pix2pix mmgeneration 线稿上色,模型训练实战,Docker【2】
目录
通用场景上色任务太难,pix2pix效果不佳:
https://www.dong-blog.fun/post/1924
通用场景照片的要求太大了:要场景、要渐变色、要理解场景里的事物,比如你总不能给树叶上一个红色,是需要一定语义理解能力的。
线稿是一种需要块状涂色的任务,相对就简单得多。
这是线稿任务:
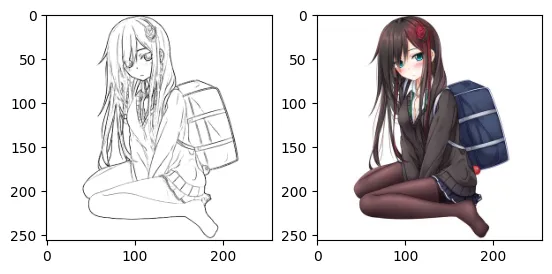
数据集
https://www.kaggle.com/datasets/ktaebum/anime-sketch-colorization-pair
下载这个数据集:
展开代码import kagglehub # Download latest version path = kagglehub.dataset_download("ktaebum/anime-sketch-colorization-pair") print("Path to dataset files:", path)
训练
展开代码docker run --gpus all --shm-size=16g -it --net host \ -v /ssd/xiedong/image_color/anime-sketch-colorization-pair/data:/mmgen/data \ -v ./pretrain:/mmgen/pretain \ -v ./work_dirs:/mmgen/work_dirs \ kevinchina/deeplearning:mmgenerationv1-addtb bash vim configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py export OMP_NUM_THREADS=8 export MKL_NUM_THREADS=8 export CONFIG_FILE=configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py export GPUS_NUMBER=4 export WORK_DIR=./work_dirs/pix2pix_xiangao bash tools/dist_train.sh ${CONFIG_FILE} ${GPUS_NUMBER} \ --work-dir ${WORK_DIR} # 宿主机可以看日志 tensorboard --logdir="tf_logs/" --bind_all
配置写:
展开代码_base_ = [ '../_base_/models/pix2pix/pix2pix_vanilla_unet_bn.py', '../_base_/datasets/paired_imgs_256x256_crop.py', '../_base_/default_runtime.py' ] source_domain = 'mask' target_domain = 'photo' # model settings model = dict( default_domain=target_domain, reachable_domains=[target_domain], related_domains=[target_domain, source_domain], gen_auxiliary_loss=dict( data_info=dict( pred=f'fake_{target_domain}', target=f'real_{target_domain}'))) # dataset settings domain_a = target_domain domain_b = source_domain img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) train_pipeline = [ dict( type='LoadPairedImageFromFile', io_backend='disk', key='pair', domain_a=domain_a, domain_b=domain_b, flag='color'), dict( type='Resize', keys=[f'img_{domain_a}', f'img_{domain_b}'], scale=(286, 286), interpolation='bicubic'), dict( type='FixedCrop', keys=[f'img_{domain_a}', f'img_{domain_b}'], crop_size=(256, 256)), dict( type='Flip', keys=[f'img_{domain_a}', f'img_{domain_b}'], direction='horizontal'), dict(type='RescaleToZeroOne', keys=[f'img_{domain_a}', f'img_{domain_b}']), dict( type='Normalize', keys=[f'img_{domain_a}', f'img_{domain_b}'], to_rgb=False, **img_norm_cfg), dict(type='ImageToTensor', keys=[f'img_{domain_a}', f'img_{domain_b}']), dict( type='Collect', keys=[f'img_{domain_a}', f'img_{domain_b}'], meta_keys=[f'img_{domain_a}_path', f'img_{domain_b}_path']) ] test_pipeline = [ dict( type='LoadPairedImageFromFile', io_backend='disk', key='pair', domain_a=domain_a, domain_b=domain_b, flag='color'), dict( type='Resize', keys=[f'img_{domain_a}', f'img_{domain_b}'], scale=(256, 256), interpolation='bicubic'), dict(type='RescaleToZeroOne', keys=[f'img_{domain_a}', f'img_{domain_b}']), dict( type='Normalize', keys=[f'img_{domain_a}', f'img_{domain_b}'], to_rgb=False, **img_norm_cfg), dict(type='ImageToTensor', keys=[f'img_{domain_a}', f'img_{domain_b}']), dict( type='Collect', keys=[f'img_{domain_a}', f'img_{domain_b}'], meta_keys=[f'img_{domain_a}_path', f'img_{domain_b}_path']) ] dataroot = 'data' data = dict( train=dict(dataroot=dataroot, pipeline=train_pipeline), val=dict(dataroot=dataroot, pipeline=test_pipeline), test=dict(dataroot=dataroot, pipeline=test_pipeline)) # optimizer optimizer = dict( generators=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999)), discriminators=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999))) # learning policy lr_config = None # checkpoint saving checkpoint_config = dict(interval=50000, save_optimizer=True, by_epoch=False) custom_hooks = [ dict( type='MMGenVisualizationHook', output_dir='training_samples', res_name_list=[f'fake_{target_domain}'], interval=5000) ] runner = None use_ddp_wrapper = True # runtime settings total_iters = 1000000 workflow = [('train', 1)] exp_name = 'pix2pix_xian_gao' work_dir = f'./work_dirs/{exp_name}' num_images = 5000 metrics = dict( FID=dict(type='FID', num_images=num_images, image_shape=(3, 256, 256)), IS=dict( type='IS', num_images=num_images, image_shape=(3, 256, 256), inception_args=dict(type='pytorch'))) # evaluation = dict( # type='TranslationEvalHook', # target_domain=domain_b, # interval=10000, # metrics=[ # dict(type='FID', num_images=num_images, bgr2rgb=True), # dict( # type='IS', # num_images=num_images, # inception_args=dict(type='pytorch')) # ], # best_metric=['fid', 'is']) # 日志配置信息 log_config = dict( interval=10, # 打印日志的间隔, 单位 iters hooks=[ dict(type='TextLoggerHook'), # 用于记录训练过程的文本记录器(logger) dict(type='TensorboardLoggerHook') # 同样支持 Tensorboard 日志 ]) # yapf:enable log_level = 'INFO' # 日志的输出级别
这个任务显然是简单一些,loss很快就降低了:
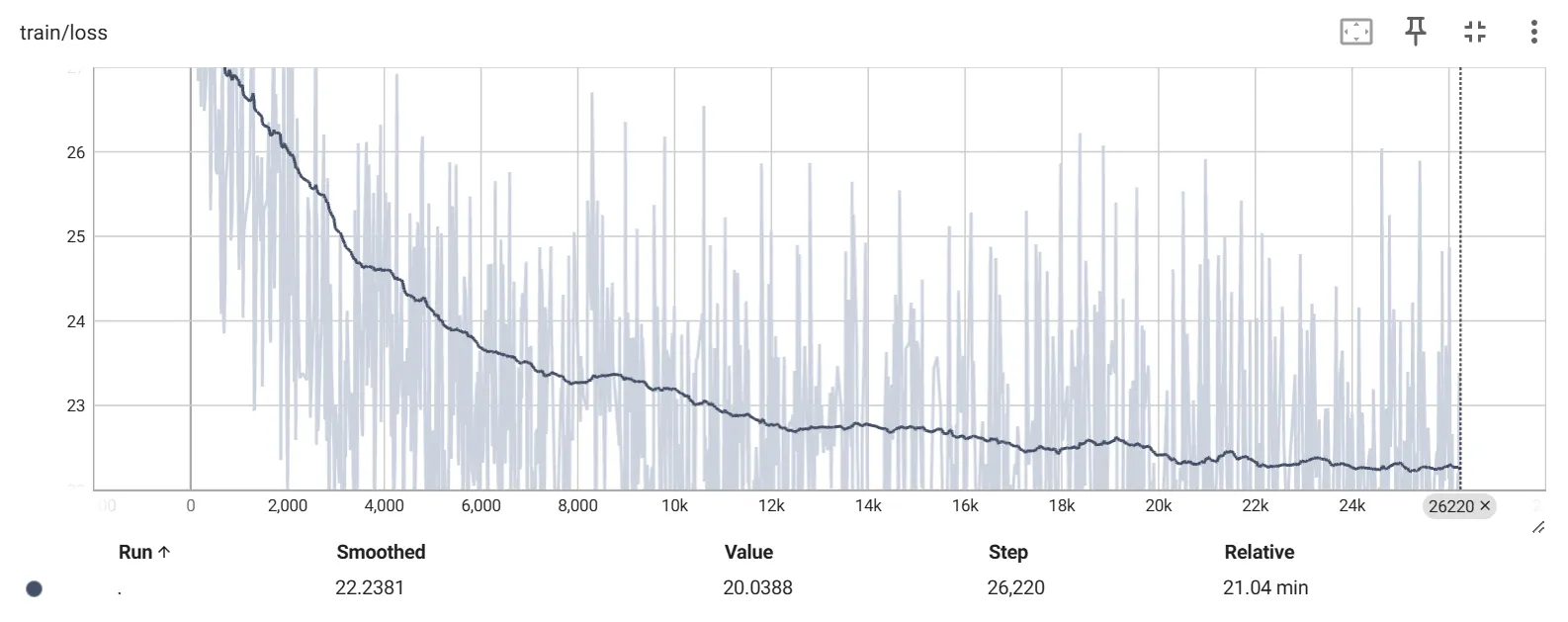
推理
展开代码python demo/translation_demo.py \ 'configs/pix2pix/pix2pix_vanilla_unet_bn_facades_b1x1_80k.py' \ /mmgen/work_dirs/pix2pix_xiangao/ckpt/pix2pix_xiangao/latest.pth \ 'data/test/984079.png' \ --save-path work_dirs/demo.png

效果还是不好,换个框架再试试,这个mmgeneration 是不是有毒:

如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录