使用 /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc
bash展开代码
def draw_bbox_on_pil_image(pil_image, bbox, text, color, thickness=2, font_size=12):
"""在PIL图片上绘制bbox和文本"""
draw = ImageDraw.Draw(pil_image)
# 获取图片尺寸
img_width, img_height = pil_image.size
# 转换bbox格式 [x_br, y_br, x_tl, y_tl] -> [x1, y1, x2, y2]
x_br, y_br, x_tl, y_tl = bbox
# 将0-1000的归一化坐标转换为实际图片坐标
x_br = int(x_br * img_width / 1000)
y_br = int(y_br * img_height / 1000)
x_tl = int(x_tl * img_width / 1000)
y_tl = int(y_tl * img_height / 1000)
# 确保坐标顺序正确
x1 = min(x_tl, x_br)
y1 = min(y_tl, y_br)
x2 = max(x_tl, x_br)
y2 = max(y_tl, y_br)
# 绘制矩形框
draw.rectangle([x1, y1, x2, y2], outline=color, width=thickness)
# 绘制文本
try:
font = ImageFont.truetype("/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc", font_size)
except:
font = ImageFont.load_default()
# 获取文本尺寸
bbox_text = draw.textbbox((0, 0), text, font=font)
text_width = bbox_text[2] - bbox_text[0]
text_height = bbox_text[3] - bbox_text[1]
# 绘制文本背景
draw.rectangle([x1, y1 - text_height - 5, x1 + text_width + 10, y1],
fill=(255, 255, 255), outline=(0, 0, 0))
# 绘制文本
draw.text((x1 + 5, y1 - text_height - 2), text, fill=(0, 0, 0), font=font)
return pil_image
资料
官网ROS教程: https://wiki.ros.org/cn/ROS/Tutorials
中国大学MOOC---《机器人操作系统入门》课程讲义 https://sychaichangkun.gitbooks.io/ros-tutorial-icourse163/content/
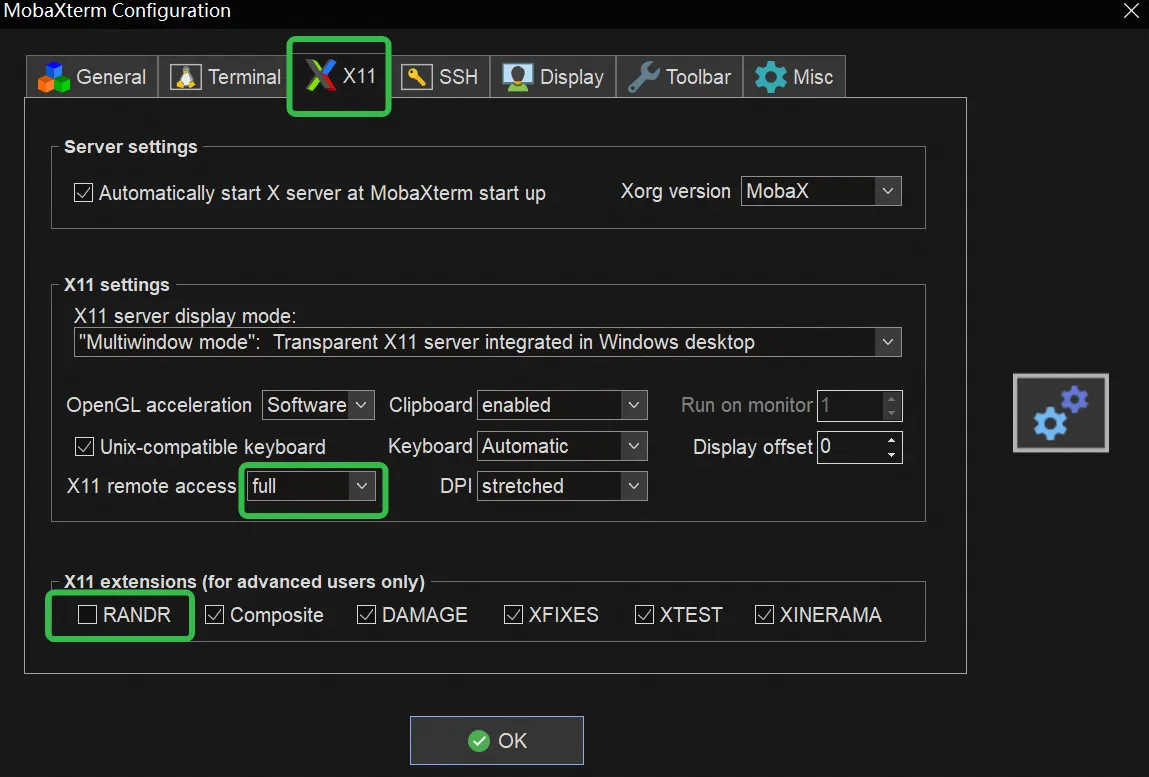
Cursor使用这样链接到容器里:
bash展开代码root@101.126.150.28 -p 8031
在wang电脑操作。
之前操作的容器commit为镜像:
bash展开代码docker commit 954fb79c1f14 kevinchina/deeplearning:ros-noetic-cuda11.4.2
该文章已加密,点击 阅读全文 并输入密码后方可查看。
python展开代码#!/usr/bin/env python3
import torch
import torch.nn as nn
import time
import threading
from datetime import datetime
def detect_gpus():
"""Detect available GPUs"""
if not torch.cuda.is_available():
print("CUDA is not available. No GPUs detected.")
