目录
https://github.com/open-mmlab/mmgeneration/tree/master
环境
Dockerfile:https://github.com/open-mmlab/mmgeneration/blob/master/docker/Dockerfile
是这样的:
展开代码ARG PYTORCH="1.8.0" ARG CUDA="11.1" ARG CUDNN="8" FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX" ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all" ENV CMAKE_PREFIX_PATH="$(dirname $(which conda))/../" RUN apt-get update && apt-get install -y ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* # Install MMCV RUN pip install mmcv-full==1.5.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html # Install MMGeneration RUN conda clean --all RUN git clone https://github.com/open-mmlab/mmgeneration.git /mmgen WORKDIR /mmgen ENV FORCE_CUDA="1" RUN pip install -r requirements.txt RUN pip install --no-cache-dir -e .
遇到错误:
Reading package lists... Done
W: GPG error: https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY A4B469963BF863CC
E: The repository 'https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease' is not signed.
N: Updating from such a repository can't be done securely, and is therefore disabled by default.
N: See apt-secure(8) manpage for repository creation and user configuration details.
解决:
展开代码$ apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub $ apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
环境:
展开代码docker commit 5761ab0afd43 kevinchina/deeplearning:mmgenerationv1
对模型和算法进行测试
数据下载
官方教程:https://mmgeneration.readthedocs.io/en/latest/quick_run.html
下载官网的pix2pix的数据:
cityscapes.tar.gz
https://efrosgans.eecs.berkeley.edu/pix2pix/datasets/
根据教程所述,数据集其实有两种,没有pair的和pair过的。这个数据集就是pair过的,长这样:

pair过的数据其实就是做了一个拼接处理,图片翻译领域,一张图左边是原图、右边是原图的另外一种形式,pix2pix讲究的就是可以从一种形式转为另外一种形式。

下载数据:
展开代码wget https://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz tar zxf facades.tar.gz
预训练的模型
用facades数据集做做实验,下载对应权重:
展开代码- Config: https://github.com/open-mmlab/mmgeneration/tree/master/configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py In Collection: Pix2Pix Metadata: Training Data: FACADES Name: pix2pix_vanilla_unet_bn_facades_b1x1_80k Results: - Dataset: FACADES Metrics: FID: 124.9773 IS: 1.62 Task: Image2Image Translation Weights: https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth
下载预训练权重:
展开代码wget https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth
启动容器进行推理
启动:
展开代码docker run --gpus all --shm-size=16g -it \ -v ./datasets/facades:/mmgen/data \ -v ./pretrain:/mmgen/pretain \ kevinchina/deeplearning:mmgenerationv1-addtb bash
执行一次图片翻译:
展开代码python demo/translation_demo.py \ 'configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py' \ /mmgen/pretain/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth \ 'tests/data/paired/test/3.jpg' \ --save-path data/demo.png
'tests/data/paired/test/3.jpg'是这样的:

pix2pix的图片翻译效果:

