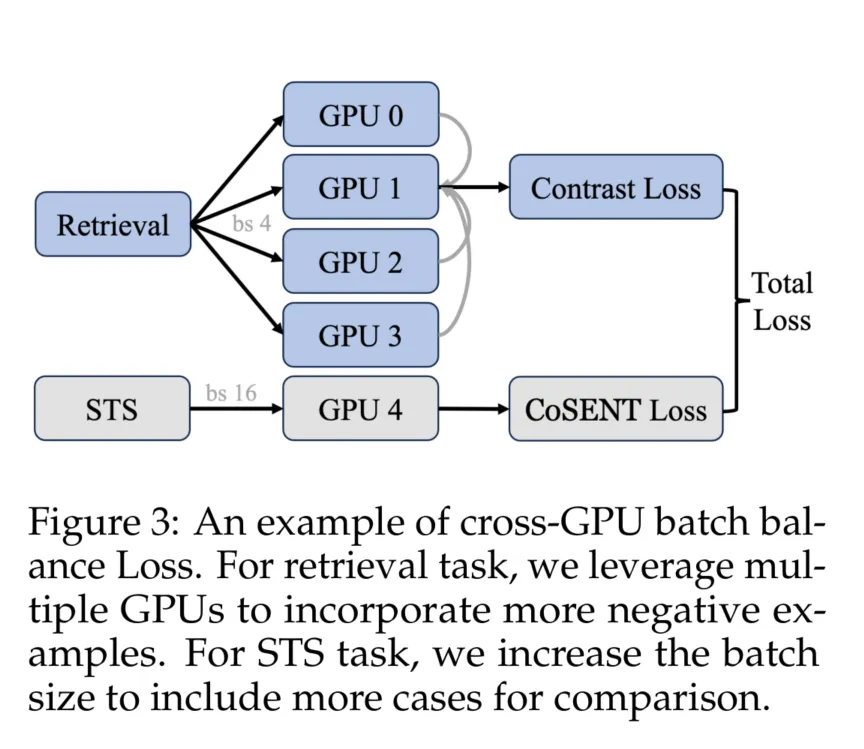
2.3 跨GPU批次平衡损失
为了更好地利用困难示例,我们采用了Cross-GPU Batch Balance Loss(CBB)。先前的方法(Li 等, 2023b)通常在训练过程中随机为每个批次分配一个任务。例如,在第0次迭代中,选择STS任务的样本,并使用相应的STS损失进行反向传播以获得梯度并更新权重。在第1次迭代中,可能会分配Retri任务。我们称之为顺序随机任务训练。这种训练往往导致单次迭代优化的搜索空间与嵌入模型的全局搜索空间之间不一致,从而导致训练过程中的振荡。这些振荡妨碍了模型收敛到全局最优,使得实现最佳性能更加困难。我们在第3.5节中展示了这一现象。
为了解决这个问题,我们考虑在每个Forward-Loss-Backward-Update周期中以平衡的方式引入每个任务,以获得稳定的搜索空间,并最小化单次模型更新方向与全局最优之间的差异。因此,CBB策略不仅考虑不同GPU之间的通信,还考虑不同任务之间的通信,实现更好的批次平衡。如图3所示,为了在检索任务中利用更多的困难示例,我们确保每个GPU(gpu0, gpu1, gpu2, gpu3)具有不同的负样本,同时共享相同的查询和正样本。对于Retri任务,每个GPU计算其对应批次的损失,并在gpu1上汇总结果。对于STS任务,gpu4运行STS任务并获得相应的损失。最后,汇总结果以计算当前迭代的组合CBB损失。相应的公式如下:
其中,是查询和正文本之间的评分函数,通常定义为余弦相似性,是共享查询和正文本的GPU数量,是缩放温度。我们将经验设置为0.8。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!