目录
一、DeepSeek LLM
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
https://arxiv.org/abs/2401.02954
2024 年 1 月发布。使用 GQA 优化推理成本;采用多步学习速率调度器替代余弦调度器;运用 HAI-LLM 训练框架优化训练基础设施;提出新的缩放分配策略。使用 2 万亿字符双语数据集预训练,67B 模型性能超越 LLaMA-2 70B,Chat 版本优于 GPT-3.5。
介绍
- 先摸清楚了模型变大时,训练时该用多大的数据批次(批量大小)和学习速度(学习率)最合适,发现这里头有规律可循;
- 顺着这个发现,我们找到了在增大模型和增加数据量时,怎么分配资源最有效的方法,还能提前预估超大模型的性能表现;
- 但有个重要发现:不同训练数据会导致规律不一样。就像做菜时,换种食材就要调整火候,用别人的数据集不能直接照搬我们的规律,得重新验证。
架构
- RMSNorm的 Pre-Norm 结构
- 使用SwiGLU 作为前馈网络 (FFN) 的激活函数
- RoPE
- 67B 模型使用了 GroupedQuery Attention (GQA) (Ainslie et al., 2023) 代替传统的多头注意力 (MHA)
价值点
数据批次(size)和学习率(learning rate)设置策略:
-
批次大小(Batch Size):
