https://arxiv.org/abs/1703.06870
https://blog.roboflow.com/mask-rcnn/
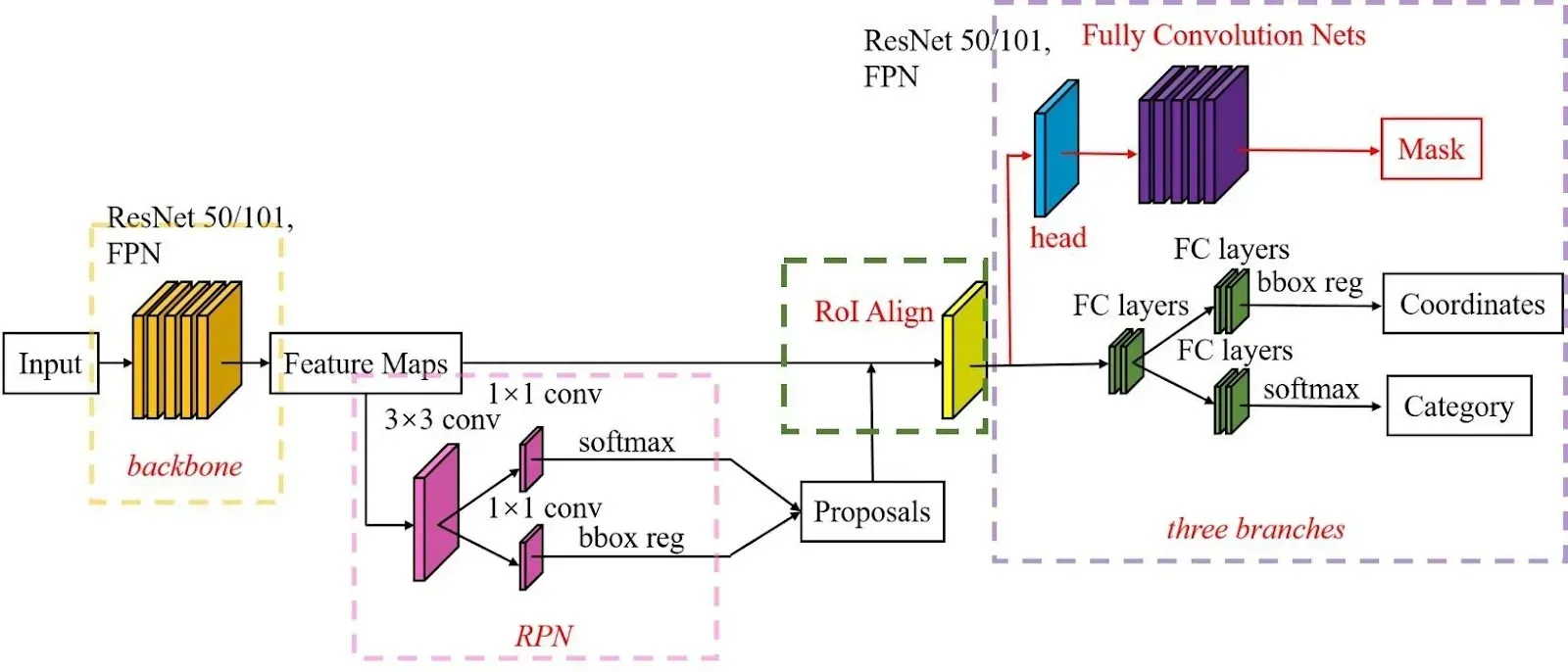
Mask R-CNN 是一种用于实例分割(Instance Segmentation)的深度学习模型,它在 Faster R-CNN 的基础上增加了对每个目标生成像素级掩码(Mask)的功能。因此,Mask R-CNN 的损失函数由以下几个部分组成:
-
分类损失(Classification Loss, Lcls)
这是 Faster R-CNN 中的目标分类损失,用于预测每个候选区域(Region Proposal)属于哪个类别。通常使用交叉熵损失(Cross-Entropy Loss)来计算。
-
边界框回归损失(Bounding Box Regression Loss, Lbox)
这是 Faster R-CNN 中的边界框回归损失,用于调整候选区域的位置和大小,使其更准确地包围目标。通常使用平滑 L1 损失(Smooth L1 Loss)来计算。
-
掩码分支损失(Mask Loss, Lmask)
Mask R-CNN 增加了一个额外的分支,用于生成每个目标的像素级掩码。对于每个候选区域,掩码分支会输出一个 K×m×m 的张量,其中 K 是类别数,m×m 是掩码的分辨率。掩码损失通常使用逐像素的二值交叉熵损失(Binary Cross-Entropy Loss)来计算,且只针对真实类别对应的掩码进行监督。
总体损失函数
Mask R-CNN 的总体损失函数可以表示为:
L=Lcls+Lbox+Lmask
详细说明:
-
分类损失 Lcls:
Lcls=−Ncls1i=1∑Ncls[yilog(pi)+(1−yi)log(1−pi)]
其中:
- Ncls 是分类样本的数量。
- yi 是第 i 个样本的真实标签(0 或 1)。
- pi 是模型预测的第 i 个样本属于正类的概率。
-
边界框回归损失 Lbox:
Lbox=Nreg1i=1∑NregsmoothL1(ti−ti∗)
其中:
- Nreg 是边界框回归样本的数量。
- ti 是预测的边界框参数(如中心点坐标、宽高)。
- ti∗ 是真实边界框参数。
- smoothL1(x) 是平滑 L1 损失函数,定义为:
smoothL1(x)={0.5x2∣x∣−0.5if ∣x∣<1otherwise
-
掩码分支损失 Lmask:
掩码分支的损失是对每个像素的二值交叉熵损失求平均。假设对于某个候选区域的真实类别为 k,则掩码分支的损失为:
Lmask=−Nmask1i=1∑Nmask[Milog(Pik)+(1−Mi)log(1−Pik)]
其中:
- Nmask 是掩码中像素的总数。
- Mi 是第 i 个像素的真实掩码值(0 或 1)。
- Pik 是模型预测的第 i 个像素属于类别 k 的概率。
需要注意的是,掩码分支的损失只对真实类别 k 对应的掩码进行计算,其他类别的掩码不会参与损失计算。
本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。
许可协议。转载请注明出处!

