目录
推荐两篇综述
推荐两篇综述:
https://arxiv.org/abs/2006.08218
https://arxiv.org/abs/2304.12210
本文内容全来源自这两篇综述。目标是让大家了解一些自监督学习现在的发展,自监督学习已经不是当初认识的自监督学习了(只能做聚类之类的无监督学习),自监督学习已经发展得很强大。自监督学习(Self-supervised Learning),被称为“智能的暗物质”。
机器学习的学习范式
机器学习中的监督学习、半监督学习、无监督学习和自监督学习是常见的四种学习范式,它们在数据和标签的使用方式上各有特点。以下是简要介绍:
-
监督学习:使用带标签的数据训练模型,适合分类和回归任务。优点是效果好,缺点是需要大量标注数据,应用于图像分类、语音识别等。
-
半监督学习:结合少量标注数据和大量未标注数据,能提升泛化能力,减少对标注数据的需求。适用于标注数据获取难的场景,如医学图像分析。
-
无监督学习:无需标注数据,利用数据模式进行聚类、降维等。优点是可以发现数据中的隐藏结构,但结果的解释性较差,常用于客户分群、异常检测等。
-
自监督学习:是无监督学习的子类。从未标注数据中生成“伪标签”进行训练,广泛应用于NLP和计算机视觉。优点是不需人工标注,但任务设计复杂,应用于特征提取和预训练语言模型等。
自监督学习的范式
可以将主流的自监督方法概括为三大类,并对其具体类型进行详细划分:
-
1. 生成式方法(Generative):训练一个编码器将输入编码为显式向量,并通过解码器从重建(例如,填空测试、图生成)。
举例,BERT模型就是生成式方法。BERT通过“预训练+微调”的方式进行训练,以应对多种自然语言处理任务。BERT的预训练采用了“无监督学习”方式,通过两个特定的任务使模型学习语言的特征:掩码语言模型(Masked Language Model,MLM)、下一句预测(Next Sentence Prediction,NSP)。
在MLM任务中,BERT会随机地将输入文本的15%的单词进行“掩码”,即用特殊的[MASK]符号替代。模型的任务是根据上下文信息预测这些被掩码的词。这种双向编码器的方式使得BERT能够同时关注一个单词的前后文信息,从而理解更为复杂的语言关系。
举个例子,对于句子“ChatGPT is a great AI assistant”,假设“great”被掩码成[MASK],模型将会根据上下文来预测出“great”这个词。
-
2. 对比式方法(Contrastive):训练一个编码器将输入编码为显式向量以测量相似性(例如,最大化互信息、实例区分)。
举例,后面要将的深度度量学习家族:SimCLR/NNCLR/MeanSHIFT/SCL的算法都是对比式方法。这些方法通过构造正样本对和负样本对来训练模型,使得相似的样本在嵌入空间中靠近,而不相似的样本则被推得更远。
以SimCLR为例,其训练过程包括以下几个步骤:(1)数据增强:对每个输入样本应用两种不同的数据增强策略,生成一对正样本。(2)编码器:将增强后的样本输入编码器(通常是卷积神经网络),得到对应的嵌入向量。(3)投影头:通过一个非线性投影头将嵌入向量映射到对比空间。(4)对比损失:使用NT-Xent损失函数最大化正样本对之间的相似性,同时最小化负样本对之间的相似性。
相似的样本在嵌入空间中靠近,而不相似的样本则被推得更远。这个算法可以用于图片检索引擎,比如百度搜图。
-
3. 生成-对比式方法(Generative-Contrastive,或对抗性方法):训练一个编码器-解码器生成假样本,并通过判别器将其与真实样本区分开来(例如,GAN)。
举例,生成对抗网络(Generative Adversarial Networks,简称GAN)是生成-对比式方法的典型代表。GAN由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器的任务是从随机噪声中生成尽可能逼真的假样本,而判别器则负责区分输入的样本是真实的还是由生成器生成的假样本。两者在训练过程中进行对抗性博弈,生成器不断提升其生成样本的质量,以欺骗判别器,而判别器则不断提高其区分能力。