- 模型大小不同,计算预算不同:根据论文的研究,批次大小随着计算预算的增加而增加。
- 小模型(7B)的批次大小:论文中了解到,DeepSeek LLM 7B的设置是2304。
- 大型模型(67B)的批次大小:DeepSeek LLM 67B的设置为4608。
- 扩展批次大小公式:
- 经验公式:
Bopt = 0.2920 * 计算预算C的0.3271次幂
- 经验公式:
-
学习率(Learning Rate):
- 模型大小不同,计算预算不同:学习率随着计算预算的增加而减少。
- 小模型(7B)的学习率:DeepSeek LLM 7B的设置是4.2e-4。
- 大型模型(67B)的学习率:DeepSeek LLM 67B的设置是3.2e-4。
- 学习率设定公式:
- 经验公式:
𝜂opt = 0.3118 * 计算预算C的-0.1250次幂
- 经验公式:
-
学习率调度器(Learning Rate Scheduler):
- 多步学习率调度器(Multi-step Scheduler):为了在训练过程中能够继续训练,论文选择了多步学习率调度器。
- 多步学习率调度分布:训练初期2000步内达到最大值,然后80%的训练token之后减少到31.6%,接着到达90%的token时减少到10%。
- 优化策略:这种调度器能够允许在不同阶段的学习率优化,并且可以实现较好的性能。
二、DeepSeekMoE
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
