目录
1. qwen vl里有一些标记
在qwen vl里有一些标记,但其实用不着:
- •
<|endoftext|>:表示文本的结束。 - •
<|im_start|>和<|im_end|>:可能用于标记输入/输出的开始和结束。 - •
<|object_ref_start|>和<|object_ref_end|>:可能用于标记对象引用的开始和结束。 - •
<|box_start|>和<|box_end|>:可能用于标记一个“框”结构的开始和结束。 - •
<|quad_start|>和<|quad_end|>:可能用于标记一个“四边形”结构的开始和结束。 - •
<|vision_start|>和<|vision_end|>:可能用于标记视觉相关内容的开始和结束。 - •
<|vision_pad|>、<|image_pad|>、<|video_pad|>:可能用于填充视觉、图像或视频内容。 - •
<tool_call>和</tool_call>:可能用于标记工具调用的开始和结束。 - •
<|fim_prefix|>、<|fim_middle|>、<|fim_suffix|>、<|fim_pad|>:可能用于填充或标记某些特定格式的文本(如代码补全)。 - •
<|repo_name|>和<|file_sep|>:可能用于标记仓库名称或文件分隔符。
json展开代码[
{
"role": "user",
"content": [
{
"type": "image",
"image": "path_to_image.jpg"
},
{
"type": "text",
"text": "图中的杯子的坐标在哪里?"
}
]
},
{
"role": "assistant",
"content": "<|object_ref_start|>杯子<|object_ref_end|><|box_start|>(0.456,0.387),(0.702,0.789)<|box_end|>"
}
]
可以看编码原理:
https://zhuanlan.zhihu.com/p/12081484294
2. 镜像
kevinchina/deeplearning
环境需要有这个多机多卡支持提供用户空间 API,用于直接访问 InfiniBand/RDMA(远程直接内存访问) 硬件(如 Mellanox 网卡)。
展开代码sudo apt-get update sudo apt-get install libibverbs1
3. 数据集
dataset_info
在/app/data里修改文件vim dataset_info.json:
json展开代码{
"xdx": {
"file_name": "xdx.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}
}
样本组织
"mllm_demo_data/1.jpg" 是相对于这个json的,最好直接用绝对路径。
json展开代码[
{
"messages": [
{
"content": "<image> Who are they?",
"role": "user"
},
{
"content": "They're Kane and Gretzka from Bayern Munich.",
"role": "assistant"
}
],
"images": [
"mllm_demo_data/1.jpg"
]
}
]
4. 全量微调
全量微调:https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/train_full/qwen2vl_full_sft.yaml
bash展开代码### model
model_name_or_path: /Qwen2.5-VL-7B-Instruct
image_max_pixels: 1048576
video_max_pixels: 16384
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: full
freeze_vision_tower: true # choices: [true, false]
freeze_multi_modal_projector: true # choices: [true, false]
freeze_language_model: false # choices: [true, false]
deepspeed: examples/deepspeed/ds_z3_config.json # choices: [ds_z0_config.json, ds_z2_config.json, ds_z3_config.json]
### dataset
dataset: xd
template: qwen2_vl
cutoff_len: 4096
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 32
dataloader_num_workers: 8
### output
output_dir: output/saves/qwen2_vl-7b/full/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
### train
per_device_train_batch_size: 2
gradient_accumulation_steps: 2
learning_rate: 1.0e-5
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
# resume_from_checkpoint: null
### eval
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500