测试现有模型
使用 tools/utils/translation_eval.py 评估翻译模型。
source_domain = 'mask':这意味着作为翻译输入的图像来自'掩码'域。这可以表示例如分割掩码图片。 target_domain = 'photo':这意味着翻译之后目标图像属于'照片'域。这可以表示例如真实照片图片。
编辑这里:vim configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py
这句改为实际的图片路径:dataroot = 'data/paired/facades'
改为:dataroot = 'data'
执行测试:
展开代码python tools/utils/translation_eval.py \ configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py \ /mmgen/pretain/pix2pix_vanilla_unet_bn_1x1_80k_facades_20210902_170442-c0958d50.pth \ --target-domain photo \ --batch-size 1 \ --eval FID IS
可以得到测试结果:
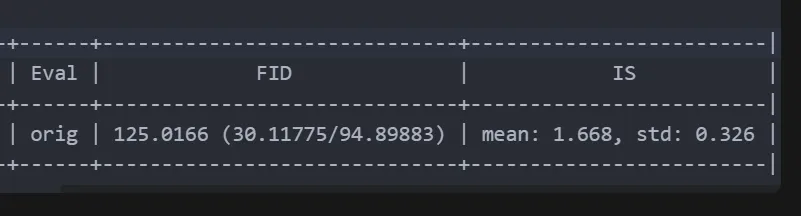
配置文件
展开代码_base_ = [ '../_base_/models/pix2pix/pix2pix_vanilla_unet_bn.py', '../_base_/datasets/paired_imgs_256x256_crop.py', '../_base_/default_runtime.py' ] source_domain = 'mask' target_domain = 'photo' # model settings model = dict( default_domain=target_domain, reachable_domains=[target_domain], related_domains=[target_domain, source_domain], gen_auxiliary_loss=dict( data_info=dict( pred=f'fake_{target_domain}', target=f'real_{target_domain}'))) batch_size = 16 # dataset settings domain_a = target_domain domain_b = source_domain img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) train_pipeline = [ dict( type='LoadPairedImageFromFile', io_backend='disk', key='pair', domain_a=domain_a, domain_b=domain_b, flag='color'), dict( type='Resize', keys=[f'img_{domain_a}', f'img_{domain_b}'], scale=(286, 286), interpolation='bicubic'), dict( type='FixedCrop', keys=[f'img_{domain_a}', f'img_{domain_b}'], crop_size=(256, 256)), dict( type='Flip', keys=[f'img_{domain_a}', f'img_{domain_b}'], direction='horizontal'), dict(type='RescaleToZeroOne', keys=[f'img_{domain_a}', f'img_{domain_b}']), dict( type='Normalize', keys=[f'img_{domain_a}', f'img_{domain_b}'], to_rgb=False, **img_norm_cfg), dict(type='ImageToTensor', keys=[f'img_{domain_a}', f'img_{domain_b}']), dict( type='Collect', keys=[f'img_{domain_a}', f'img_{domain_b}'], meta_keys=[f'img_{domain_a}_path', f'img_{domain_b}_path']) ] test_pipeline = [ dict( type='LoadPairedImageFromFile', io_backend='disk', key='pair', domain_a=domain_a, domain_b=domain_b, flag='color'), dict( type='Resize', keys=[f'img_{domain_a}', f'img_{domain_b}'], scale=(256, 256), interpolation='bicubic'), dict(type='RescaleToZeroOne', keys=[f'img_{domain_a}', f'img_{domain_b}']), dict( type='Normalize', keys=[f'img_{domain_a}', f'img_{domain_b}'], to_rgb=False, **img_norm_cfg), dict(type='ImageToTensor', keys=[f'img_{domain_a}', f'img_{domain_b}']), dict( type='Collect', keys=[f'img_{domain_a}', f'img_{domain_b}'], meta_keys=[f'img_{domain_a}_path', f'img_{domain_b}_path']) ] dataroot = 'data' data = dict( train=dict(dataroot=dataroot, pipeline=train_pipeline), val=dict(dataroot=dataroot, pipeline=test_pipeline), test=dict(dataroot=dataroot, pipeline=test_pipeline)) # optimizer optimizer = dict( generators=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999)), discriminators=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999))) # learning policy lr_config = None # checkpoint saving checkpoint_config = dict(interval=10000, save_optimizer=True, by_epoch=False) custom_hooks = [ dict( type='MMGenVisualizationHook', output_dir='training_samples', res_name_list=[f'fake_{target_domain}'], interval=5000) ] runner = None