目录
基于pix2pix的图像彩色化技术实践与探索
一、项目背景与问题发现
在前期实验中,我尝试使用mmgen库进行通用图像和线稿的处理,但效果不尽如人意。这让我开始怀疑mmgen库在此类任务中的适用性。经过评估后,我决定转向另一个成熟的解决方案。
二、技术方案选型
2.1 选定仓库
最终选择的实现方案来自以下GitHub仓库:
bash展开代码git@github.com:junyanz/pytorch-CycleGAN-and-pix2pix.git
2.2 环境配置
采用Docker容器搭建训练环境,具体配置如下:
bash展开代码docker run --gpus all --shm-size=32g -it --net host \ -v ./pytorch-CycleGAN-and-pix2pix/:/pytorch-CycleGAN-and-pix2pix/ \ -v ./anime-sketch-colorization-pair/data:/data \ pytorch/pytorch:2.5.1-cuda12.1-cudnn9-devel bash pip install -r requirements.txt
为方便后续使用,已将配置好的环境保存为镜像:
bash展开代码kevinchina/deeplearning:2.5.1-cuda12.1-cudnn9-devel-pix2pix
直接使用命令:
bash展开代码docker run --gpus all --shm-size=32g -it --net host \ -v ./pytorch-CycleGAN-and-pix2pix/:/pytorch-CycleGAN-and-pix2pix/ \ -v ./anime-sketch-colorization-pair/data:/data \ kevinchina/deeplearning:2.5.1-cuda12.1-cudnn9-devel-pix2pix bash
三、训练过程实录
3.1 基础训练配置
首先启动visdom可视化服务器:
bash展开代码python -m visdom.server -p 8097
采用以下两种训练方式之一:
基础训练命令:
bash展开代码python train.py --dataroot /data/ --name anime --gpu_ids 0,1,2,3 \ --model pix2pix --direction BtoA --batch_size 192 --lr_policy cosine \ --num_threads 32 --init_type xavier --norm instance --netG unet_256
带visdom监控的训练:
bash展开代码-display_server http://remote_ip --display_port 8097
通过浏览器访问8097端口可查看训练效果:
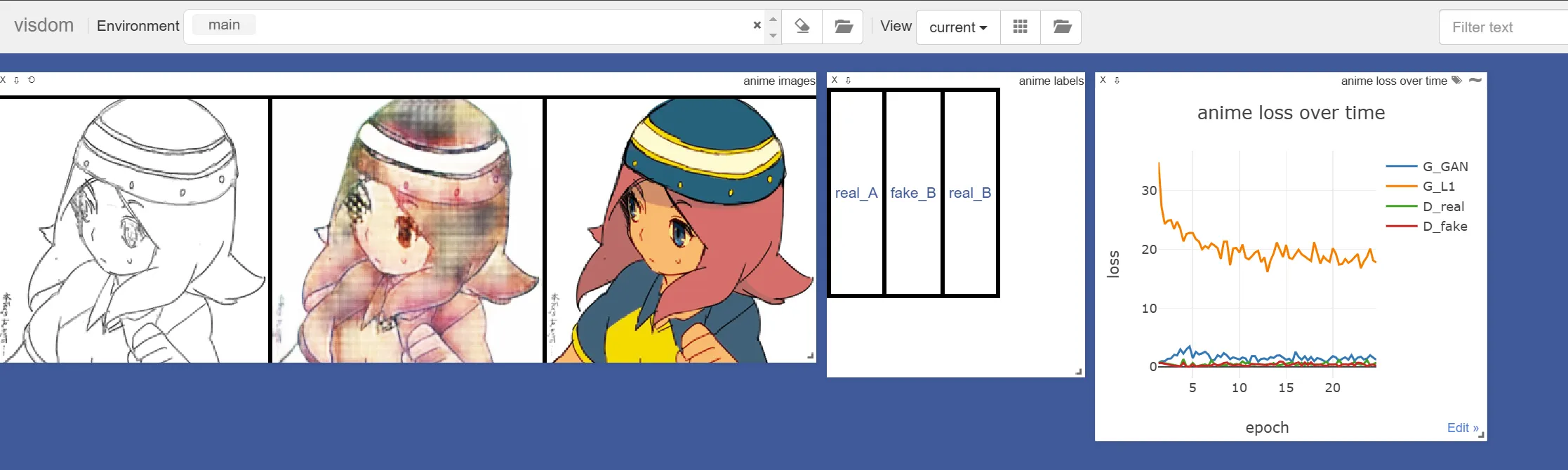
3.2 初步训练结果
经过200轮训练后,效果仍有提升空间:
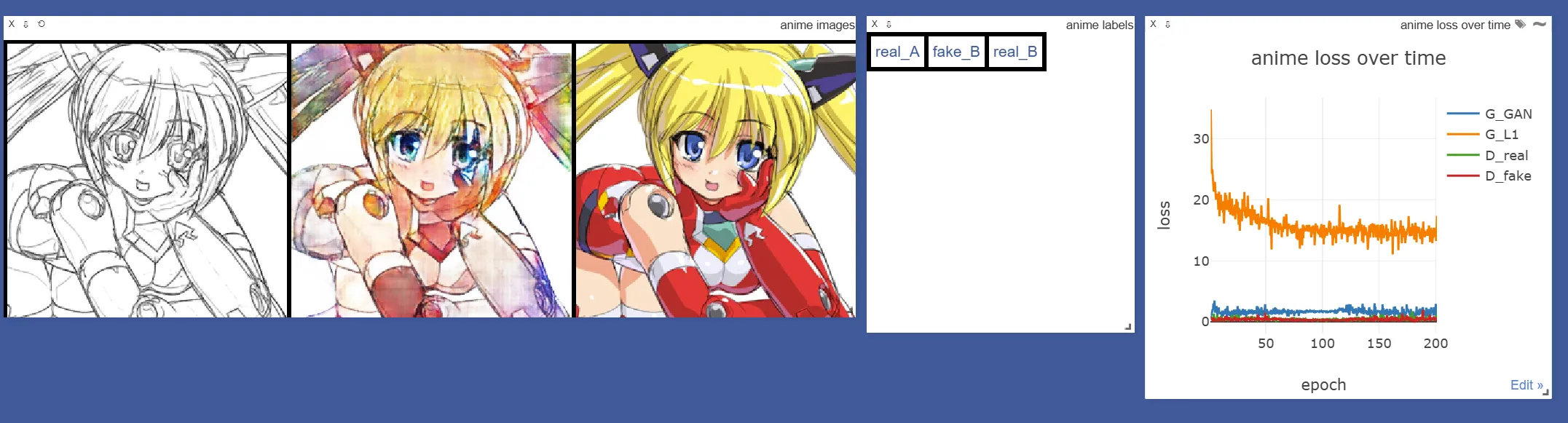
四、优化后的彩色化方案
4.1 技术原理突破
深入研究后发现更优的彩色化方法:输入单通道黑白图,输出为LAB色彩空间中的AB通道。
4.2 改进训练配置
bash展开代码cd /ssd/xiedong/image_color
