FlashAttention 透彻理解
目录
本文作为这篇文章的总结:
https://mp.weixin.qq.com/s/-rXYgsu_1IEpjGvSQArPJQ
深入解析FlashAttention的核心原理与优化策略
FlashAttention的核心价值
- 问题背景:Transformer的Attention模块存在计算效率瓶颈,传统优化方法(如稀疏近似)虽减少计算量(FLOPs),但未解决关键I/O瓶颈。
- 三大优势:
- I/O感知的高效计算:通过优化内存访问模式(减少HBM访问次数)而非仅减少FLOPs提速。
- 内存高效:分块计算(Tiling)避免存储中间矩阵(如QK^T),显著降低内存占用。
- 精确计算:结果与原始Attention完全一致,避免近似算法的误差。
数学原理:从Softmax到FlashAttention
-
安全Softmax:通过减去最大值防止数值溢出,但需三次遍历数据。
Softmax的原始公式:
安全Softmax:
-
Online Softmax(Nvidia提出):
- 递归思想:逐元素计算局部最大值和归一化因子,将三次遍历降为两次。
-
FlashAttention的突破:
- 融合计算:将Softmax与Value矩阵乘法结合,通过分块迭代公式实现单次遍历。
- 避免中间存储:直接计算Attention结果,无需保存QK^T和Softmax矩阵。
硬件视角:为什么需要FlashAttention?
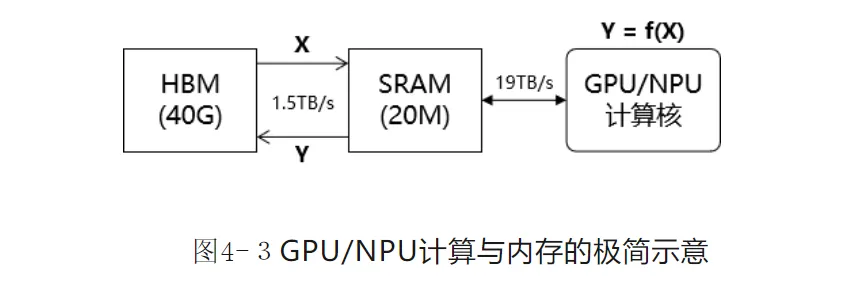
- GPU/NPU内存瓶颈:
- HBM:容量大(40GB)但带宽低(1.5TB/s)。
- SRAM:带宽高(19TB/s)但容量小(20MB)。
- 计算膨胀系数β:矩阵乘法(β=O(d))易受计算带宽限制,Softmax(β≈3)受内存带宽限制。
- 分块策略:将大矩阵拆分为小块,在SRAM中完成计算,减少HBM交互次数。
算法演进:FA-1到FA-3的核心优化
- FA-1(基础版本):
- 外循环分块:按Q的行分块,内循环加载K/V块,逐块计算Softmax并累加结果。
- 避免中间矩阵:融合Softmax与矩阵乘,仅保存最终Attention结果。
- FA-2:
- 循环结构调整:将Q作为外循环,K/V为内循环,减少数据重复加载。
- 计算式优化:调整Softmax迭代公式,减少除法操作(式4-12),最后统一归一化。
- FA-3(硬件级优化):
- 异步计算:利用H100的Tensor Core异步执行GEMM与Softmax。
- 低精度加速:支持FP8计算,提升吞吐量。
面试常见问题
-
FlashAttention为何比传统Attention快?
- 关键在减少HBM访问次数,通过分块计算和融合Softmax与矩阵乘,避免存储中间矩阵。
-
如何保证计算精确性?
- 采用安全Softmax的数学变形,通过局部归一化因子递归计算,结果与原始算法一致。
-
FA-2相比FA-1改进点?
- 外循环调整为Q分块,减少数据加载;优化Softmax迭代公式,减少非矩阵运算。
-
分块大小如何选择?
- 受SRAM容量限制,需确保每个块的计算在SRAM内完成,典型配置为块大小≤128x128。
总结
FlashAttention通过分块计算与迭代式Softmax的巧妙结合,在保证计算精度的同时,大幅降低内存访问开销,成为大模型训练的关键优化。其设计思想揭示了AI计算中“内存效率优先于计算量”的核心原则,为后续硬件感知算法提供了范本。
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录