use_ddp_wrapper = True # runtime settings total_iters = 80000 workflow = [('train', 1)] exp_name = 'pix2pix_facades' work_dir = f'./work_dirs/experiments/{exp_name}' num_images = 106 metrics = dict( FID=dict(type='FID', num_images=num_images, image_shape=(3, 256, 256)), IS=dict( type='IS', num_images=num_images, image_shape=(3, 256, 256), inception_args=dict(type='pytorch'))) # evaluation = dict( # type='TranslationEvalHook', # target_domain=domain_b, # interval=10000, # metrics=[ # dict(type='FID', num_images=num_images, bgr2rgb=True), # dict( # type='IS', # num_images=num_images, # inception_args=dict(type='pytorch')) # ], # best_metric=['fid', 'is']) # 日志配置信息 log_config = dict( interval=10, # 打印日志的间隔, 单位 iters hooks=[ dict(type='TextLoggerHook'), # 用于记录训练过程的文本记录器(logger) dict(type='TensorboardLoggerHook') # 同样支持 Tensorboard 日志 ]) # yapf:enable log_level = 'INFO' # 日志的输出级别
训练现有模型
分布式训练:
展开代码export OMP_NUM_THREADS=8 export MKL_NUM_THREADS=8 export CONFIG_FILE=configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py export GPUS_NUMBER=4 export WORK_DIR=./work_dirs/experiments/experiment_name bash tools/dist_train.sh ${CONFIG_FILE} ${GPUS_NUMBER} \ --work-dir ${WORK_DIR}
训练中进行评估指标有报错,删除配置里训练时候评估的设置。
如何基于已有模型训练
在config文件中配置load_from:
展开代码load_from = 'https://download.openmmlab.com/mmgen/stylegan3/stylegan3_t_ffhq_1024_b4x8_cvt_official_rgb_20220329_235113-db6c6580.pth' # noqa
如何resume训练
使用train.py中的参数--resume-from
日志
安装这个:
展开代码pip install future tensorboard
配置文件里加上这个配置:
展开代码# 日志配置信息 log_config = dict( interval=10, # 打印日志的间隔, 单位 iters hooks=[ dict(type='TextLoggerHook'), # 用于记录训练过程的文本记录器(logger) dict(type='TensorboardLoggerHook') # 同样支持 Tensorboard 日志 ]) # yapf:enable log_level = 'INFO' # 日志的输出级别
则可以通过tensorboard查看日志:
展开代码tensorboard --logdir="tf_logs/"
制作数据
熟悉上述demo后,开始制作数据,任务内容定义为“通用黑白图片上色任务”,“通用”是要求数据集的场景覆盖足够,“黑白图片”是要求数据集是给黑白灰度图片上色,而不是别的图片类型,比如线稿之类的图片。
使用这个代码构建数据集:
python展开代码import os
import random
from PIL import Image
import shutil
# 定义目录路径
src_dir = '/ssd/xiedong/image_color/self_data_mock'
dest_dir = '/ssd/xiedong/image_color/paired_self_datasets'
train_dir = os.path.join(dest_dir, 'train')
test_dir = os.path.join(dest_dir, 'test')
val_dir = os.path.join(dest_dir, 'val')
# 创建目标文件夹
os.makedirs(train_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
# 获取所有图片文件列表
file_list = [f for f in os.listdir(src_dir) if os.path.isfile(os.path.join(src_dir, f))]
# 打乱文件列表
random.shuffle(file_list)
# 分割数据集
total_files = len(file_list)
train_files = file_list[:int(0.8 * total_files)]
test_files = file_list[int(0.8 * total_files):int(0.9 * total_files)]
val_files = file_list[int(0.9 * total_files):]
def process_and_save(img_files, folder):
for img_file in img_files:
img_path = os.path.join(src_dir, img_file)
img = Image.open(img_path).convert('RGB')
# 转换为黑白图
bw_img = img.convert('L')
bw_img = bw_img.convert('RGB') # 扩展为3通道
# 拼接图片
combined_img = Image.new('RGB', (img.width * 2, img.height))
combined_img.paste(img, (0, 0))
combined_img.paste(bw_img, (img.width, 0))
# 保存图片
combined_img.save(os.path.join(folder, os.path.splitext(img_file)[0] + '.jpg'))
# 处理和保存所有数据集
process_and_save(train_files, train_dir)
process_and_save(test_files, test_dir)
process_and_save(val_files, val_dir)
print("数据集已成功生成。")
取出一张训练数据来看,训练数据的一张图里,左边是真实域(模型要输出的),右边是fake域(输入给模型的):

