如何用程序批量下载小红书的图片?
目录
如何使用MediaCrawler快速下载图片
作为一名图像算法工程师,怎么能没有图片资源呢?今天,我要介绍一个能快速下载图片的方法,仅供学习使用,请勿用于其他用途。
下载项目
首先,从GitHub下载项目:MediaCrawler
安装依赖
安装所需的Python依赖库:
bash展开代码pip install -r requirements.txt
安装Playwright浏览器驱动:
bash展开代码playwright install
运行爬虫程序
项目默认没有开启评论爬取模式,如果需要爬取评论,请在 config/base_config.py 中将 ENABLE_GET_COMMENTS 变量设置为 True。一些其他支持的功能,也可以在 config/base_config.py 查看,文件中有中文注释。
搜索帖子并爬取信息与评论
bash展开代码python main.py --platform xhs --lt qrcode --type search
获取指定帖子的信息与评论
bash展开代码python main.py --platform xhs --lt qrcode --type detail
打开对应APP扫二维码登录
bash展开代码python main.py --help
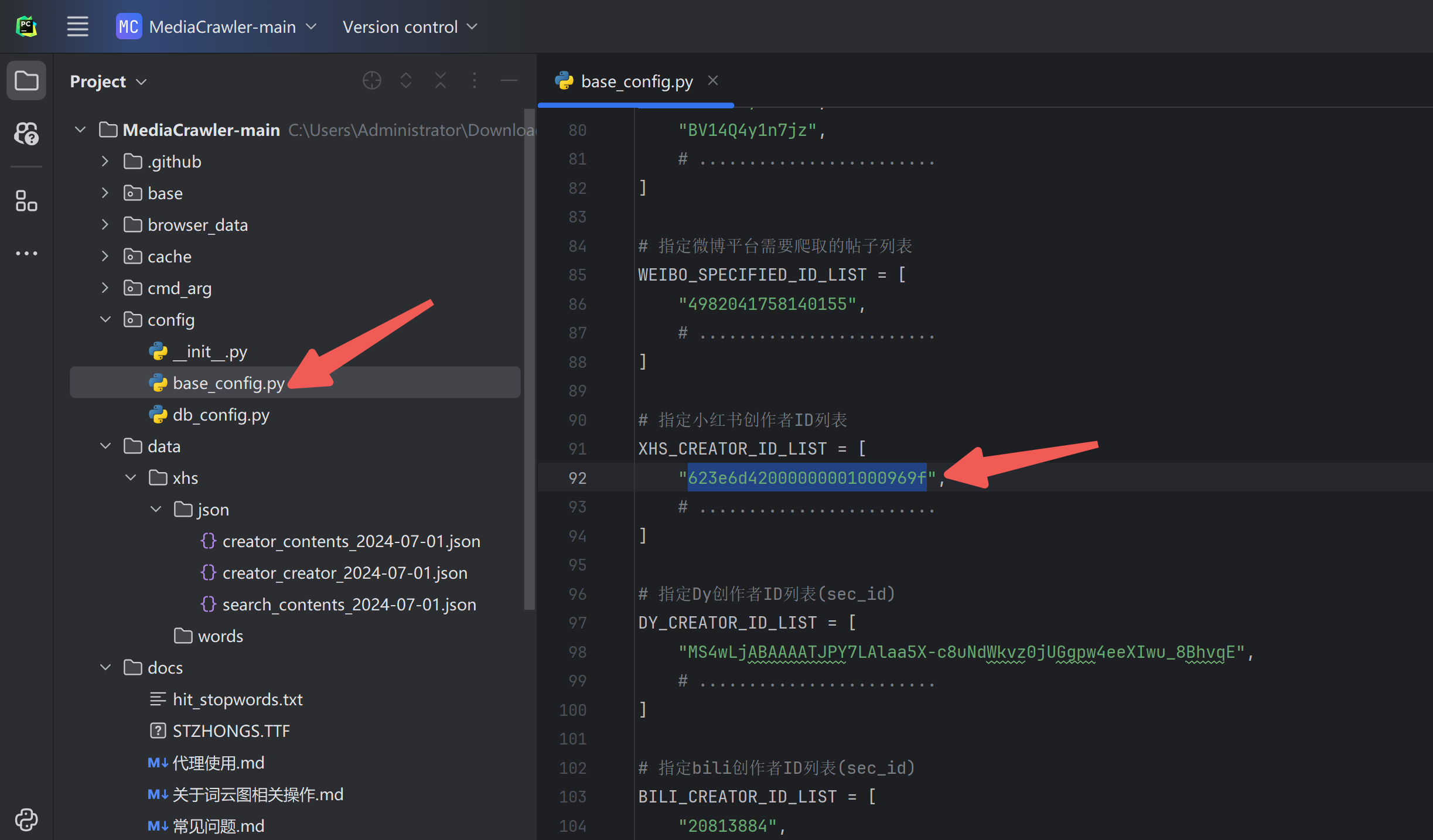
例如,我想下载某个创作者的全部图片,可以这样设置:
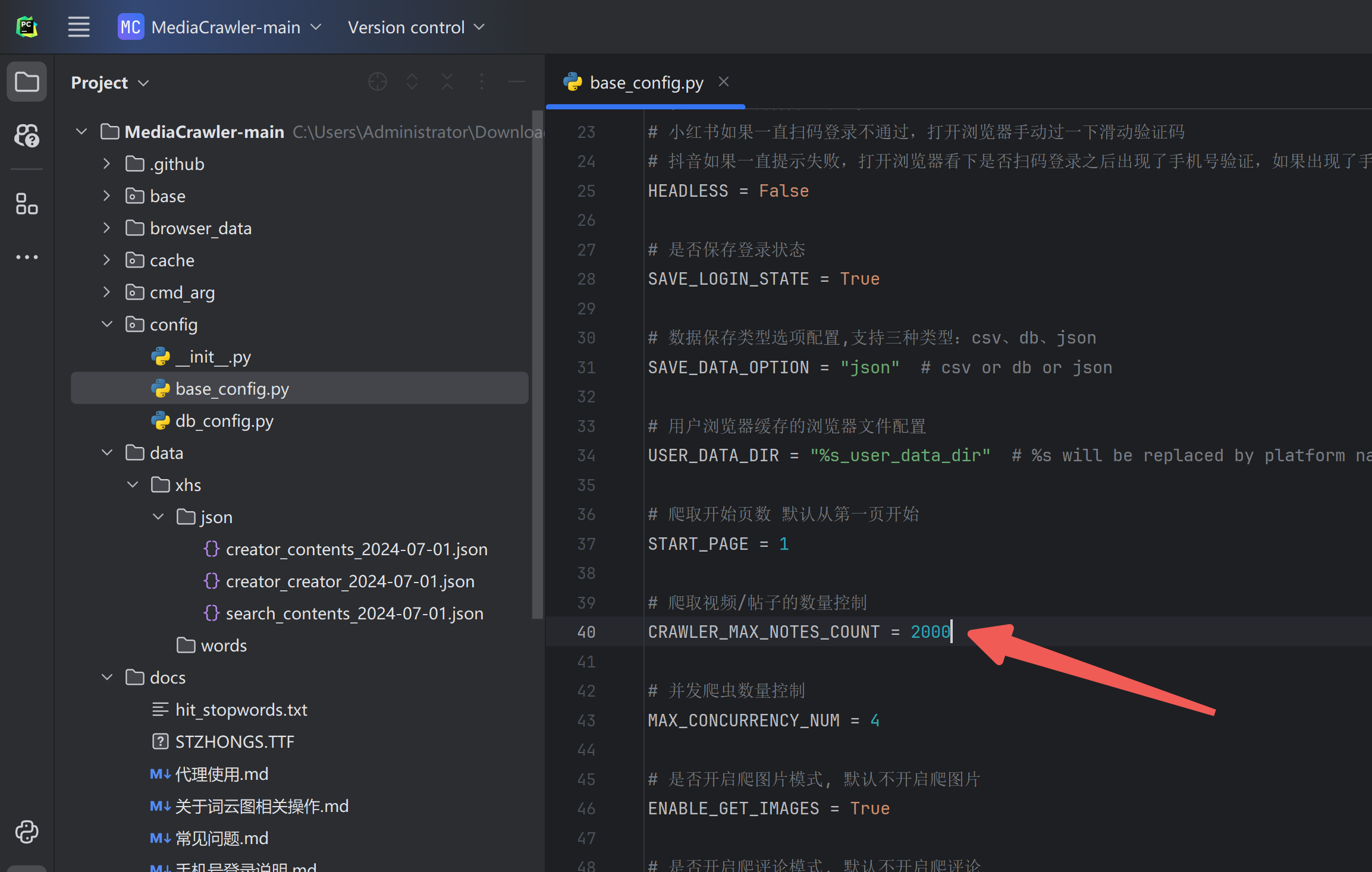
再设置最大下载量:
在命令行中执行下载:
bash展开代码python main.py --platform xhs --type creator > output.log 2>&1
所有日志会打印到 output.log 文件中。
提取图片URL
接下来,我们需要编写一个脚本来从日志中提取图片URL。以下是一个Python脚本示例:
python展开代码import re
def extract_image_urls(log_file, output_file):
with open(log_file, 'r', encoding='utf-16LE') as f:
log_content = f.read()
# 删除\r\n
log_content = log_content.replace('\r', '')
log_content = log_content.replace('\n', '')
