目录
传统专家混合模型(Mixture-of-Experts, MoE)在 Transformer 中的实现
在标准 Transformer 模型中,每一层包含一个自注意力模块(Self-Attention)和一个前馈神经网络(FFN)。MoE 的核心思想是用多个专家(Expert)替代 FFN,每个专家本身也是一个 FFN,但通过动态路由机制(门控网络)选择对每个输入 token 最相关的少数专家进行计算。这种设计可以在不显著增加计算量的情况下,大幅提升模型容量。
MoE 的架构设计
1. 标准 Transformer 模块
标准 Transformer 层的计算流程如下:
- 自注意力:
- 前馈网络:
2. 用 MoE 替代 FFN
在 MoE 化的 Transformer 中,部分 FFN 层被替换为 MoE 层(通常每隔几层替换一次)。MoE 层的计算步骤如下:
(1)专家定义
- 每个 MoE 层包含 个专家,每个专家 的结构与标准 FFN 相同。
(2)门控机制(Gating Mechanism)
- 对每个输入 token ,计算其与所有专家的“亲和度”(Affinity):
其中 是第 个专家的质心向量(可学习参数)。
(3)稀疏路由(Sparse Routing)
- 选择亲和度最高的 个专家(通常 或 ):
(4)加权输出
- 对选中的专家输出进行加权求和,并与残差连接结合:
关键特性
1. 计算效率
- 稀疏性:每个 token 仅由 个专家处理(而非所有 个),保持计算量与标准 FFN 接近。例如,当 、 时,计算量约为标准 FFN 的 2 倍(假设每个专家的参数量与 FFN 相同)。
2. 动态路由
- 自适应分配:门控网络根据输入 token 的语义动态选择专家。例如,某些专家可能擅长处理名词,而另一些擅长处理动词。
3. 模型容量扩展
- 参数规模:MoE 层的参数量为 ,但计算量仅与 相关,实现了高效的参数扩展。
挑战与优化
-
负载均衡(Load Balancing)
- 需避免某些专家被过度使用(如通过辅助损失函数惩罚不均衡的路由)。
-
训练稳定性
- 稀疏路由可能导致梯度传播不稳定,需结合动态路由调整策略。
-
通信开销(分布式训练)
- 不同专家可能分布在不同的设备上,需优化跨设备数据传输。
示例代码(简化版)
python展开代码class MoELayer(nn.Module):
def __init__(self, num_experts, hidden_size, expert_size, k=1):
super().__init__()
self.experts = nn.ModuleList([FFN(hidden_size, expert_size) for _ in range(num_experts)])
self.gate = nn.Linear(hidden_size, num_experts) # 门控网络
self.k = k
def forward(self, x):
# 计算亲和度
logits = self.gate(x) # [batch_size, seq_len, num_experts]
scores = torch.softmax(logits, dim=-1)