代码:
https://github.com/hiyouga/LLaMA-Factory/blob/main/src/llamafactory/hparams/model_args.py#L60
bash展开代码 image_max_pixels: int = field(
default=768 * 768,
metadata={"help": "The maximum number of pixels of image inputs."},
)
5. 多机多卡训练
镜像:
展开代码kevinchina/deeplearning:llamafactory20250311-3
运行命令:
展开代码cd /app && FORCE_TORCHRUN=1 \ NNODES=5 \ NODE_RANK=${RANK} \ MASTER_ADDR=${MASTER_ADDR} \ MASTER_PORT=${MASTER_PORT} \ llamafactory-cli train examples/train_full/qwen2vl_full_sft.yaml
或者:
200w 数据,
max_samples ,一轮训练最多 max_samples 个样本
num_train_epochs, 训练num_train_epochs 轮
每隔 save_steps 轮保存一次模型。
展开代码cd /app && FORCE_TORCHRUN=1 \ NNODES=5 \ NODE_RANK=${RANK} \ MASTER_ADDR=${MASTER_ADDR} \ MASTER_PORT=${MASTER_PORT} \ llamafactory-cli train \ --model_name_or_path /Qwen2.5-VL-7B-Instruct \ --image_max_pixels 1048576 \ --video_max_pixels 16384 \ --trust_remote_code true \ --stage sft \ --do_train true \ --finetuning_type full \ --freeze_vision_tower true \ --freeze_multi_modal_projector true \ --freeze_language_model false \ --deepspeed examples/deepspeed/ds_z3_config.json \ --dataset xdx_b \ --template qwen2_vl \ --cutoff_len 4096 \ --max_samples 10000 \ --overwrite_cache true \ --preprocessing_num_workers 32 \ --dataloader_num_workers 8 \ --output_dir output/saves/qwen2_vl-7b/full/sft \ --logging_steps 1 \ --save_steps 10 \ --plot_loss true \ --overwrite_output_dir true \ --save_only_model false \ --per_device_train_batch_size 4 \ --gradient_accumulation_steps 2 \ --learning_rate 1.0e-5 \ --num_train_epochs 1000.0 \ --lr_scheduler_type cosine \ --warmup_ratio 0.1 \ --bf16 true \ --ddp_timeout 180000000
环境变量: key CUDA_DEVICE_MAX_CONNECTIONS value 1 key NCCL_DEBUG value INFO key NCCL_IB_DISABLE value 0
打开 RDMA
挂载:
/app/data
/app/examples
/img_datasets
6. 日志
bash展开代码root@job-367d180c78394c1c85-master-0:/app/output/saves/qwen2_vl-7b/full/sft# cat trainer_log.jsonl
{"current_steps": 1, "total_steps": 31000, "loss": 1.572, "lr": 3.2258064516129035e-09, "epoch": 0.031746031746031744, "percentage": 0.0, "elapsed_time": "0:00:13", "remaining_time": "4 days, 20:53:07"}
{"current_steps": 2, "total_steps": 31000, "loss": 1.59, "lr": 6.451612903225807e-09, "epoch": 0.06349206349206349, "percentage": 0.01, "elapsed_time": "0:00:20", "remaining_time": "3 days, 18:00:50"}
{"current_steps": 3, "total_steps": 31000, "loss": 1.6075, "lr": 9.67741935483871e-09, "epoch": 0.09523809523809523, "percentage": 0.01, "elapsed_time": "0:00:28", "remaining_time": "3 days, 9:01:32"}
