https://arxiv.org/abs/2409.07429
论文标题: Agent Workflow Memory (AWM): Improving Task Success in Long-Horizon Web Navigation Tasks
1. 论文概述
本文由来自卡内基梅隆大学和麻省理工学院的研究团队提出,旨在解决基于语言模型的代理在解决复杂、长时任务时的表现不佳问题。当前代理主要依赖固定的训练样例或上下文学习,缺乏应对新任务或环境变化的灵活性。论文的主要贡献是提出了一种Agent Workflow Memory (AWM) 方法,通过从过去的任务经验中学习并提取可重用的工作流(workflow),从而指导代理完成新的任务。
要读懂一篇学术论文,需要关注以下几个关键部分,以确保对论文的核心内容和贡献有清晰的理解:
-
标题和摘要:了解论文的主题和研究问题。摘要通常概括了研究的背景、方法、主要发现和结论,是快速了解论文整体内容的起点。
-
引言:引言部分阐述了研究背景、问题的重要性以及当前领域存在的研究空白。通过阅读引言,明确论文的研究目的以及提出的假设或问题。
-
研究问题和假设:清晰了解论文要解决的具体问题,以及作者提出的假设(如果有)。这有助于把握论文的核心目标。
-
方法部分:重点了解作者采用了什么研究方法来解决问题,包括实验设计、数据收集、分析手段等。评估这些方法是否合理且适用于该问题。
-
结果部分:了解研究的主要发现是什么,以及这些结果是如何通过实验或数据分析得出的。这部分应关注数据的呈现形式和分析的结果。
-
讨论和结论:作者如何解释研究结果?这些结果对领域有什么重要性?论文提出的结论是否解决了引言中的问题?作者对未来的研究有何建议?
-
参考文献:看论文引用了哪些重要的文献,了解研究的理论基础和作者与其他研究的联系。通过参考文献,你可以追溯与该领域相关的经典研究。
-
贡献和创新点:论文在哪些方面做出了独特的贡献?与其他类似研究相比,创新点是什么?
要在Windows系统上测试IP地址 101.150.35.155 的端口 7860 是否开放,可以使用以下几种方法:
方法一:使用PowerShell的 Test-NetConnection 命令
-
打开PowerShell:
- 按
Win + X,选择 Windows PowerShell 或 Windows Terminal。
- 按
-
运行测试命令:
powershell展开代码Test-NetConnection -ComputerName 101.150.35.155 -Port 7860 -
查看结果:
- 如果端口开放,
TcpTestSucceeded会显示为True。 - 例如:
展开代码
ComputerName : 101.150.35.155 RemoteAddress : 101.150.35.155 RemotePort : 7860 InterfaceAlias : Ethernet SourceAddress : 你的本地IP TcpTestSucceeded : True
- 如果端口开放,
使用 Gradio 实现多张图片上传并显示图片名称和尺寸