return []
gpu_count = torch.cuda.device_count()
gpus = []
print(f"Detected {gpu_count} GPU(s):")
for i in range(gpu_count):
gpu_name = torch.cuda.get_device_name(i)
gpu_memory = torch.cuda.get_device_properties(i).total_memory / (1024**3) # GB
print(f" GPU {i}: {gpu_name} ({gpu_memory:.1f} GB)")
gpus.append(i)
return gpus
def gpu_worker(gpu_id, running):
"""Worker function for each GPU"""
device = torch.device(f'cuda:{gpu_id}')
try:
# Create large tensors to use GPU memory (about 60% of available memory)
gpu_memory = torch.cuda.get_device_properties(gpu_id).total_memory
target_memory = int(gpu_memory * 0.6) # Use 60% of GPU memory
elements_needed = target_memory // 4 # Each float32 is 4 bytes
# Create multiple large tensors
tensors = []
remaining = elements_needed
while remaining > 1000000: # At least 1M elements per tensor
size = min(remaining // 3, 5000000) # Max 5M elements per tensor
if size < 1000000:
break
tensor = torch.randn(size, device=device, requires_grad=True)
tensors.append(tensor)
remaining -= size
# Create a simple neural network
model = nn.Sequential(
nn.Linear(1000, 2000),
nn.ReLU(),
nn.Linear(2000, 1000),
nn.ReLU(),
nn.Linear(1000, 500)
).to(device)
# Create input data
input_data = torch.randn(64, 1000, device=device)
# Create optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
print(f"GPU {gpu_id}: Started with {len(tensors)} tensors")
while running[0]:
try:
# Forward pass
optimizer.zero_grad()
output = model(input_data)
loss = output.sum()
# Backward pass
loss.backward()
optimizer.step()
# Update tensors to keep them active
for i, tensor in enumerate(tensors):
if i % 2 == 0:
tensor.data = tensor.data * 0.99 + torch.randn_like(tensor) * 0.01
else:
tensor.data = torch.sin(tensor.data)
time.sleep(0.1) # Small delay
except Exception as e:
print(f"GPU {gpu_id}: Error - {e}")
time.sleep(1)
except Exception as e:
print(f"GPU {gpu_id}: Failed to initialize - {e}")
def display_status(gpus, running):
"""Display GPU status"""
while running[0]:
try:
print(f"\n[{datetime.now().strftime('%H:%M:%S')}] GPU Status:")
print("-" * 40)
for gpu_id in gpus:
try:
memory_allocated = torch.cuda.memory_allocated(gpu_id) / (1024**3)
memory_total = torch.cuda.get_device_properties(gpu_id).total_memory / (1024**3)
utilization = torch.cuda.utilization(gpu_id) if hasattr(torch.cuda, 'utilization') else "N/A"
print(f"GPU {gpu_id}: {memory_allocated:.1f}GB / {memory_total:.1f}GB ({(memory_allocated/memory_total)*100:.1f}%) | Util: {utilization}%")
except:
print(f"GPU {gpu_id}: Status unavailable")
time.sleep(5) # Update every 5 seconds
except KeyboardInterrupt:
break
except Exception as e:
print(f"Status display error: {e}")
time.sleep(5)
def main():
print("GPU Keep-Alive Script")
print("=" * 30)
# Detect GPUs
gpus = detect_gpus()
if not gpus:
return
# Shared flag to control all threads
running = [True]
# Start worker threads for each GPU
threads = []
for gpu_id in gpus:
thread = threading.Thread(target=gpu_worker, args=(gpu_id, running))
thread.daemon = True
thread.start()
threads.append(thread)
# Start status display thread
status_thread = threading.Thread(target=display_status, args=(gpus, running))
status_thread.daemon = True
status_thread.start()
print(f"\nStarted {len(gpus)} GPU workers")
print("Press Ctrl+C to stop...")
try:
# Keep main thread alive
while True:
time.sleep(1)
except KeyboardInterrupt:
print("\nStopping GPU workers...")
running[0] = False
# Wait for threads to finish
for thread in threads:
thread.join(timeout=2)
# Clear GPU memory
torch.cuda.empty_cache()
print("GPU workers stopped. Memory cleared.")
if __name__ == "__main__":
main()