{"current_steps": 4, "total_steps": 31000, "loss": 1.5961, "lr": 1.2903225806451614e-08, "epoch": 0.12698412698412698, "percentage": 0.01, "elapsed_time": "0:00:35", "remaining_time": "3 days, 4:40:52"}
{"current_steps": 5, "total_steps": 31000, "loss": 1.5595, "lr": 1.6129032258064518e-08, "epoch": 0.15873015873015872, "percentage": 0.02, "elapsed_time": "0:00:43", "remaining_time": "3 days, 3:21:35"}
{"current_steps": 6, "total_steps": 31000, "loss": 1.5877, "lr": 1.935483870967742e-08, "epoch": 0.19047619047619047, "percentage": 0.02, "elapsed_time": "0:00:51", "remaining_time": "3 days, 1:38:07"}
{"current_steps": 7, "total_steps": 31000, "loss": 1.5789, "lr": 2.2580645161290328e-08, "epoch": 0.2222222222222222, "percentage": 0.02, "elapsed_time": "0:00:59", "remaining_time": "3 days, 0:50:23"}
{"current_steps": 8, "total_steps": 31000, "loss": 1.6001, "lr": 2.5806451612903228e-08, "epoch": 0.25396825396825395, "percentage": 0.03, "elapsed_time": "0:01:06", "remaining_time": "2 days, 23:40:12"}
{"current_steps": 9, "total_steps": 31000, "loss": 1.5984, "lr": 2.9032258064516135e-08, "epoch": 0.2857142857142857, "percentage": 0.03, "elapsed_time": "0:01:14", "remaining_time": "2 days, 22:48:03"}
{"current_steps": 10, "total_steps": 31000, "loss": 1.584, "lr": 3.2258064516129035e-08, "epoch": 0.31746031746031744, "percentage": 0.03, "elapsed_time": "0:01:21", "remaining_time": "2 days, 22:06:42"}
{"current_steps": 11, "total_steps": 31000, "loss": 1.5979, "lr": 3.548387096774194e-08, "epoch": 0.3492063492063492, "percentage": 0.04, "elapsed_time": "0:02:09", "remaining_time": "4 days, 5:05:22"}
{"current_steps": 12, "total_steps": 31000, "loss": 1.5929, "lr": 3.870967741935484e-08, "epoch": 0.38095238095238093, "percentage": 0.04, "elapsed_time": "0:02:16", "remaining_time": "4 days, 2:08:08"}
{"current_steps": 13, "total_steps": 31000, "loss": 1.6045, "lr": 4.1935483870967746e-08, "epoch": 0.4126984126984127, "percentage": 0.04, "elapsed_time": "0:02:24", "remaining_time": "3 days, 23:27:43"}
{"current_steps": 14, "total_steps": 31000, "loss": 1.5795, "lr": 4.5161290322580656e-08, "epoch": 0.4444444444444444, "percentage": 0.05, "elapsed_time": "0:02:31", "remaining_time": "3 days, 21:26:10"}
{"current_steps": 15, "total_steps": 31000, "loss": 1.5797, "lr": 4.838709677419355e-08, "epoch": 0.47619047619047616, "percentage": 0.05, "elapsed_time": "0:02:39", "remaining_time": "3 days, 19:27:37"}
