目录
https://arxiv.org/abs/1703.10593
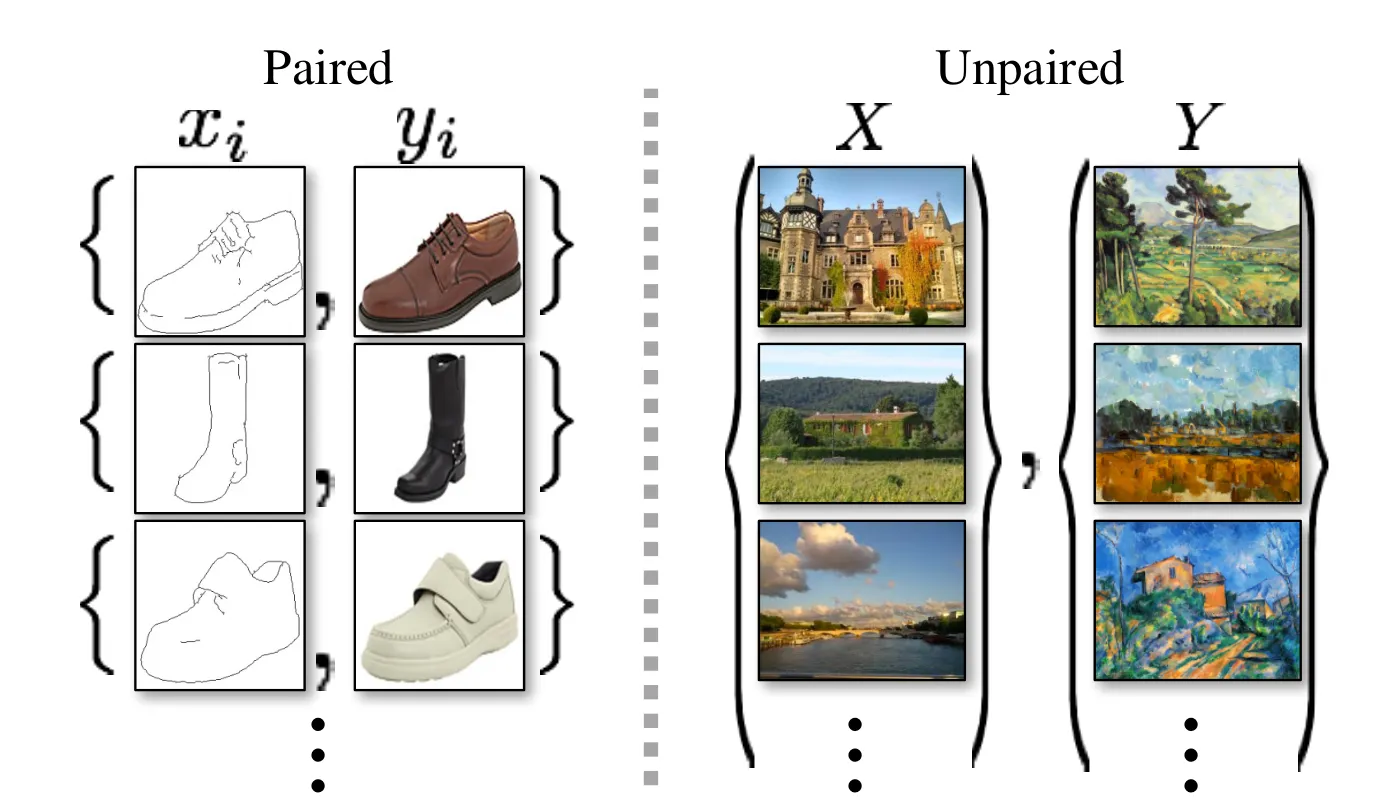
图像到图像的转换是一类视觉和图形问题,其目标是通过使用一组对齐的图像对训练集,学习输入图像与输出图像之间的映射关系。然而,对于许多任务来说,成对的训练数据并不可用。我们提出了一种方法,在没有对齐样本的情况下,学习将源域X的图像转换到目标域Y。我们在几个任务上展示了定性结果,包括风格迁移、对象变形、季节转换、照片增强等。如下图:

左图是成对的数据集,有图是不成对的数据集:
循环一致性 利用传递性来正则化结构化数据的思想由来已久。在视觉跟踪中,加强简单的前向-后向一致性已经是一种标准技巧 [24, 48]。在语言领域,通过“反向翻译和调解”来验证和改进翻译是一种人类译者 [3](包括幽默地由马克·吐温 [51])以及机器 [17] 使用的技术。更近期的,高阶循环一致性在运动结构 [61]、3D 形状匹配 [21]、共同分割 [55]、密集语义对齐 [65, 64] 和深度估计 [14] 中被使用。Zhou 等 [64] 和 Godard 等 [14] 的工作与我们的工作最为相似,因为他们使用循环一致性损失作为监督 CNN 训练的一种方式。在本研究中,我们引入了类似的损失来使 G 和 F 彼此一致。与我们的工作同时进行的,Yi 等 [59] 独立地使用类似的目标用于无配对图像到图像的转换,受机器翻译中的双重学习 [17] 启发。
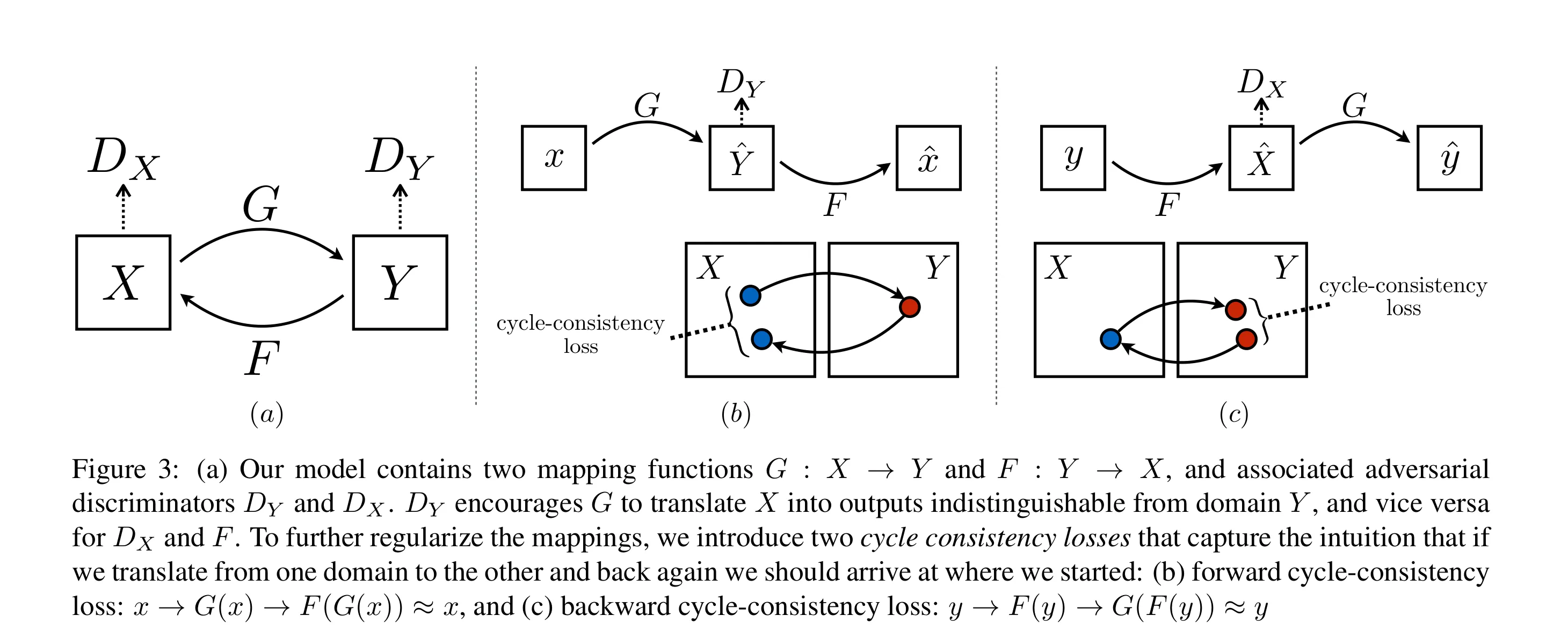
cyclegan 里面有两个生成模型和对应的判别模型,如下图:
对抗损失
跟一般的GAN类似,对抗损失表示为:
G的目标是最小化生成差距:
F的目标类似:
循环一致性损失
从理论上讲,对抗训练可以学习到生成器G和F,它们生成的输出分别与目标域Y和X完全一致(严格来说,这需要G和F为随机函数)[15]。然而,具有足够容量的网络可以将同一组输入图像映射到目标域中的任何随机排列的图像,其中任何一种学习到的映射都可能产生与目标分布相匹配的输出分布。因此,仅凭对抗损失无法保证学习到的函数能够将每个单独的输入映射到所期望的输出。
为了进一步缩小可能的映射函数的空间,我们认为学习到的映射函数应该是循环一致的:如图3(b)所示,对于来自域X的每一幅图像x,图像翻译循环应该能将x带回到原始图像,即。我们称之为前向循环一致性。同样,如图3(c)所示,对于来自域Y的每幅图像y,G和F还应满足反向循环一致性:。我们通过循环一致性损失鼓励这种行为:
在初步实验中,我们还尝试用F(G(x))和x之间的对抗性损失,以及G(F(y))和y之间的对抗性损失替换该损失中的L1范数,但没有观察到性能的改善。
完整目标
我们的完整目标是:
其中 控制两个目标相对的重要性。我们旨在解决:
请注意,我们的模型可以看作是训练两个“自动编码器”[20]:
我们学习一个自动编码器 与另一个 共同训练。
然而,这些自动编码器各自具有特殊的内部结构:它们通过将图像转化到另一个域的中间表示来对图像进行自映射。这样的设置也可以看作是“对抗自动编码器”[34] 的一种特殊情况,它们使用对抗损失来训练自动编码器的瓶颈层以匹配任意目标分布。在我们的情况中, 自动编码器的目标分布是域 的分布。
在第5.1.4节中,我们对我们的方法与完整目标的消融版本进行了比较,包括仅使用对抗损失 和仅使用循环一致性损失 ,并通过实验表明这两个目标在获得高质量结果方面起到关键作用。我们还评估了仅在一个方向上使用循环损失的方法,并证明单个循环不足以正则化该欠约束问题的训练。
