目录
论文总结
这篇论文《With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations》提出了一种新的对比学习方法,即最近邻对比学习(NNCLR)。传统的自监督学习主要依赖于数据增强生成的同一实例的不同视角,而NNCLR通过在潜在空间中找到最近邻样本,并将其视为正样本。这种方法增加了语义上的多样性,比预定义的图像变换更丰富。
主要贡献和发现:
- 方法概述:NNCLR方法从支持集中获取最近邻样本,并将这些样本作为正样本,用于对比损失计算。这种方法比仅使用单一实例的数据增强对比更具语义广度。
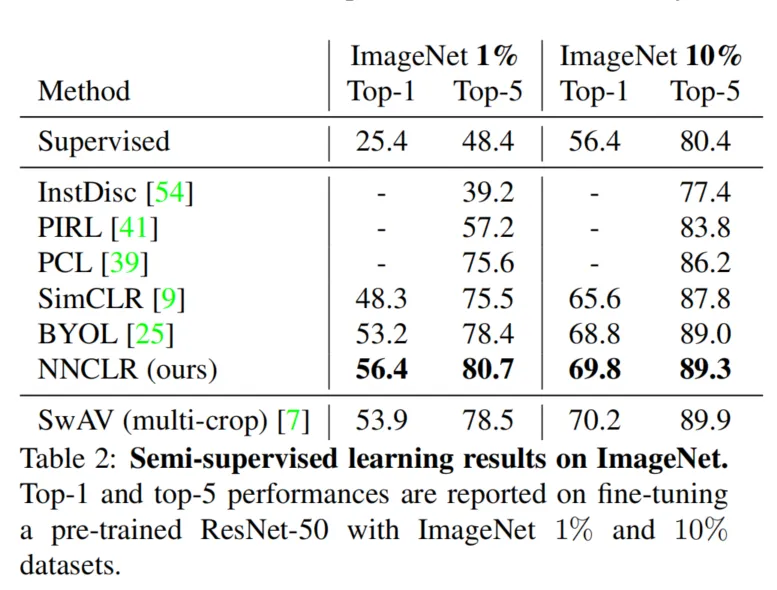
- 提升分类性能:在ImageNet数据集上,使用ResNet-50模型通过线性评估协议进行分类,NNCLR实现了75.6%的准确率,比之前的最先进方法提升了近4%。在仅有1%标签数据的半监督学习中,NNCLR也比其他方法表现更好。
- 减少对数据增强的依赖:与现有方法相比,NNCLR对复杂的数据增强需求较低。例如,仅使用随机裁剪的情况下,其性能仅下降了约2.1%。
- 迁移学习表现:在12个下游任务中,NNCLR在8个任务上优于当前最好的方法,包括在有监督学习模型上实现的特征表现。
研究背景:传统的实例判别方法只处理单一实例的多个视图,而无法处理同类实例的语义相似性。而NNCLR通过在支持集中寻找同类实例作为正样本,拓展了模型在对比学习中的语义多样性。这种方法相较于聚类方法避免了早期泛化问题。
实验与结果:
- 在ImageNet分类任务中,NNCLR的表现超越了包括SimCLR、BYOL和SwAV等方法。
- 在半监督学习中,尤其是使用较少标签时,NNCLR显著提升了性能。
- 在多个数据集的迁移学习任务中,NNCLR的特征学习性能同样优于现有方法。
结论:NNCLR提供了一种新的正样本选择策略,通过引入最近邻概念提高了自监督对比学习的性能,减少了对复杂数据增强策略的依赖。该方法在大规模图像分类、半监督学习以及迁移学习任务中都表现优异,展示了其在视觉表示学习中的广泛适用性。
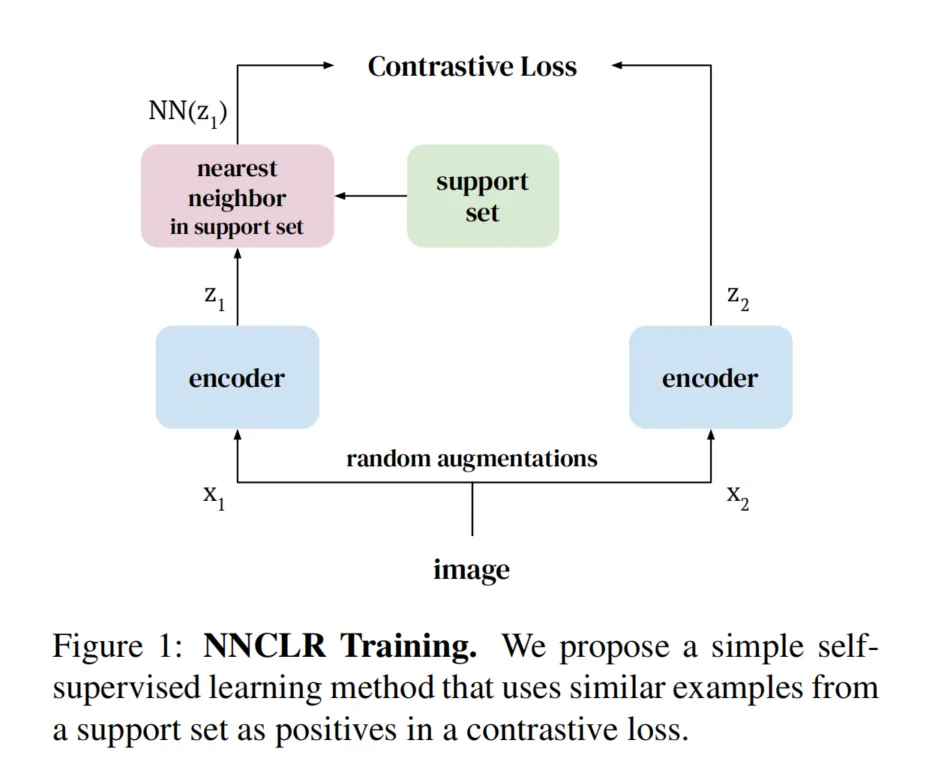
NNCLR和SimCLR的区别