在现代应用中,用户经常需要上传多张图片进行处理或分析。Gradio 是一个非常方便的 Python 库,可以快速构建交互式的 Web 界面,方便用户上传图片、输入文本等。本篇博客将介绍如何使用 Gradio 实现多张图片的上传,并在服务器端处理这些图片,输出每张图片的名称和尺寸,以验证服务器已经成功接收了这些图片。
随着光学字符识别 (OCR) 技术的不断发展,传统的 OCR 系统已无法满足日益增长的智能处理需求。在《General OCR Theory》这篇论文中,作者提出了一种新的通用 OCR 理论,称之为 OCR 2.0,并开发了 GOT(General OCR Theory)模型。GOT 模型能够处理各种类型的字符,包括常规文本、数学公式、分子结构、图表、乐谱等,并支持多种 OCR 任务,如场景文本、文档级 OCR 和格式化输出。
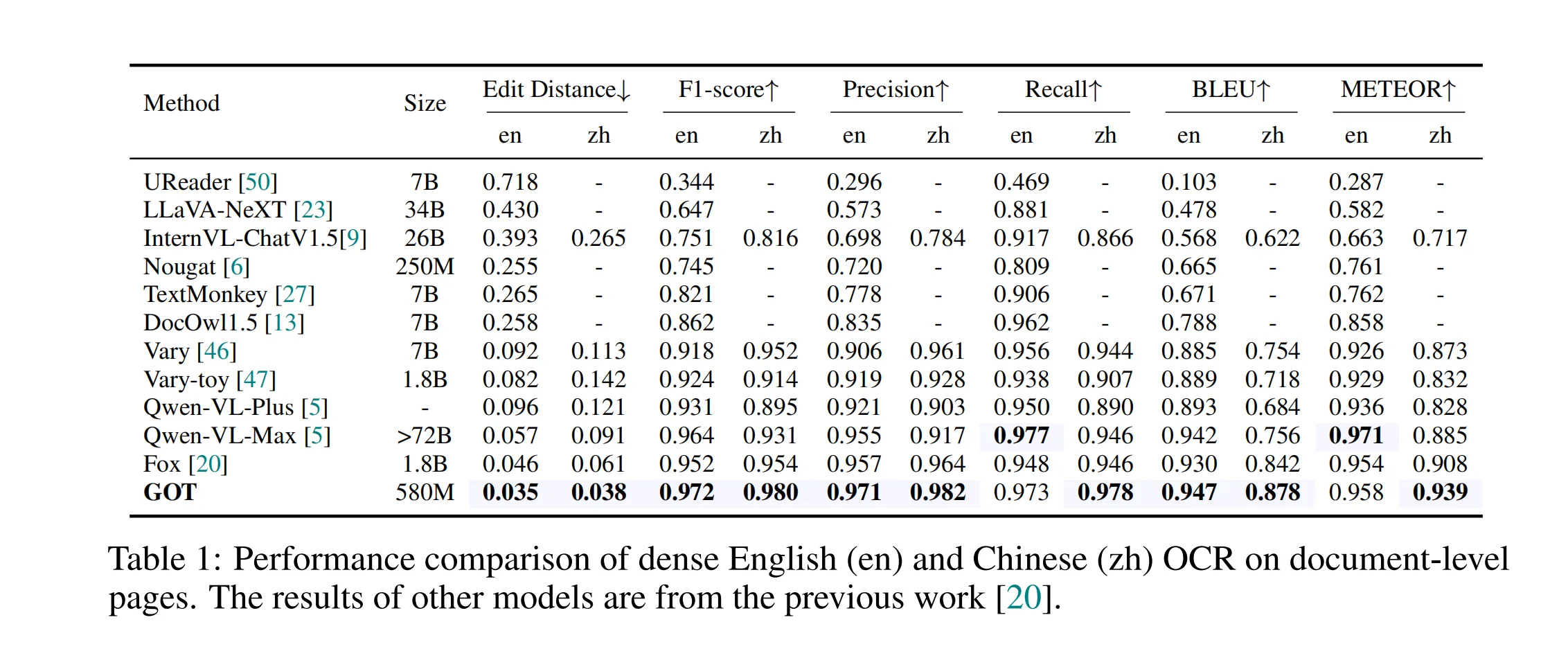
1. 引言
在深度学习模型训练过程中,随着模型的复杂度增加和数据量的增多,单机单卡的计算能力逐渐无法满足需求。多机多卡分布式训练可以显著缩短训练时间,并提高训练效率。本文将介绍如何构建一个适合的多机多卡训练环境,利用Kubernetes(K8s)来进行分布式训练资源的管理与调度。
多机多卡深度学习训练:Python torch.distributed.launch、torchrun、accelerate 和 deepspeed 对比解析
随着深度学习模型规模的迅速增长,单机单卡的计算能力往往不足以满足训练需求。在多机多卡的环境中,分布式训练技术成为了加速训练的关键。本文将从工具角度出发,探讨几种常用的分布式训练工具:python -m torch.distributed.launch、torchrun、accelerate 和 deepspeed,分析它们的特点、优势、底层架构、如何使用以及是否可以交互使用。类似的还有Horovod、Ray Train,这里不介绍。
在深度学习、大规模并行计算等高性能计算场景中,多机多卡训练(multi-node, multi-GPU training)是关键技术之一,它能够大幅提升训练速度并处理超大规模数据集。然而,在多机多卡的分布式训练中,如何实现各个计算单元之间的高效通信和数据传输是一个非常重要的问题。本文将基于以下几个技术点来详细探讨如何构建多机多卡的训练环境:NVLink、RDMA、NCCL_IB_DISABLE,并分析这些技术如何在分布式训练中确保高效的数据通信。
FakeLocation 可以辅助Android的一些便捷开发,但有时候打开后就有强制更新弹窗,很烦人。
看b站教程,可以用magisk+lsposed 里阻止弹窗,我以小米6测试一下如何使用。
LSPosed 安装教程的总纲是这样: https://github.com/LSPosed/LSPosed/wiki/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8
如何评估大语言模型(LLM)性能
训练了一个大型语言模型(LLM)后,接下来的关键问题就是如何评估模型的好坏。评估LLM的性能不仅涉及到对模型的语言生成能力的测量,还包括对其通用性、鲁棒性和适应性等多个维度的考察。
本文将从以下几个方面探讨评估LLM的常用方法,并介绍各种评估指标与实践技巧。