实现
网络架构 我们采用了Johnson等人[23]的生成网络架构,他们在神经风格迁移和超分辨率方面展示了令人印象深刻的结果。这个网络包含三个卷积层、多个残差块[18]、两个带有步幅 的分数卷积层以及一个将特征映射到RGB的卷积层。对于128×128的图像,我们使用6个块,而对于256×256及更高分辨率的训练图像,我们使用9个块。类似于Johnson等人[23],我们使用实例归一化[53]。对于判别器网络,我们使用70×70的PatchGANs[22, 30, 29],它旨在分类70×70重叠图像块是真实的还是伪造的。这样的块级判别器架构比全图像判别器参数更少,并且可以在任意尺寸的图像上以完全卷积方式工作[22]。
训练细节 我们应用了最近一些研究中的两种技术来稳定我们的模型训练过程。首先,对于 (公式1),我们用最小二乘损失[35]替换了负对数似然目标。这个损失在训练过程中更稳定,并生成更高质量的结果。特别是,对于GAN损失 ,我们训练G以最小化 并训练D以最小化 。
其次,为了减少模型的振荡[15],我们遵循Shrivastava等人的策略[46],使用生成图像的历史来更新判别器,而不是使用最新生成器产生的图像。我们保持一个图像缓冲区,存储先前创建的50张图像。
对于所有实验,我们在公式3中设置 。我们使用Adam求解器[26],批量大小为1。所有网络都是从头开始训练的,学习率为0.0002。我们在前100个epoch中保持相同的学习率,并在接下来的100个epoch中线性递减到零。请参阅附录(第7节)了解有关数据集、架构和训练过程的更多细节。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!