# 选择 Top-K 专家
topk_scores, topk_indices = torch.topk(scores, self.k, dim=-1) # [batch, seq_len, k]
# 稀疏计算(仅用选中的专家)
outputs = []
for i in range(self.k):
expert_idx = topk_indices[:, :, i]
expert_output = self.experts[expert_idx](x) # 伪代码,需具体实现
outputs.append(expert_output * topk_scores[:, :, i].unsqueeze(-1))
return sum(outputs) + x # 加权求和 + 残差连接
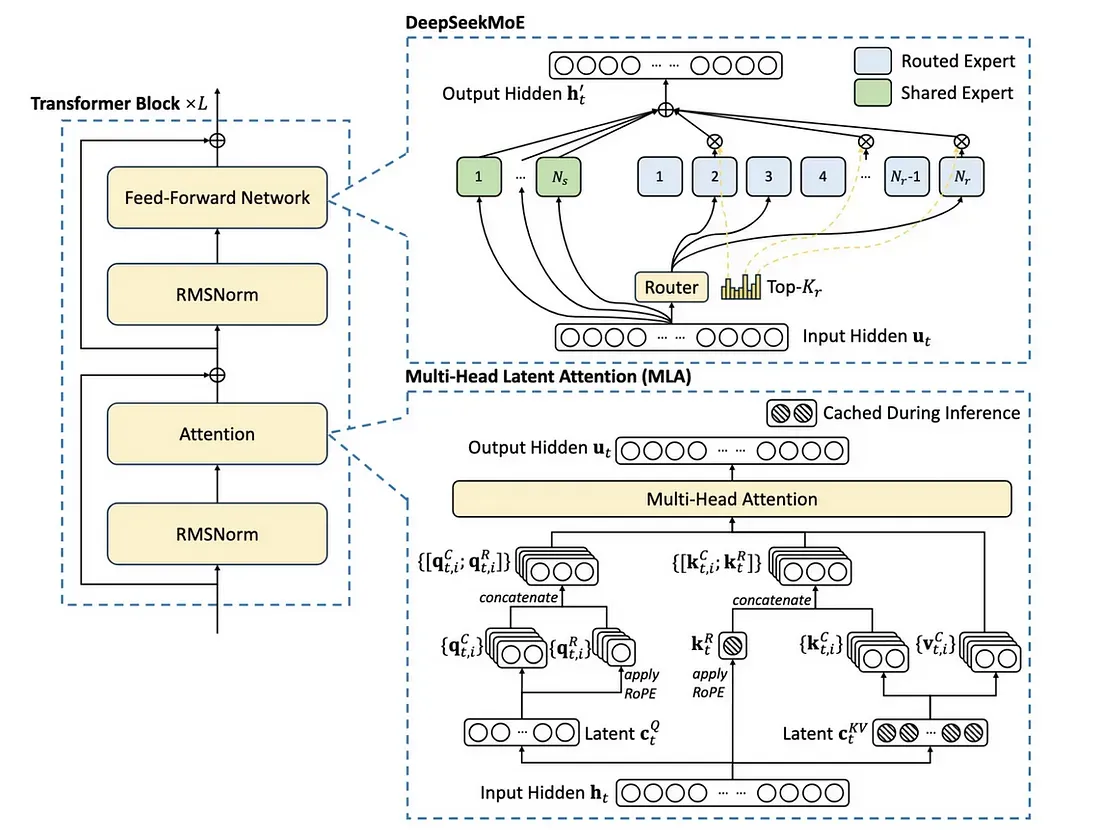
DeepSeekMoE
下图是DeepSeekMoE 的示意图。子图(a)展示了采用传统 top-2 路由策略的 MoE 层。子图(b)说明了细粒度专家分割策略。随后,子图(c)展示了共享专家隔离策略的集成,构成了完整的 DeepSeekMoE 架构。值得注意的是,在这三种架构中,专家参数的数量和计算成本保持不变。
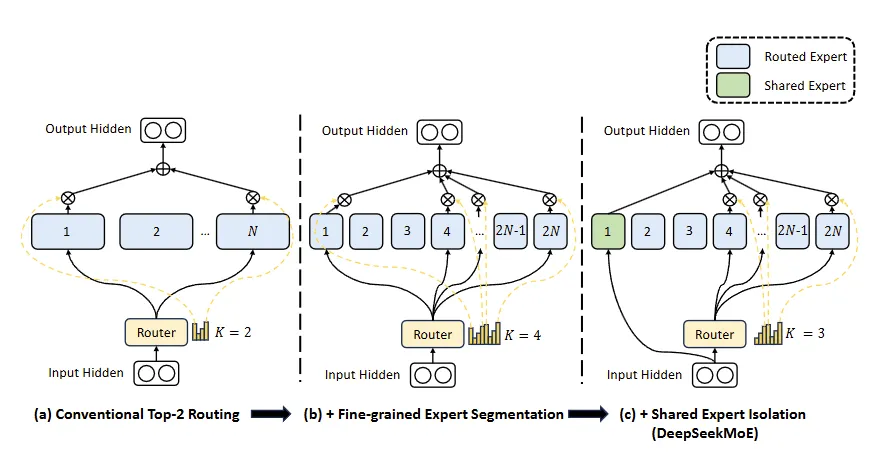
DeepSeekMoE 是在传统混合专家(MoE)架构上的创新改进,通过细粒度专家分割和共享专家隔离两大核心策略,显著提升模型的专业化能力与参数效率,同时保持计算成本不变。以下是其核心设计理念与技术实现:
一、细粒度专家分割(Fine-Grained Expert Segmentation)
1. 动机
- 问题:传统 MoE 中,每个专家(FFN)参数量较大,但每个 token 仅激活少量专家(如 Top-2)。这导致单个专家需学习多种类型知识,难以充分专业化。
- 解法:将大专家拆分为多个小专家,允许每个 token 激活更多专家组合,促进知识分解与专业化学习。
2. 实现
- 专家拆分:
将每个原始专家 FFN 的中间隐藏层维度缩小为原来的 ,分割为 个更小的子专家。例如,原 FFN 中间层维度为 ,分割后每个子专家维度为 。 - 激活策略调整:
每个 token 激活的子专家数从 增加到 ,但每个子专家的计算量降为 ,总计算量保持不变。
公式:其中 仅对 Top- 专家非零, 为总子专家数。
3. 优势
- 组合灵活性爆炸式增长:
例如,当 个专家拆分为 个子专家(共 个),每个 token 激活 个子专家时,组合数从传统 Top-2 的 种激增至 种。 - 知识解耦:不同子专家专注于更细粒度的知识单元(如词性、句法结构),模型表达能力增强。
二、共享专家隔离(Shared Expert Isolation)
1. 动机
- 问题:传统路由中,不同专家可能重复学习通用知识(如语法规则),导致参数冗余。
- 解法:固定分配部分专家作为共享专家,强制所有 token 经过它们,专用于捕获通用知识;其余专家专注于领域特异性。
2. 实现
- 固定路由共享专家:
设定 个共享专家,每个 token 必须 经过这些专家,其余路由专家激活数减少至 。