docker run --gpus all --shm-size=32g -it --net host \
-v ./pytorch-CycleGAN-and-pix2pix/:/pytorch-CycleGAN-and-pix2pix/ \
-v ./unpaired_self_datasets/:/data \
kevinchina/deeplearning:2.5.1-cuda12.1-cudnn9-devel-pix2pix bash
nohup python -m visdom.server -p 8097 &
pip install -U scikit-image
cd /pytorch-CycleGAN-and-pix2pix/
python train.py \
--dataroot /data/ \
--name tongyong_l2ab_4 \
--gpu_ids 0,1,2 \
--model colorization \
--direction AtoB \
--batch_size 196 \
--lr_policy cosine \
--num_threads 32 \
--init_type xavier \
--norm instance \
--netG unet_256 \
--dataset_mode colorization \
--input_nc 1 \
--output_nc 2 \
--phase trainA \
--n_epochs 100
训练后可以绘制损失变化图:
python plot_loss_paper.py
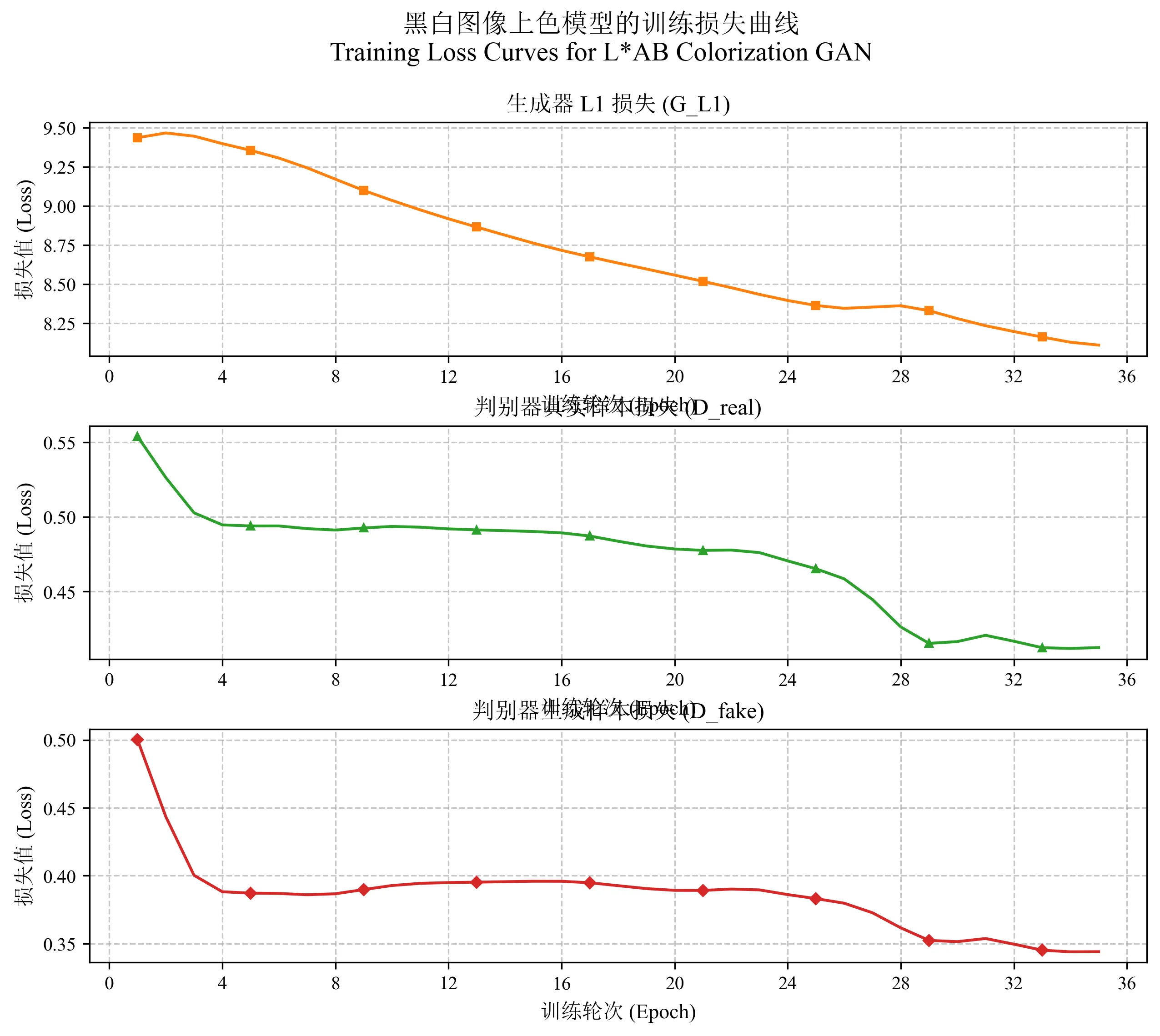
4.3 数据处理流程
• 系统自动将RGB图像转换为Lab色彩空间 • 分离L通道(亮度)作为输入 • 提取ab通道(色彩)作为输出目标 • 转换过程在ColorizationDataset类中自动完成
4.4 训练效果展示
验证集输入(valA):

验证集目标(valB):

生成效果对比:

训练完成的模型保存在:
展开代码pytorch-CycleGAN-and-pix2pix/checkpoints
五、技术参数详解
5.1 核心训练参数说明
基础配置
| 参数 | 说明 | 示例值 |
|---|---|---|
--dataroot | 数据根目录 | /data/ |
--name | 实验名称 | tongyong_l2ab_4 |
--gpu_ids | 使用的GPU编号 | 0,1,2 |
模型架构
| 参数 | 说明 | 可选值 |
|---|---|---|
--model | 模型类型 | colorization |
--netG | 生成器架构 | unet_256 |
--norm | 归一化方法 | instance |
训练策略
| 参数 | 说明 | 典型值 |
|---|---|---|
--lr_policy | 学习率策略 | cosine |
--batch_size | 批次大小 | 196 |
--n_epochs | 训练周期数 | 100 |
5.2 训练日志解析
典型训练日志示例:
展开代码(epoch: 39, iters: 115800, time: 0.007, data: 0.044) G_GAN: 2.019 G_L1: 8.129 D_real: 0.409 D_fake: 0.279
指标说明
- G_GAN:生成器对抗损失,反映生成器欺骗判别器的能力
- G_L1:生成器L1损失,衡量色彩预测准确性