https://arxiv.org/abs/2401.06066
发布于 2024 年 1 月。创新提出细粒度专家分割和共享专家隔离;采用专家级和设备级平衡损失缓解负载不均衡问题。通过监督微调构建了聊天模型,性能优于传统 MoE 和部分密集模型,16B 版本可在单 40GB 内存 GPU 上部署。
现在做大语言模型,用"混合专家"架构(MoE)可以节省算力。传统MoE方法比如GShard会从N个专家里选K个激活,但有个毛病——专家们学的东西容易重复,不够专精。就像让10个厨师做菜,每次随机选3个,结果每个厨师都只会做差不多的菜。
传统的 MoE 架构用 MoE 层替换了 Transformer 中的 Feed-Forward Networks(FFNs)。
DeepSeekMoE架构,主要做了两件事:
- 专家分小组 :把原本的N个专家拆成mN个小专家(比如2N个),每次激活mK个。相当于把10个厨师分成20个更专业的帮厨,每次选6个组合,能做更精细的菜品搭配。
- 设立共享专家 :专门留几个"全能型厨师"负责基础工作(比如切菜煮饭),避免其他专家重复做这些基础活。
结果:
- 2B小模型 ≈ 传统2.9B的效果(省1.5倍算力)
- 16B版本 ≈ LLaMA2 7B实力(耗电打4折)
- 145B巨无霸 ≈ 自家67B顶级模型(算力省70%+)
DeepSeekMoE 16B 遥遥领先:
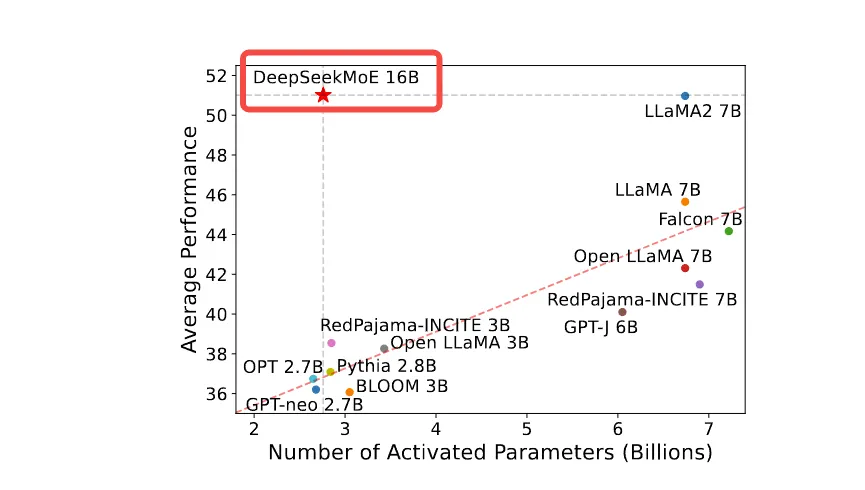