NNCLR和SimCLR都是基于对比学习的自监督学习方法,但它们在正样本选择和数据增强依赖上存在显著区别:
-
正样本选择:
- SimCLR:使用数据增强生成的同一图像的不同视图(例如随机裁剪、颜色扰动等)作为正样本。这些正样本实际上是同一个实例的变体,目标是让模型在潜在空间中保持这些变体的一致性。
- NNCLR:引入了“最近邻”的概念,利用潜在空间中的语义相似性,将来自支持集的最近邻样本作为正样本。也就是说,NNCLR选择的正样本不仅仅是同一图像的变体,还可能是不同图像但具有相似语义的样本。通过这种方式,NNCLR扩展了正样本的范围,提高了学习到的特征的泛化性。
-
数据增强的依赖:
- SimCLR:高度依赖于复杂的数据增强策略,以生成足够的图像变体,从而帮助模型学习有区分度的特征。例如SimCLR会应用随机裁剪、颜色抖动、高斯模糊等多种增强方法。
- NNCLR:减少了对复杂数据增强的依赖,因为通过最近邻搜索得到的正样本已经具有自然的语义多样性。实验表明,在仅使用简单随机裁剪的情况下,NNCLR的性能损失较小,这表明NNCLR在正样本构建上比SimCLR更为灵活。
-
性能表现:
- 在ImageNet分类任务中,NNCLR通过最近邻正样本构建策略显著提高了性能。在相同设置下,NNCLR比SimCLR提升了大约3.8%的Top-1准确率,这说明NNCLR的最近邻正样本策略比SimCLR的单实例变体策略效果更好。
总结来说,SimCLR强调通过数据增强构造同一实例的不同视图,而NNCLR则利用潜在空间中的最近邻作为正样本,进一步扩展了正样本的语义多样性并减少了对数据增强的依赖,从而提升了模型的性能。
InfoNCE Loss(信息对比损失)介绍
在论文中,InfoNCE Loss(信息对比损失)是一种常用的对比损失函数,用于在自监督学习中帮助模型学习有区分度的特征。其核心思想是拉近正样本对之间的距离,同时将负样本对推得更远,以提高模型对不同样本的区分能力。
InfoNCE损失的定义如下:
其中:
- 是样本 的嵌入向量。
- 是样本 的正样本的嵌入向量(在SimCLR中是同一图像的不同视图,在NNCLR中是最近邻样本)。
- 表示负样本集合(即非正样本)。
- 是一个温度参数,用于控制对比损失的平滑度。