- D_real:判别器对真实样本的识别能力
- D_fake:判别器对生成样本的识别能力
数学表达
• 生成器总损失: • 判别器总损失:
六、技术原理深入
6.1 色彩空间理论
采用CIE Lab色彩空间,其中:
- • L通道:亮度信息(0-100)
- • a通道:绿(-128)到红(+127)色度
- • b通道:蓝(-128)到黄(+127)色度
6.2 网络架构
生成器设计
U-Net结构包含:
- 编码器路径:8级下采样
- 解码器路径:对应上采样
- 跳跃连接:保留细节信息
判别器设计
采用PatchGAN架构:
- • 局部感受野:70×70像素
- • 输出特征图:
6.3 训练优化
- • 数据增强:随机裁剪/翻转
- • 归一化处理:L通道→[-1,1],ab通道→[-1,1]
- • 损失权重:
七、应用与验证
7.1 测试方法
要测试您训练好的模型(第35轮)使用您在"/data/testA"的测试数据,您应该在服务器上运行以下命令:
展开代码python test.py --dataroot /data/ --name tongyong_l2ab_4 --model colorization --direction AtoB --netG unet_256 --dataset_mode colorization --input_nc 1 --output_nc 2 --phase testA --epoch 35 --eval --num_test 500 --norm instance
如果想处理数据集中的所有图像,您需要将num_test设置为一个足够大的数字,确保它大于数据集中的图像总数。
结果会被保存到:results/tongyong_l2ab_4/testA_35/images/
此命令将:
- 从第35轮加载您的模型检查点
- 处理来自testA目录的图像
- 生成着色结果
- 将结果保存到HTML网页以便进行视觉检查
关键参数说明:
--dataroot /data/:数据目录的路径--name tongyong_l2ab_4:您的实验名称(与训练名称匹配)--model colorization:使用着色模型--netG unet_256:使用与训练相同的生成器架构--input_nc 1 --output_nc 2:与您的训练设置相同(L到ab颜色空间)--phase testA:使用testA目录进行测试--epoch 35:从第35轮加载模型--eval:在评估模式下运行(禁用dropout)--num_test 500:测试多达500张图像(您可以调整这个数字)
修改几句代码才行
报错了,需要改几句代码:
对于 PyTorch 2.5 版本,您需要修改服务器上的代码。服务器上的 load_networks 函数中有两个不兼容的参数:
weights_only=True- 这是较新版本的 PyTorch 引入的参数strict=False- 这个参数应该传递给load_state_dict而不是torch.load
因此,正确的修改方案是:
- 在服务器上编辑
models/base_model.py文件 - 找到
load_networks函数中的这一行:
python展开代码state_dict = torch.load(load_path, weights_only=True, map_location=self.device, strict=False)
- 将其修改为:
python展开代码state_dict = torch.load(load_path, map_location=str(self.device))
- 如果您需要保留
strict=False的功能,则需要修改后面的load_state_dict调用:
python展开代码net.load_state_dict(state_dict, strict=False)
这样修改后应该可以与 PyTorch 2.5 兼容,同时保持原有功能。
- 其他介绍:
weights_only=True 参数
- 功能:这是PyTorch较新版本(2.0+)引入的参数,用于只加载模型的权重部分,而不加载优化器状态、学习率调度器等其他存储在模型文件中的信息。
- 作用:当您只需要模型权重而不需要恢复训练状态时,此参数可以节省内存并加快加载速度。
map_location=self.device vs map_location=str(self.device)
- 旧版本PyTorch(0.4之前)需要字符串形式,而较新版本既可以接受torch.device对象也可以接受字符串。
strict=False 参数
- 功能:strict参数控制在加载模型时如何处理键不匹配的情况。
- 关键点:在您修改前的代码中,strict=False被错误地放在了torch.load()调用中,而它应该属于后续的load_state_dict()调用。
testA目录
testA目录 里应该是彩色的图片,ColorizationDataset 类里会进行这样的处理:
python展开代码def __getitem__(self, index):
path = self.AB_paths[index]
im = Image.open(path).convert('RGB') # <-- 打开图像并转换为RGB
im = self.transform(im)
im = np.array(im)
lab = color.rgb2lab(im).astype(np.float32) # <-- 将RGB转换为Lab
lab_t = transforms.ToTensor()(lab)
A = lab_t[[0], ...] / 50.0 - 1.0 # <-- 提取L通道(灰度)
B = lab_t[[1, 2], ...] / 110.0 # <-- 提取ab通道(色彩)
return {'A': A, 'B': B, 'A_paths': path, 'B_paths': path}
7.2 效果评估
通过定期验证集测试监控训练进展,关键步骤:
- 反归一化处理
- Lab→RGB转换
- 生成效果可视化对比
八、评估指标
- SSIM (结构相似性): 这是一个广泛使用的指标,衡量两幅图像在结构上的相似度。值范围从0到1,越高越好。SSIM>0.85通常被认为是高质量的结果。
- PSNR (峰值信噪比): 这个指标衡量的是图像重建的质量,单位为dB。通常,PSNR>30dB被认为是高质量的。在着色任务中,25-35dB通常是好的结果。
- 色彩误差: 这是我专门为着色任务添加的指标,它衡量Lab色彩空间中ab通道的平均绝对误差。这个指标直接评估了着色的准确性,而不仅仅是整体图像相似度。
- LPIPS (感知相似度): 这是一个基于深度学习的感知相似度度量,更符合人类对图像质量的判断。值越低表示感知上越相似。
- FID (Fréchet Inception Distance): 这个指标衡量生成图像的分布与真实图像分布之间的距离。它使用Inception网络提取特征,并计算特征空间中的分布差异。FID值越低越好,通常<20被认为是高质量的生成结果。