DeepSeekMoE介绍: https://www.dong-blog.fun/post/1953
三、DeepSeek Math
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
https://arxiv.org/abs/2402.03300
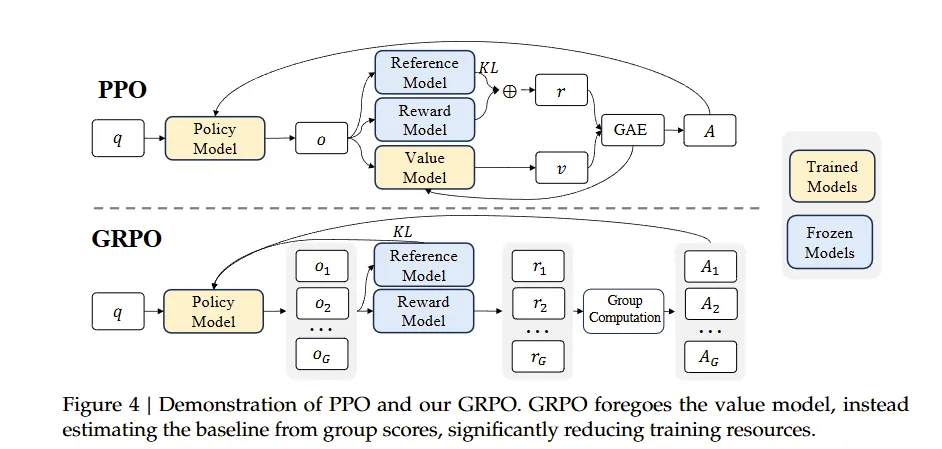
2024 年 2 月 5 日发布。通过数学预训练、监督微调、强化学习三阶段训练,构建 120B 数学语料库,提出 GRPO (Group Relative Policy Optimization)算法,在数学推理能力上直逼 GPT-4,超越众多 30B-70B 开源模型。
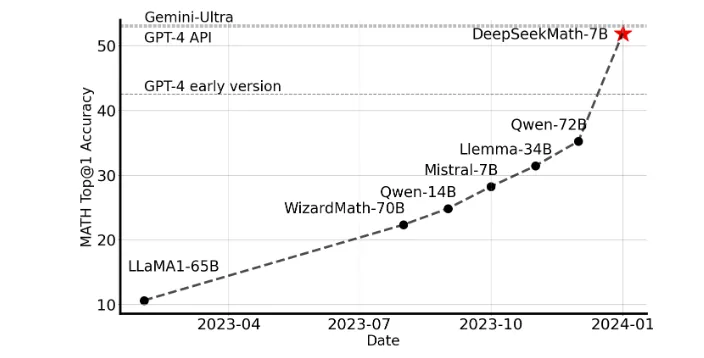
组相对策略优化(Group Relative Policy Optimization, GRPO)
四、DeepSeek V2
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
https://arxiv.org/abs/2405.04434
2024 年 5 月 7 日发布。创新提出多头潜在注意力( MLA);改进 MoE;基于 YaRN 扩展长上下文;发布了 Lite 版本;训练中设计三种辅助损失并引入 Token-Dropping 策略,通过多阶段训练流程提升性能。