# 使用正则表达式提取'image_list'中的URL
image_url_pattern = re.compile(r"'image_list':\s*'([^']+)'")
matches = image_url_pattern.findall(log_content)
# 分割每个'image_list'字段中的URL,并写入文件
with open(output_file, 'w', encoding='utf-8') as f:
for match in matches:
urls = match.split(',')
for url in urls:
f.write(url.strip() + '\n')
# 调用函数,分析日志文件并提取图片URL
extract_image_urls('output.log', 'image.txt')
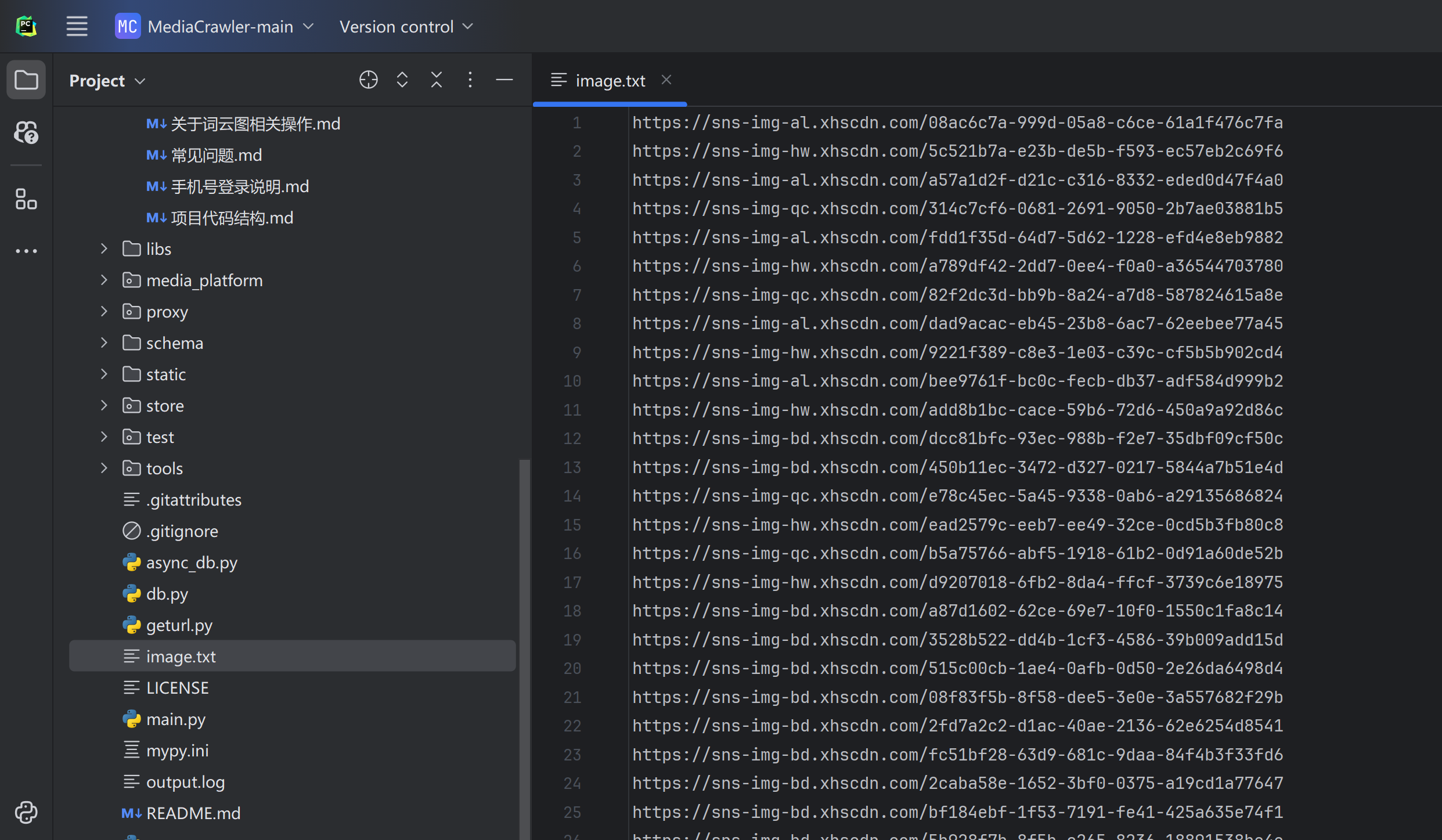
这样,我们就能得到一个包含所有图片URL的 image.txt 文件:
通过这种方法,我们可以快捷地下载所需的图片资源,方便后续的图像处理和算法开发。
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录