在第七章节后,我们获取到了结果图:./results/tongyong_l2ab_4/testA_35/images/
每三个图是一组,比如:
bash展开代码-rw-r--r-- 1 root root 134573 Apr 10 02:17 002_trafficScene_youxian1_000020_fake_B_rgb.png -rw-r--r-- 1 root root 132559 Apr 10 02:17 002_trafficScene_youxian1_000020_real_B_rgb.png -rw-r--r-- 1 root root 86333 Apr 10 02:17 002_trafficScene_youxian1_000020_real_A.png
real_A 是黑白图,real_B_rgb 是真实的RGB图,fake_B_rgb 是模型根据real_A进行上色得到的图。
指标就是为了评估fake_B_rgb是否能接近real_B_rgb。
为了得到评估指标,需要给容器里安装点环境:
展开代码apt update && apt install -y libgl1 pip install -r evaluation_requirements.txt # 在我自己的github项目里
运行评估脚本:
bash展开代码# 基本版本
python evaluate_basic.py --results_dir ./results/tongyong_l2ab_4/testA_35/images --output_dir ./evaluation_basic_results
# 完整版本
python evaluate_colorization.py --results_dir ./results/tongyong_l2ab_4/testA_35/images --output_dir ./evaluation_results
# 完整版本 带FID指标
python evaluate_colorization.py --results_dir ./results/tongyong_l2ab_4/testA_35/images --output_dir ./evaluation_results --use_fid
得到:
| Metric | Mean | Std | Min | Max |
|---|---|---|---|---|
| SSIM | 0.892293 | 0.087055 | 0.496115 | 0.991259 |
| PSNR | 22.315565 | 4.723317 | 9.698197 | 36.125977 |
| MSE | 682.852914 | 889.681447 | 15.866557 | 6970.447413 |
| MAE | 15.264377 | 9.815629 | 1.971761 | 66.205879 |
| Color Error | 11.004399 | 7.5067 | 1.517296 | 51.797058 |
| LPIPS | 0.193544 | 0.092814 | 0.009559 | 0.553977 |
| FID | 49.714922 | - | - | - |
模型表现不错:
- SSIM平均值: 0.892 - 非常好,接近0.9意味着生成的图像与真实图像结构相似度很高