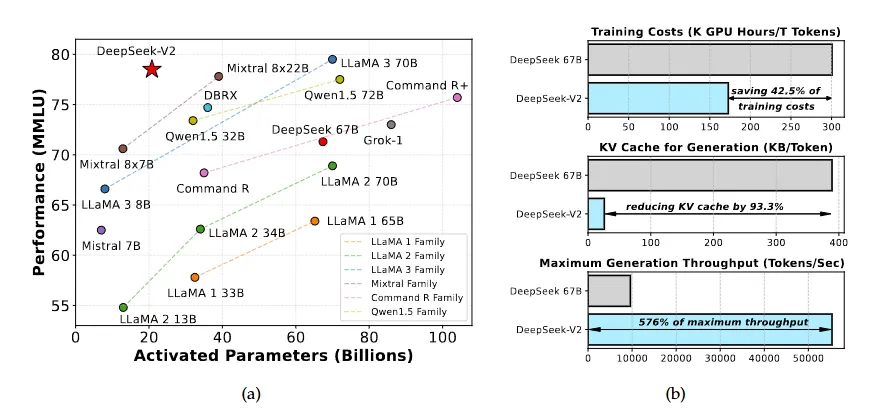
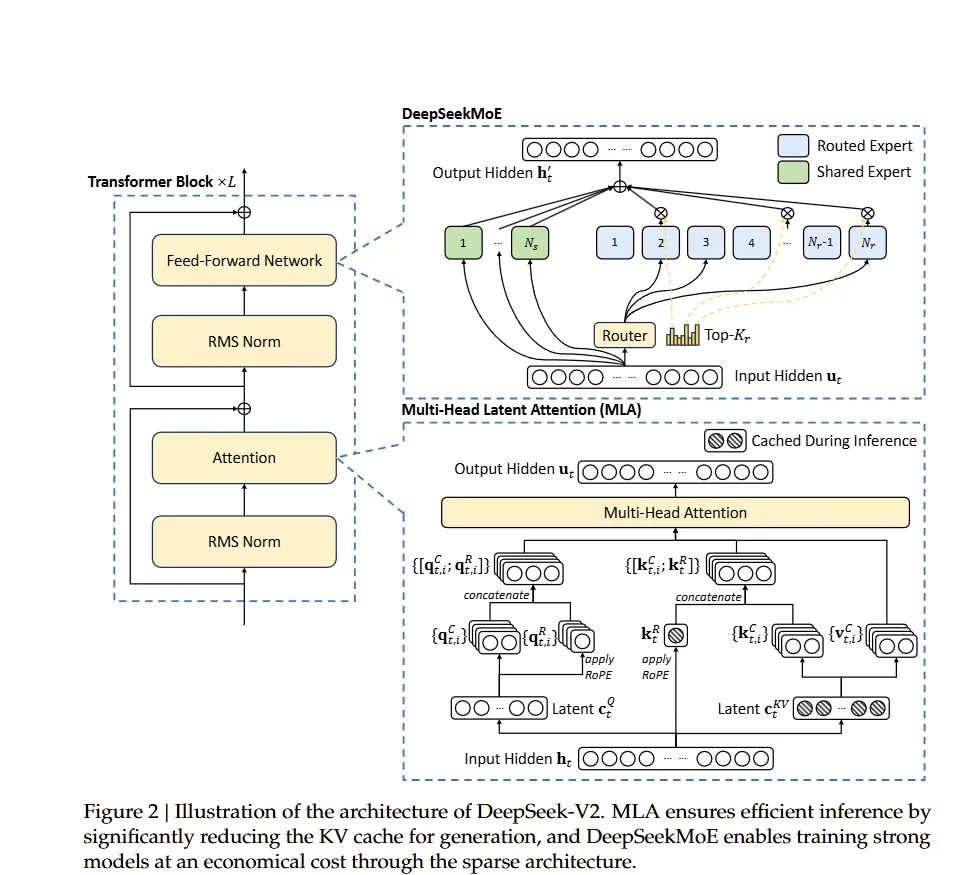
我们推出了 DeepSeek-V2,这是一个以经济训练和高效推理为特点的专家混合(MoE)语言模型。它总共包含 236B 个参数,其中每个 token 激活 21B 个参数,并支持 128K 个 token 的上下文长度。DeepSeek-V2 采用了包括多头潜在注意力(MLA)和 DeepSeekMoE 在内的创新架构。MLA 通过将键值(KV)缓存显著压缩成潜在向量来保证高效推理,而 DeepSeekMoE 则通过稀疏计算以经济成本训练强大的模型。与 DeepSeek 67B 相比,DeepSeek-V2 实现了显著更强的性能,同时节省了 42.5%的训练成本,减少了 93.3%的 KV 缓存,并将最大生成吞吐量提高了 5.76 倍。
五、DeepSeek V3
DeepSeek-V3 Technical Report
https://arxiv.org/abs/2412.19437
2024 年 12 月 26 日发布。创新提出无辅助损失的负载均衡策略、多 Token 预测,有 FP8 混合精度训练框架和高效通信框架。通过知识蒸馏提升推理性能,在低训练成本下性能强大,基础模型超越其他开源模型,聊天版本与领先闭源模型性能相当。
-
架构创新:
- 混合专家(MoE): 总参数量为671B,每个token激活37B。结合DeepSeekMoE(更细粒度的专家,共享/路由结构)和多头潜在注意力(MLA),通过减少KV缓存实现高效推理。
- 无辅助损失的负载平衡: 动态调整专家路由偏差,在不影响性能的情况下实现负载平衡。
- 多Token预测(MTP): 在训练过程中预测多个未来token,提升数据效率,并通过推测解码实现更快的推理。
-
训练效率:
- FP8混合精度训练: 首次大规模验证FP8,通过tile/block级量化减少内存并加速计算。
- DualPipe并行: 重叠计算/通信,最小化流水线气泡,并实现跨节点的专家并行化。
- 优化的基础设施: 定制通信内核、节省内存的技术(重新计算、CPU EMA)和集群级优化。总训练成本为2.788M H800 GPU小时(约550万美元)。
-
性能及基准测试:
- 预训练: 14.8T高质量tokens,通过YaRN扩展至128K上下文。训练稳定,无损失波动。
- 后训练: 通过SFT(1.5M实例)和以DeepSeek-R1为基础进行推理的RL(群体相对策略优化)蒸馏。
- 先进的结果: 超越开源模型(Qwen2.5-72B, LLaMA-3.1-405B),媲美GPT-4o/Claude-3.5-Sonnet在以下方面的表现:
- 数学/代码: MATH-500(90.2% EM),LiveCodeBench(40.5% Pass@1),Codeforces(51.6%ile)。