在具体应用中,InfoNCE Loss 通过使正样本对(即同一实例的不同视图或最近邻样本)的嵌入向量更接近,同时使得负样本对之间的嵌入距离更远,从而让模型能够有效地区分样本并学习到有意义的特征表示。
为什么使用InfoNCE Loss? InfoNCE Loss 可以通过最大化正样本对之间的互信息来提高模型的判别能力,使模型能够在自监督学习中获得对未标注数据的良好表示。同时,它还能够有效防止“塌陷问题”,即避免模型将所有样本映射到相同的表示。
InfoNCE Loss和三元损失有什么联系吗
InfoNCE Loss和**三元损失(Triplet Loss)**在目标和实现方式上确实有相似之处,但也存在一些关键的区别。
相似之处:
两者都用于度量学习任务中,其目的是拉近正样本对之间的距离,同时将负样本对推得更远,以学习更具区分性的特征表示。
- 共同目标:InfoNCE Loss和三元损失都希望模型能够将相似样本(正样本)靠近,而将不同样本(负样本)区分开来。这两个损失都试图优化特征空间,使得同一类别的样本距离更近,不同类别的样本距离更远。
- 使用的样本对:在训练时,两者都使用正样本和负样本对来指导模型学习。三元损失显式地使用一个锚点样本、一个正样本和一个负样本,InfoNCE Loss也需要正样本对和负样本对。
区别:
尽管它们的目的一致,但InfoNCE Loss和三元损失在具体实现和使用样本方面有所不同:
-
样本选择:
-
三元损失:对于每个样本(锚点样本),选择一个正样本和一个负样本构成三元组(三元组形式为锚点样本,正样本,负样本)。损失函数根据设定的边界(通常称为“边距”)调整正负样本之间的距离。其损失定义为:
其中,表示距离函数(如欧氏距离),为边距超参数。
-
InfoNCE Loss:同时处理多个负样本而不是单个负样本。对于每个正样本对,它将所有非正样本视为负样本。InfoNCE Loss使用softmax将正负样本对进行对比计算:
因此,InfoNCE Loss能够有效利用小批量内的所有样本,而不仅限于特定的三元组。
-
-
对负样本的处理:
- 三元损失:依赖于明确选择的单个负样本,并使用边距来保证负样本距离至少比正样本远一个固定的距离。
- InfoNCE Loss:通过softmax机制将所有负样本纳入计算,从而有效地利用小批量中的所有样本来获得一个更全面的负样本空间。此外,InfoNCE Loss采用温度参数来调节对负样本的权重,使得损失更加平滑和灵活。