用这个代码查看数据集分布:
python展开代码import os
# 定义数据集目录
dest_dir = '/ssd/xiedong/image_color/paired_self_datasets'
train_dir = os.path.join(dest_dir, 'train')
test_dir = os.path.join(dest_dir, 'test')
val_dir = os.path.join(dest_dir, 'val')
# 统计每个目录中的文件数量
def count_files(directory):
return len([f for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))])
train_count = count_files(train_dir)
test_count = count_files(test_dir)
val_count = count_files(val_dir)
# 打印输出
print(f"训练集数量: {train_count}")
print(f"测试集数量: {test_count}")
print(f"验证集数量: {val_count}")
8:1:1的配比:
- 训练集数量: 143192
- 测试集数量: 17899
- 验证集数量: 17899
训练
展开代码docker run --gpus all --shm-size=16g -it --net host \ -v /ssd/xiedong/image_color/paired_self_datasets:/mmgen/data \ -v ./pretrain:/mmgen/pretain \ -v ./work_dirs:/mmgen/work_dirs \ kevinchina/deeplearning:mmgenerationv1-addtb bash vim configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py vim configs/ export OMP_NUM_THREADS=8 export MKL_NUM_THREADS=8 export CONFIG_FILE=configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py export GPUS_NUMBER=4 export WORK_DIR=./work_dirs/experiments/experiment_name bash tools/dist_train.sh ${CONFIG_FILE} ${GPUS_NUMBER} \ --work-dir ${WORK_DIR} # 宿主机可以看日志 tensorboard --logdir="tf_logs/" --bind_all
执行一次图片翻译:
展开代码python demo/translation_demo.py \ 'configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py' \ /mmgen/work_dirs/experiments/experiment_name/ckpt/experiment_name/latest.pth \ 'data/test/zooh_002419.jpg' \ --save-path work_dirs/demo.png
训练损失曲线:
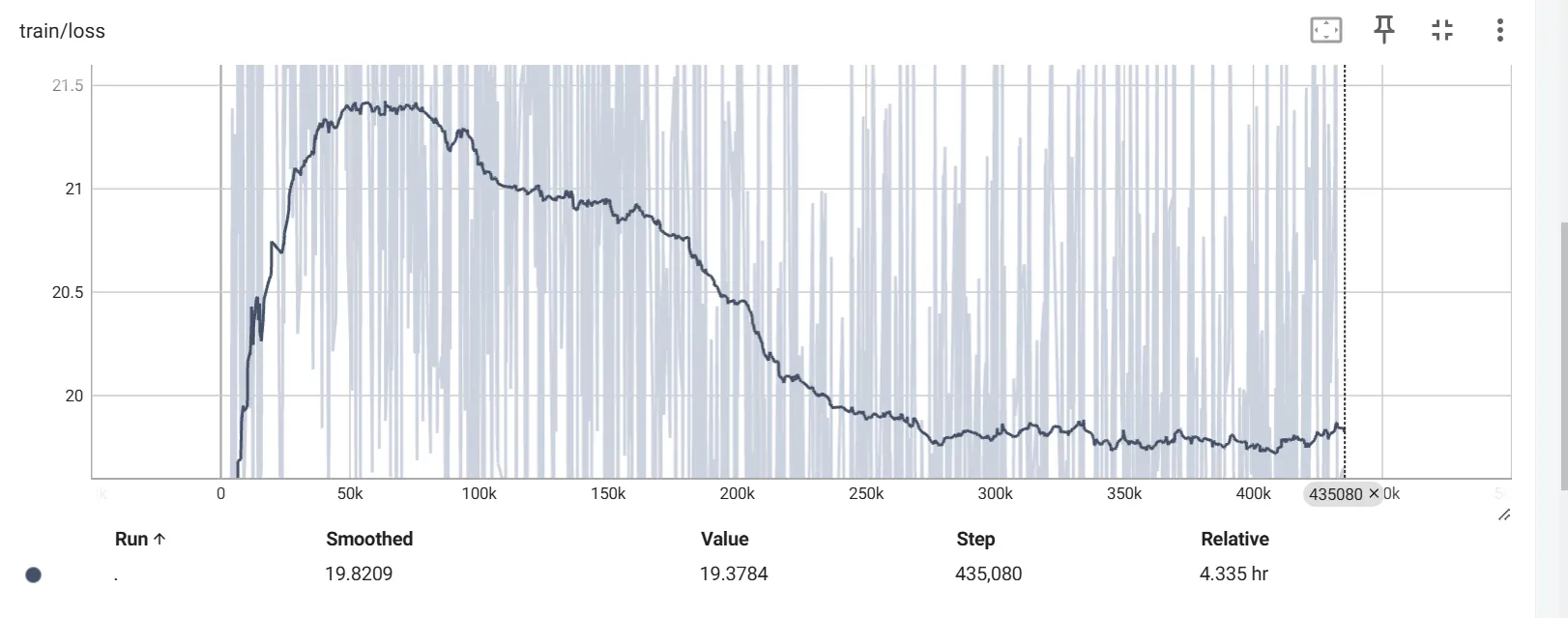
效果
测试示例:

pix2pix模型的上色效果:

很难看,效果不好,我这15w图片的数据集覆盖了生活的方方面面的图片,模型无法记住这么庞大的信息量形成一个有效的信息映射。
找个简单的专项任务——线稿上色


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!