{"current_steps": 16, "total_steps": 31000, "loss": 1.5883, "lr": 5.1612903225806456e-08, "epoch": 0.5079365079365079, "percentage": 0.05, "elapsed_time": "0:02:46", "remaining_time": "3 days, 17:41:24"}
{"current_steps": 17, "total_steps": 31000, "loss": 1.5919, "lr": 5.483870967741936e-08, "epoch": 0.5396825396825397, "percentage": 0.05, "elapsed_time": "0:02:54", "remaining_time": "3 days, 16:10:27"}
{"current_steps": 18, "total_steps": 31000, "loss": 1.5795, "lr": 5.806451612903227e-08, "epoch": 0.5714285714285714, "percentage": 0.06, "elapsed_time": "0:03:01", "remaining_time": "3 days, 14:47:02"}
{"current_steps": 19, "total_steps": 31000, "loss": 1.5692, "lr": 6.129032258064517e-08, "epoch": 0.6031746031746031, "percentage": 0.06, "elapsed_time": "0:03:09", "remaining_time": "3 days, 13:45:16"}
{"current_steps": 20, "total_steps": 31000, "loss": 1.5811, "lr": 6.451612903225807e-08, "epoch": 0.6349206349206349, "percentage": 0.06, "elapsed_time": "0:03:16", "remaining_time": "3 days, 12:37:43"}
{"current_steps": 21, "total_steps": 31000, "loss": 1.5902, "lr": 6.774193548387097e-08, "epoch": 0.6666666666666666, "percentage": 0.07, "elapsed_time": "0:03:59", "remaining_time": "4 days, 2:18:09"}
7. 损失
对于简单提示词的训练结果:
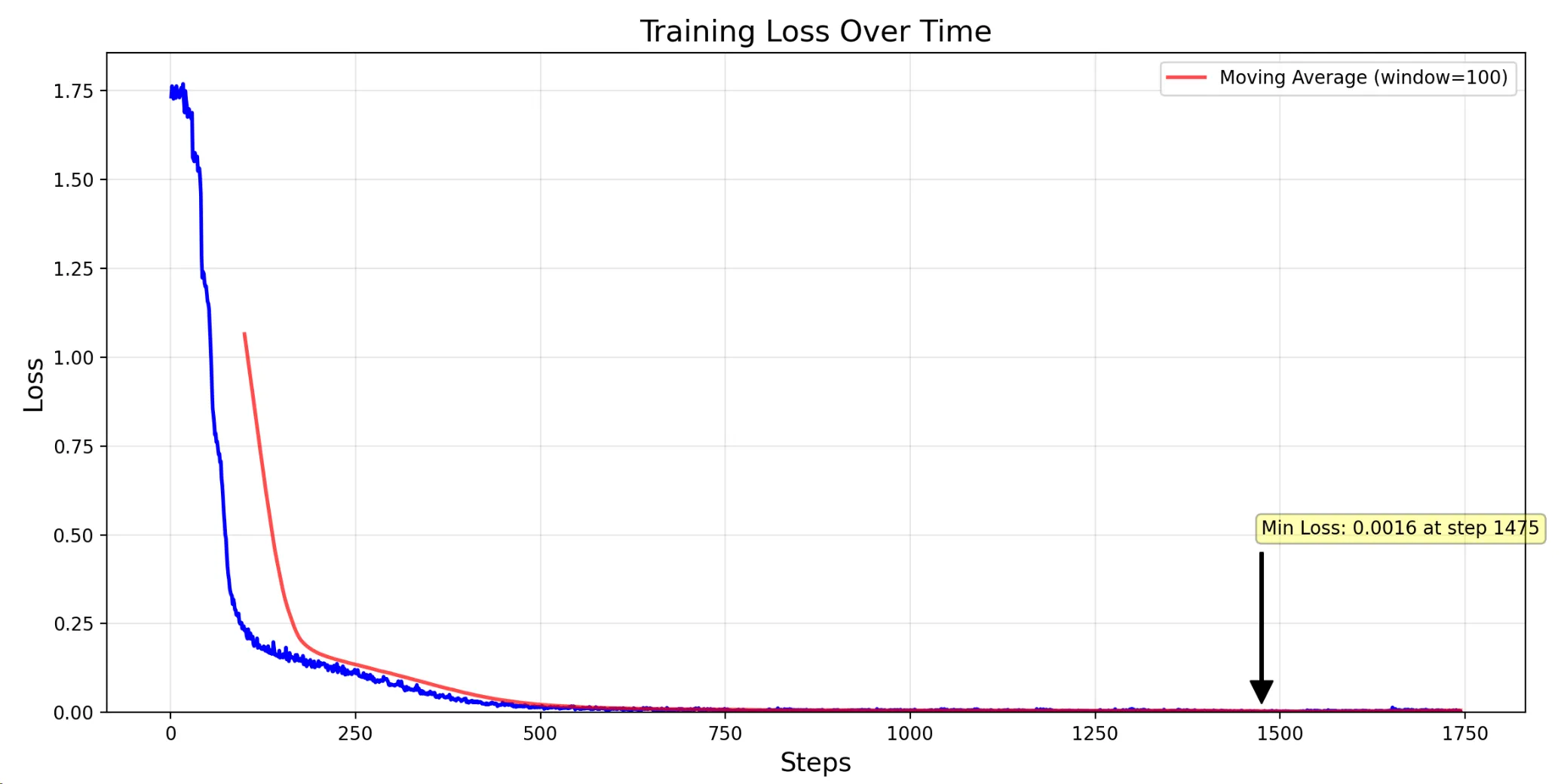
8. 导出模型
多机多卡训练的模型被切片了,不好加载,可以用 export 进行导出,指令如下:
展开代码llamafactory-cli export \ --model_name_or_path /Qwen2-VL-Any \ --export_dir /path/to/export \ --export_size 5 \ --export_device auto \ --export_legacy_format false # 确保使用safetensors格式
9. 推理部署
展开代码docker run -it \ --gpus '"device=7"' \ --shm-size 64g \ -p 8000:8000 \ -v /data/xiedong/groundding_simple_model:/Qwen2-VL-Any \ kevinchina/deeplearning:llamafactory20250311-3 # 启动 vllm vllm serve /Qwen2-VL-Any --max-model-len 16384 --pipeline-parallel-size 1 --gpu_memory_utilization 0.75 --mm-processor-kwargs '{"min_pixels": 784, "max_pixels": 2352000, "fps": 1}' --limit-mm-per-prompt "image=2,video=1"
访问代码:
展开代码import requests import json import re from PIL import Image import base64 from io import BytesIO def analyze_ui_element(image, query_type, query_data): """ Analyze UI elements in an image based on different query types. Args: image (PIL.Image): The image to analyze query_type (str): Type of query - 'interaction_point', 'bbox', or 'semantic' query_data (dict): Data for the query - coordinates, bounding box, or semantic label Returns: dict: Analysis result with interaction point, bounding box and semantic label """ # Convert image to base64 format buffered = BytesIO() image.save(buffered, format="JPEG") img_str = base64.b64encode(buffered.getvalue()).decode("utf-8") image_content = { "type": "image_url", "image_url": {"url": f"data:image;base64,{img_str}"} } # Prepare prompt based on query type if query_type == "interaction_point": prompt = f"<image>\n\n{{\"interaction_point\": {{\"x\": {query_data['x']}, \"y\": {query_data['y']}}}}}" elif query_type == "bbox": prompt = f"<image>\n\n{{\"bbox\": {{\"x1\": {query_data['x1']}, \"y1\": {query_data['y1']}, \"x2\": {query_data['x2']}, \"y2\": {query_data['y2']}}}}}" elif query_type == "semantic": prompt = f"<image>\n\n{{\"semantic\": \"{query_data}\"}}" else: raise ValueError("Invalid query type. Must be 'interaction_point', 'bbox', or 'semantic'") # Prepare request data req_data = { "model": "/Qwen2-VL-Any", "messages": [ { "role": "user", "content": [ { "type": "text", "text": prompt }, image_content ] } ], "max_tokens": 2048, "temperature": 0.1 } # Send POST request to OpenAI compatible API response = requests.post( "http://10.150.72.28:8000/v1/chat/completions", json=req_data, headers={"Authorization": "Bearer no-key-required"} ) # Process response if response.status_code == 200: output_text = response.json()["choices"][0]["message"]["content"] # Parse the JSON response try: data_dict = json.loads(output_text.strip()) return data_dict except json.JSONDecodeError: return {"error": "Failed to parse API response", "raw_response": output_text} else: return {"error": f"API request failed, status code: {response.status_code}", "response": response.text} # Example usage if __name__ == "__main__": # Example 1: Query by interaction point image_path = "example.jpg" image = Image.open(image_path) # Example with interaction point query interaction_point = {"x": 51, "y": 261} result1 = analyze_ui_element(image, "interaction_point", interaction_point) print("Example 1 - Query by interaction point:") print(json.dumps(result1, indent=2, ensure_ascii=False)) # Example 2: Query by bounding box bbox = {"x1": 33, "y1": 239, "x2": 66, "y2": 262} result2 = analyze_ui_element(image, "bbox", bbox) print("\nExample 2 - Query by bounding box:") print(json.dumps(result2, indent=2, ensure_ascii=False)) # Example 3: Query by semantic label semantic_label = "文本-地址" result3 = analyze_ui_element(image, "semantic", semantic_label) print("\nExample 3 - Query by semantic label:") print(json.dumps(result3, indent=2, ensure_ascii=False))


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!