-
计算效率:
- 三元损失:需要为每个样本明确选择一个负样本,这使得负样本选择过程较为复杂,通常还需要设计策略来选择“困难负样本”(hard negative)。
- InfoNCE Loss:通过在小批量内直接处理所有非正样本为负样本,简化了负样本的选择过程。尤其在大规模数据集或高维空间中,InfoNCE Loss相比三元损失在计算效率上更具优势。
总结
尽管两者的目的一致,InfoNCE Loss在处理大批量样本时比三元损失更高效,并且能够利用更多负样本。而三元损失则较适合在需要控制单一负样本距离的场景中使用。对于对比学习任务,尤其是自监督学习中,InfoNCE Loss因其在大批量数据处理中的优势被广泛采用。
和自监督学习对比
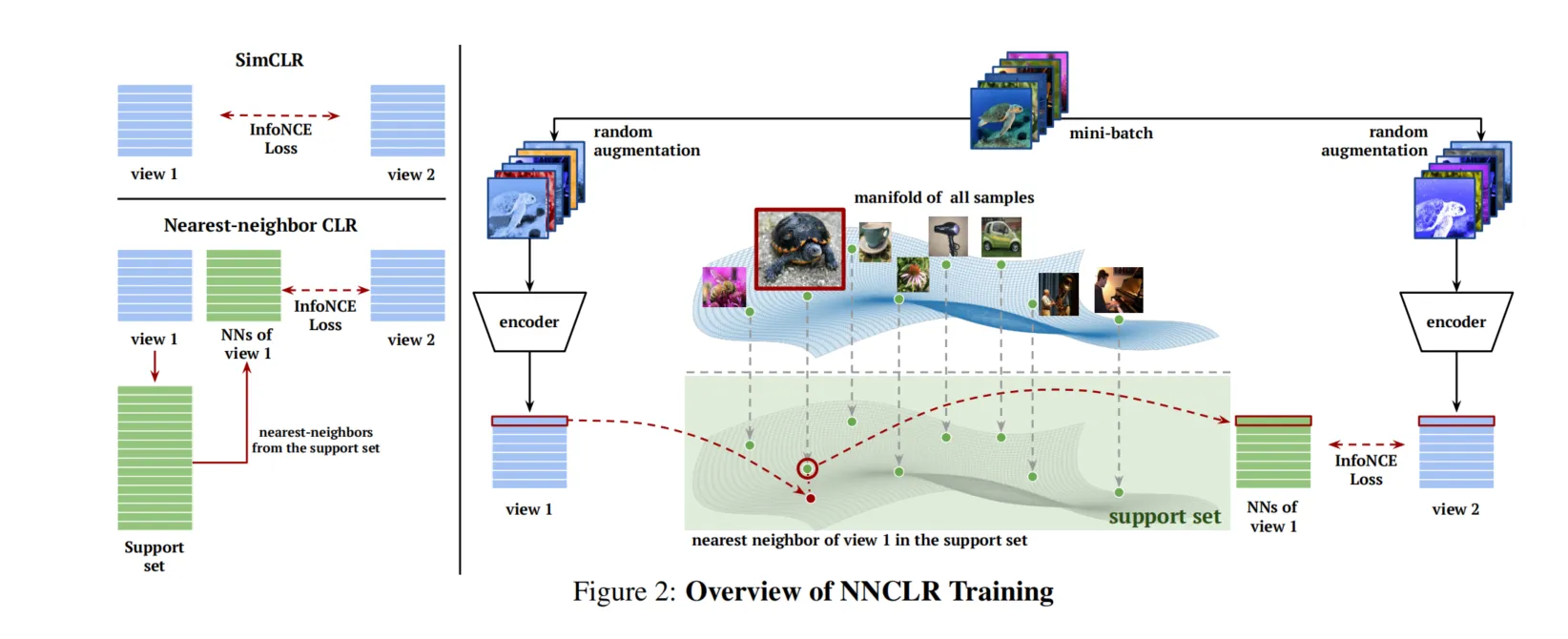
NNCLR的聚类是如何完成的
在NNCLR(最近邻对比学习)方法中,正样本的选择是通过支持集中最近邻搜索来实现的,而不是传统的聚类方法。具体来说,NNCLR并未进行显式的聚类,而是通过潜在空间中的最近邻搜索来找到与当前样本语义相似的样本作为正样本。这种方式不同于基于聚类的方法,如SwAV或DeepCluster,这些方法通常需要将数据集分成多个语义类群,然后使用这些类群中的样本作为正样本。
最近邻选择过程:
-
支持集维护:在训练过程中,NNCLR维护了一个支持集(support set),该支持集存储了训练数据的嵌入表示,并定期更新。支持集通常以队列形式实现,新的嵌入加入支持集,旧的嵌入被替换。
-
最近邻搜索:在每次训练迭代中,NNCLR会从支持集中找到当前样本在潜在空间中的最近邻作为正样本。这些最近邻样本被认为在语义上与当前样本相似,因此可以用来替代单一实例的变体作为正样本对。
-
非聚类依赖:相比于需要先将样本划分为不同类群的方法,NNCLR直接在高维嵌入空间中搜索相似样本作为正样本。这避免了聚类过程带来的额外开销,同时也减少了由于聚类过程中的早期泛化问题而导致的性能下降。
这种方法使得NNCLR能有效地在没有聚类标签的情况下捕捉到语义相似性,并利用最近邻信息来增加正样本的多样性,从而增强自监督学习的效果。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!