公式: - 参数效率:共享专家集中学习通用知识,减少其他专家的冗余参数。
3. 优势
- 减少冗余:通用知识由共享专家统一处理,路由专家专注于差异化任务。
- 训练稳定性:共享专家作为知识“基座”,缓解稀疏路由带来的梯度不稳定问题。
三、负载均衡优化
1. 专家级均衡损失(Expert-Level Balance Loss)
- 目标:防止某些专家被过度使用(路由坍塌)。
公式:- :专家 被选中的频率(需接近均匀分布)。
- :专家 的平均门控值。
2. 设备级均衡损失(Device-Level Balance Loss)
- 目标:在分布式训练中,均衡不同设备上的计算负载。
公式:- 将专家分组到 个设备,确保每组计算量均衡。
- 优先保证设备间平衡,放宽专家级约束以避免性能损失。
四、性能与效果
- 计算效率:
总计算量与传统 MoE 相同(通过细粒度分割与激活数调整实现)。 - 参数量:
总参数量与传统 MoE 一致,但分配更高效(共享专家 + 细粒度路由专家)。 - 训练稳定性:
双层级负载均衡损失有效缓解路由坍塌和设备间负载不均问题。
五、代码示意(关键逻辑)
python展开代码class DeepSeekMoELayer(nn.Module):
def __init__(self, num_experts, m, K, Ks):
super().__init__()
# 细粒度分割:每个专家拆分为 m 个子专家
self.sub_experts = nn.ModuleList([
SmallFFN(hidden_dim // m) for _ in range(num_experts * m)
])
self.shared_experts = nn.ModuleList([ # 共享专家
SmallFFN(hidden_dim // m) for _ in range(Ks)
])
self.gate = nn.Linear(hidden_dim, num_experts * m) # 门控网络
self.K = K
self.Ks = Ks
def forward(self, x):
# 共享专家计算(强制所有 token 经过)
shared_out = sum([expert(x) for expert in self.shared_experts])
# 细粒度路由计算
logits = self.gate(x)
scores = torch.softmax(logits, dim=-1)
topk_scores, topk_indices = torch.topk(scores, self.K - self.Ks, dim=-1)
# 加权求和路由专家输出
routed_out = 0
for i in range(self.K - self.Ks):
expert_idx = topk_indices[:, :, i]
routed_out += self.sub_experts[expert_idx](x) * topk_scores[:, :, i]
return shared_out + routed_out + x # 总输出


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!