- PSNR平均值: 22.32 dB - 对于着色任务来说是合理的值
- Color Error平均值: 11.00 - 这是在Lab色彩空间中ab通道的误差
- LPIPS平均值: 0.194 - 表示感知相似度较好(越低越好)
- FID值是49.714922,这属于中等性能水平: FID值越低越好,表示生成分布与真实分布越接近 通常FID < 20被视为非常好 FID在20-50之间被视为可接受 FID > 100通常表示生成质量较差
九、WebUI部署
启动web服务:
展开代码python colorization_app.py
网页前端使用:

十、其他理论
U-Net生成器
我们的彩色化模型采用U-Net[4]作为生成器的骨干网络。U-Net是一种编码器-解码器结构,增加了跳跃连接(skip connection)以保留细节信息。对于彩色化任务,我们采用unet_256变体,具有8个下采样层。
U-Net生成器的结构可以表示为:
具体而言,它由以下部分组成:
- 编码器路径:通过一系列卷积层和下采样操作将输入从 逐渐降维到
- 解码器路径:通过上采样和反卷积操作将特征图从 恢复到
- 跳跃连接:在对应的编码器和解码器层之间建立直接连接,帮助网络保留边缘和细节信息
具体的数学表示为:
其中 表示下采样操作, 表示上采样与特征连接操作, 是输入的L通道, 是输出的ab通道预测。
PatchGAN判别器
我们使用PatchGAN作为判别器,它仅关注局部图像块(patch)的真实性而非整体图像,这有助于保持色彩的局部一致性和纹理细节。PatchGAN判别器可以表示为:
其中输入是L通道与ab通道(真实或生成)的拼接,输出是一个 的评分图,每个位置对应一个感受野为 的图像区域。判别器包含5个卷积层,中间使用实例归一化(Instance Normalization)和LeakyReLU激活函数。
损失函数
在训练过程中,网络同时优化两个损失函数:
- 条件GAN损失:,促使生成的色彩在局部区域看起来逼真
- L1距离损失:,确保生成的色彩与真实色彩的整体一致性
对于判别器 ,我们使用标准的GAN判别器损失:
对于生成器 ,我们结合GAN损失和L1损失:
其中,我们设置 来强调色彩的准确性。
十一、镜像,代码,权重
镜像环境安装了一些别的,新的镜像名称为:kevinchina/deeplearning:2.5.1-cuda12.1-cudnn9-devel-pix2pix-webui
代码仓库:https://github.com/xxddccaa/pytorch-CycleGAN-and-pix2pix-color#
webui启动:
bash展开代码cd /ssd/xiedong/image_color
docker run --gpus device=2 --shm-size=32g -it --net host \
-v ./pytorch-CycleGAN-and-pix2pix/:/pytorch-CycleGAN-and-pix2pix/ \
-v ./unpaired_self_datasets/:/data \
kevinchina/deeplearning:2.5.1-cuda12.1-cudnn9-devel-pix2pix-webui bash
cd /pytorch-CycleGAN-and-pix2pix
python colorization_app.py


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!