- 知识: MMLU-Pro(75.9%),GPQA(59.1%)。
- 中文任务: C-SimpleQA(64.8%),C-Eval(86.5%)。
六、DeepSeek R1
https://arxiv.org/abs/2501.12948
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
2025 年 1 月发布。DeepSeek-R1-Zero 无需 SFT 就有卓越推理能力,与 OpenAI-o1-0912 在 AIME 上性能相当;DeepSeek-R1 采用多阶段训练和冷启动数据,推理性能与 OpenAI-o1-1217 相当;还提炼出6 个蒸馏模型,显著提升小模型推理能力。
这篇解读很好:https://zhuanlan.zhihu.com/p/20844750193
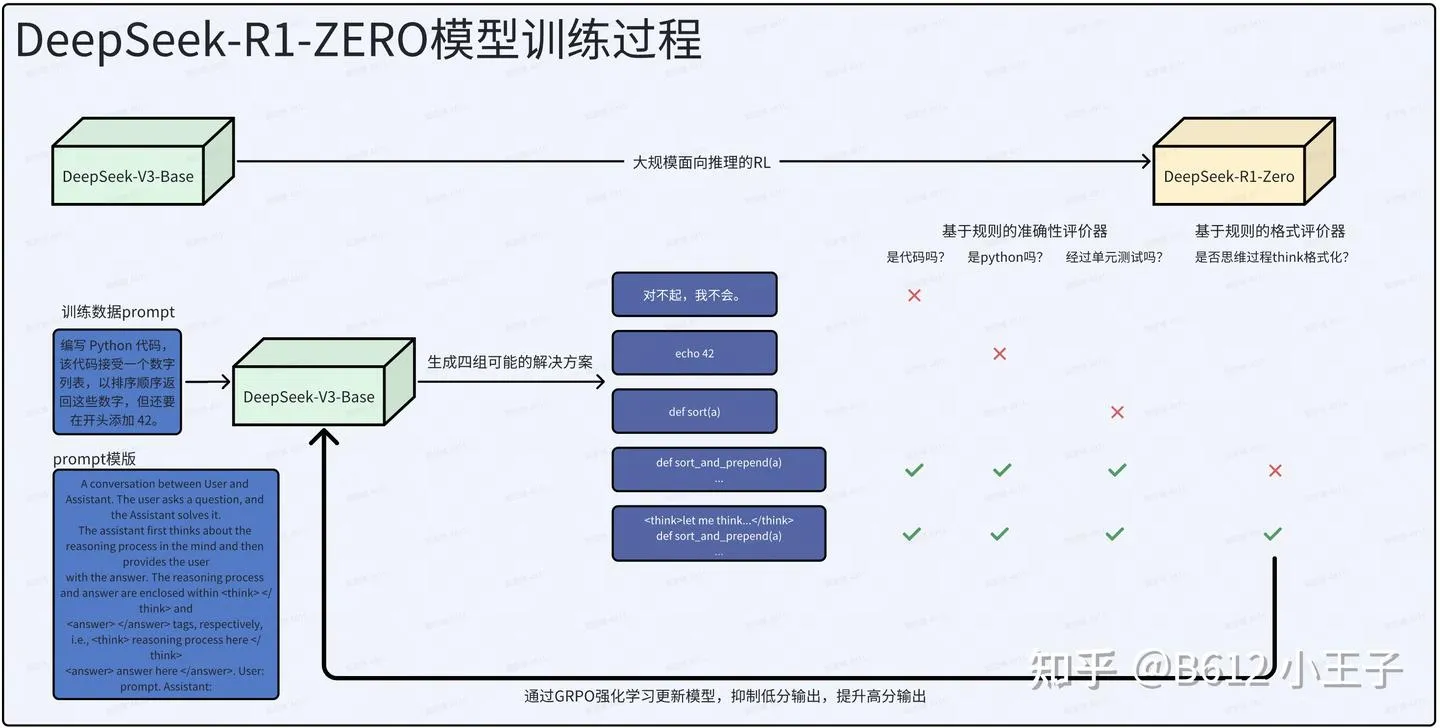
如何得到DeepSeek-R1-Zero:
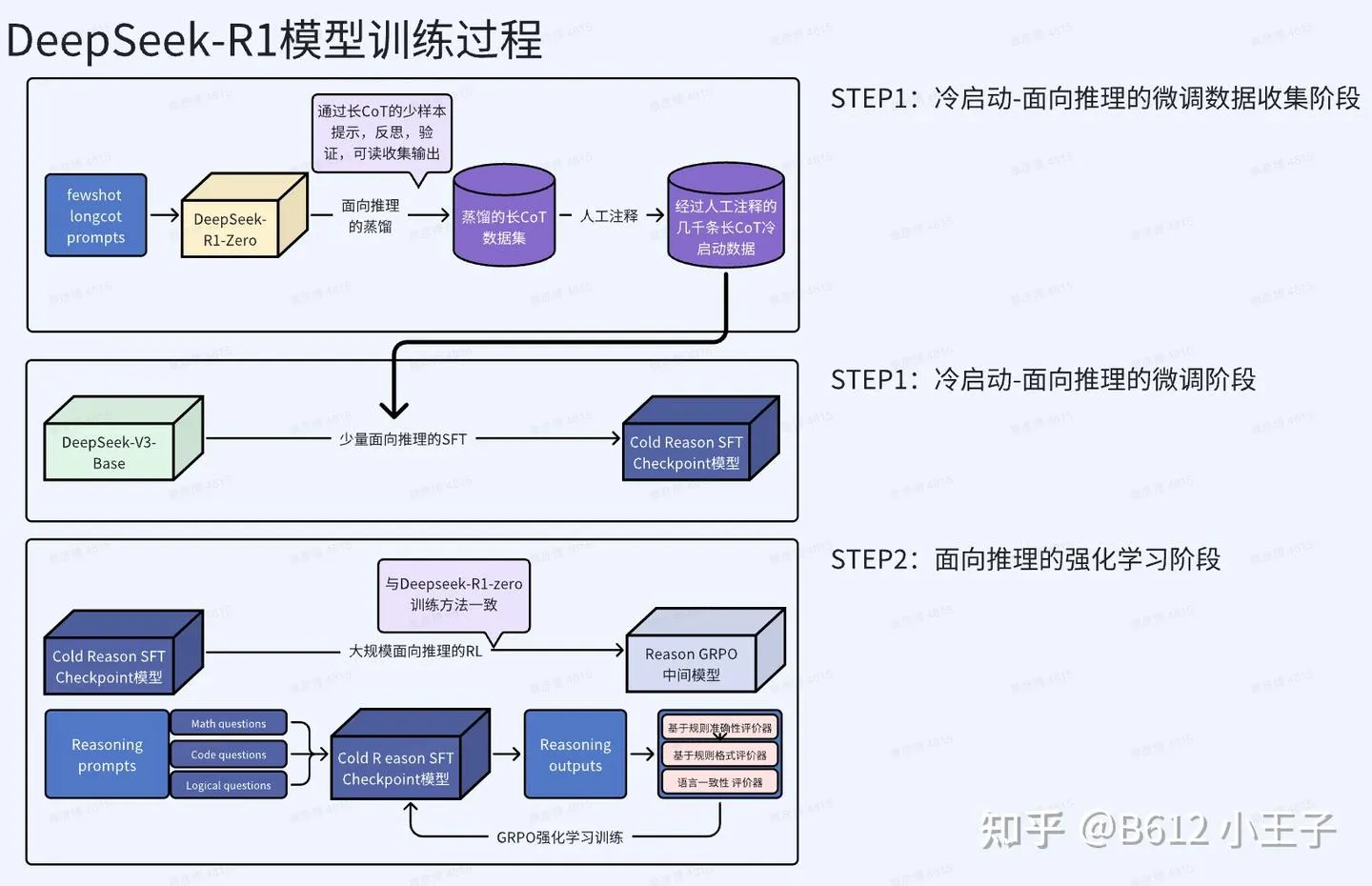
如何训练得到DeepSeek-R1:
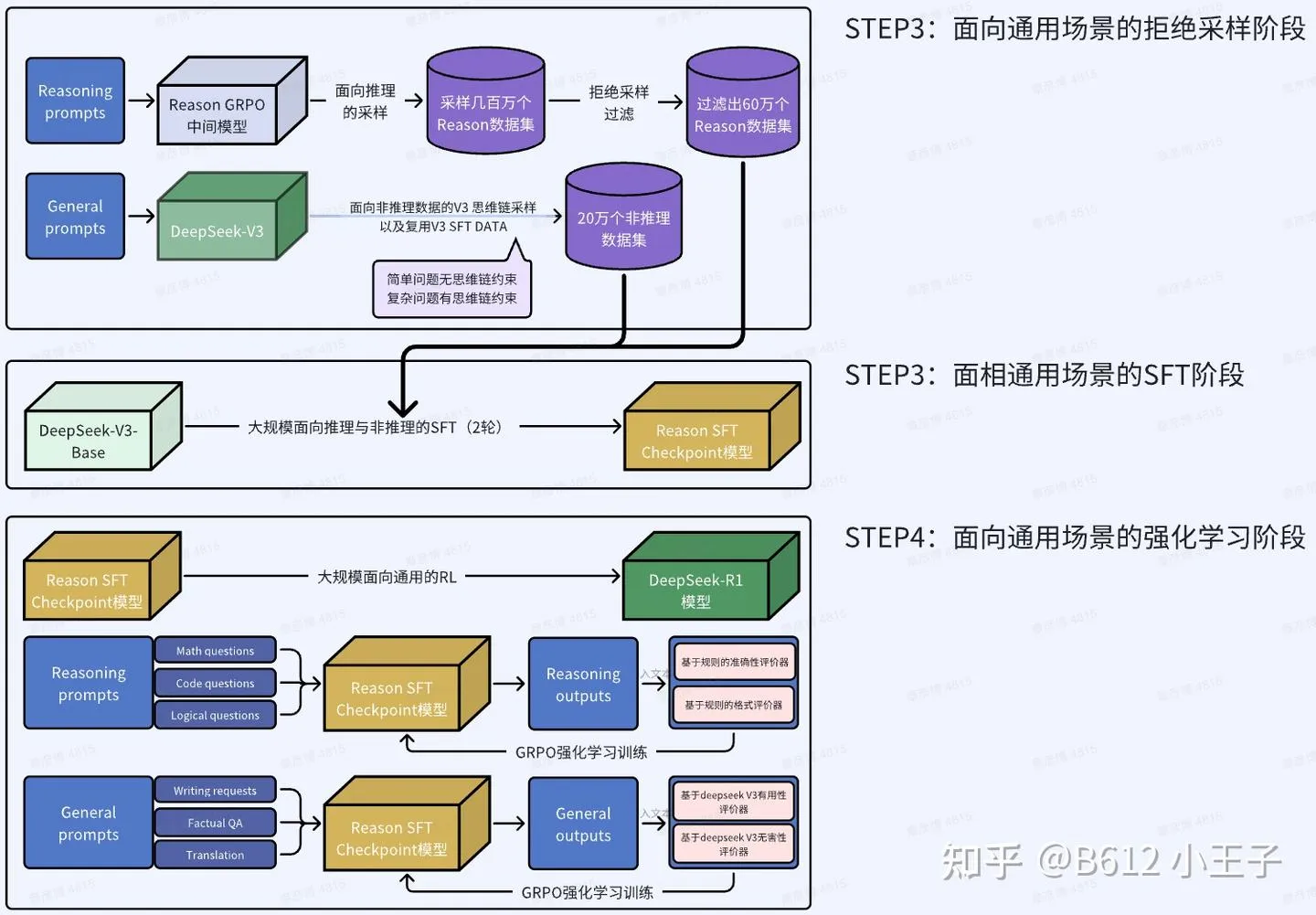
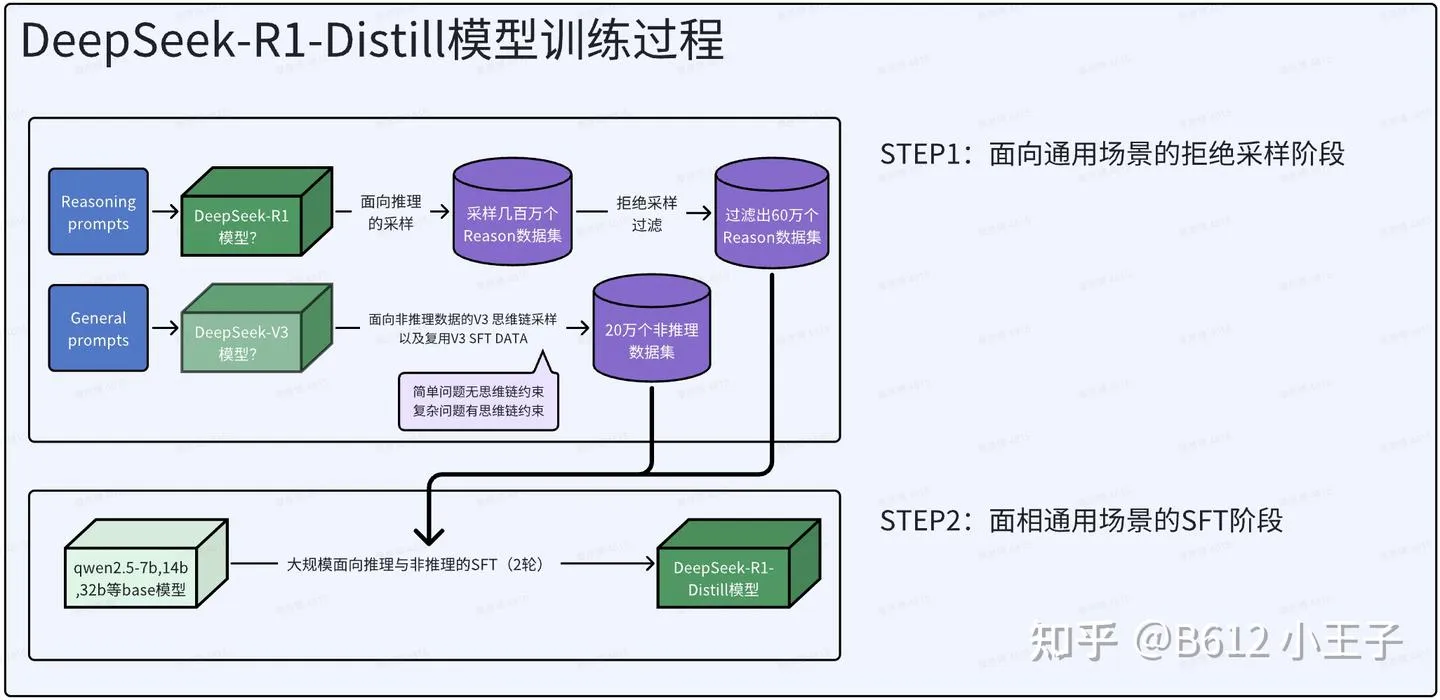
如何知识蒸馏把R1模型能力给其他小模型:


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!