GAN的训练过程可以概括为以下几个步骤:(1)生成器生成假样本:生成器接收一个随机噪声向量作为输入,通过一系列的神经网络层生成假样本,例如图像。(2)判别器评估样本:判别器接收真实样本和生成器生成的假样本,输出一个概率值,表示输入样本是真实的可能性。(3)更新网络参数:根据判别器的输出结果,分别更新生成器和判别器的参数。生成器的目标是最大化判别器对假样本的错误判断概率,而判别器的目标是最大化正确区分真实样本和假样本的概率。(4)通过这种对抗性的训练过程,生成器能够逐步生成与真实样本难以区分的高质量假样本。GAN在图像生成、图像超分辨率、图像修复、风格迁移等领域取得了显著的成果。
除了原始的GAN模型外,衍生出了许多变种以解决不同的任务和挑战,例如:(1)条件生成对抗网络(Conditional GAN,cGAN):在生成过程中引入条件信息,如类别标签,使生成的样本能够根据指定的条件进行控制。(2)周期一致性生成对抗网络(CycleGAN):用于无监督的图像到图像翻译,通过引入循环一致性损失,确保转换前后的图像在循环转换中保持一致。(3)生成对抗网络的变分自编码器(VAE-GAN):结合了变分自编码器的生成能力和GAN的对抗训练机制,以提升生成样本的多样性和质量。
自监督学习的下游目标不同,选择的范式就不同。
生成式方法(Generative)下面有AR、基于流的模型、自编码器、Hybrid Model(混合模型)。
对比式方法(Contrastive)下面还有Context-Instance、Instance-Instance。Context-Instance 是指一个具体实例在某个上下文中的表现或作用。上下文(context)通常是指特定的条件、环境、时间或其他外部因素,实例(instance)则是指具体的数据点、样本或对象。Instance-Instance 则描述的是两个具体实例之间的关系或交互。这通常涉及比较、对比或计算实例之间的相似性、距离或其他度量标准。
生成-对比式方法(Generative-Contrastive,或对抗性方法)下面还可以细分为Generate Complete Input 和 Recover Partial Input。 Generate Complete Input 是指模型生成一个完整的、全新的输入数据。这个输入数据可能是从噪声中生成的,也可能是基于某些特定条件生成的。例如,在经典的GAN架构中,生成器(Generator)从随机噪声(通常是服从高斯分布的向量)中生成一个完整的图像或其他形式的输出。Recover Partial Input 是指模型根据部分已知的输入信息,推测或恢复出缺失的部分,从而重构一个完整的输入数据。这个过程可以理解为“填补空白”或“修复缺失数据”。这种技术在图像修复(image inpainting)、信号修复等任务中常见。
总结为下图:
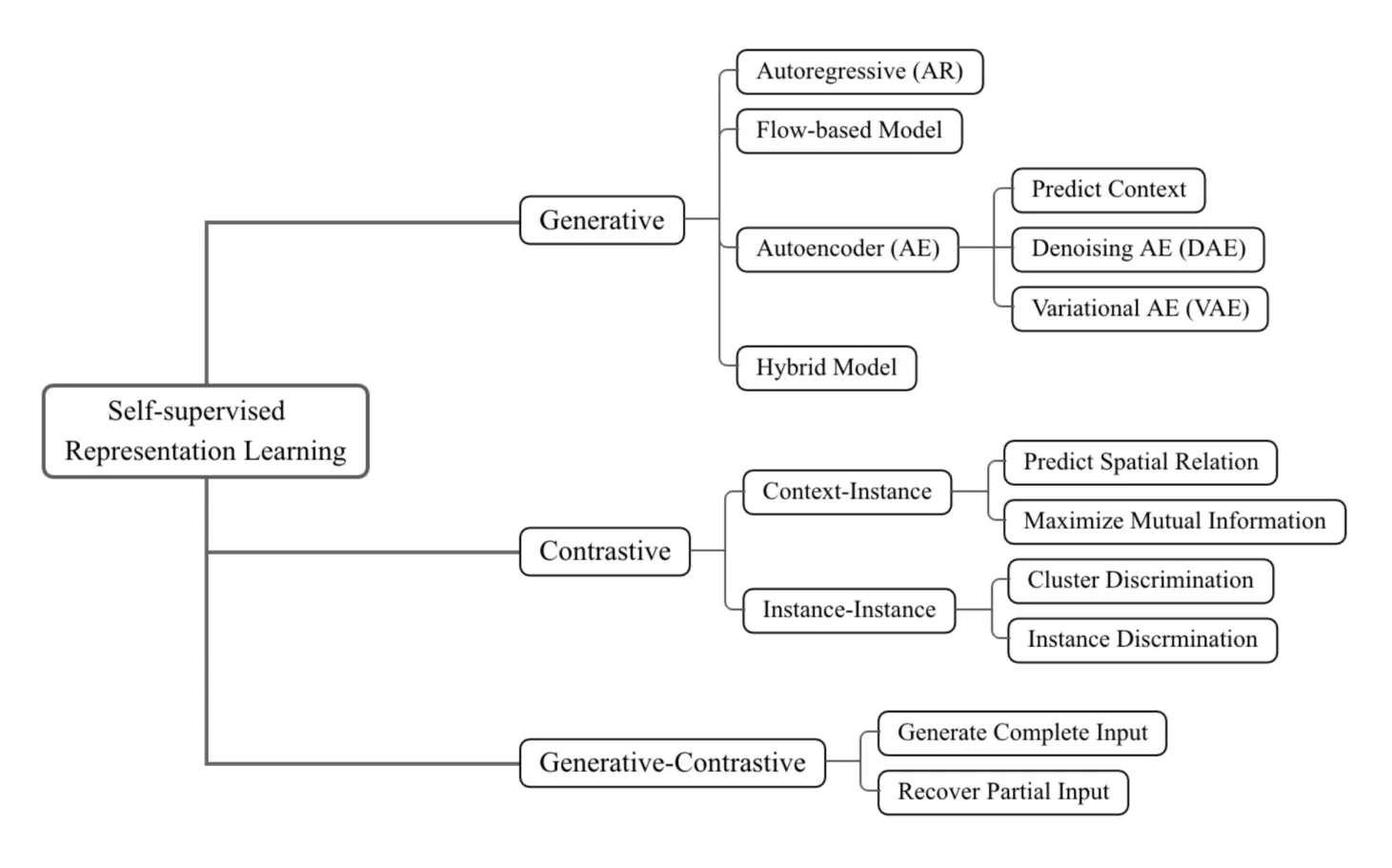
三大类的主要区别在于模型架构和目标。下图展示了它们的详细概念比较。它们的架构可以统一为两个主要组成部分:生成器和判别器,生成器可以进一步分解为编码器和解码器。不同之处如下:
- 关于潜在分布:在生成式和对比式方法中,是显式的,通常被下游任务利用;而在GAN中,是隐式建模的。
- 关于判别器:生成式方法没有判别器,而GAN和对比式方法则有。对比式判别器的参数相对较少(例如,2-3层的多层感知机)而GAN的判别器参数较多(例如,标准的ResNet [53])。
- 关于目标函数:生成式方法使用重构损失,对比式方法使用对比相似性度量(例如,InfoNCE),生成-对比式方法则利用分布性差异作为损失(例如,JS散度,Wasserstein距离)。
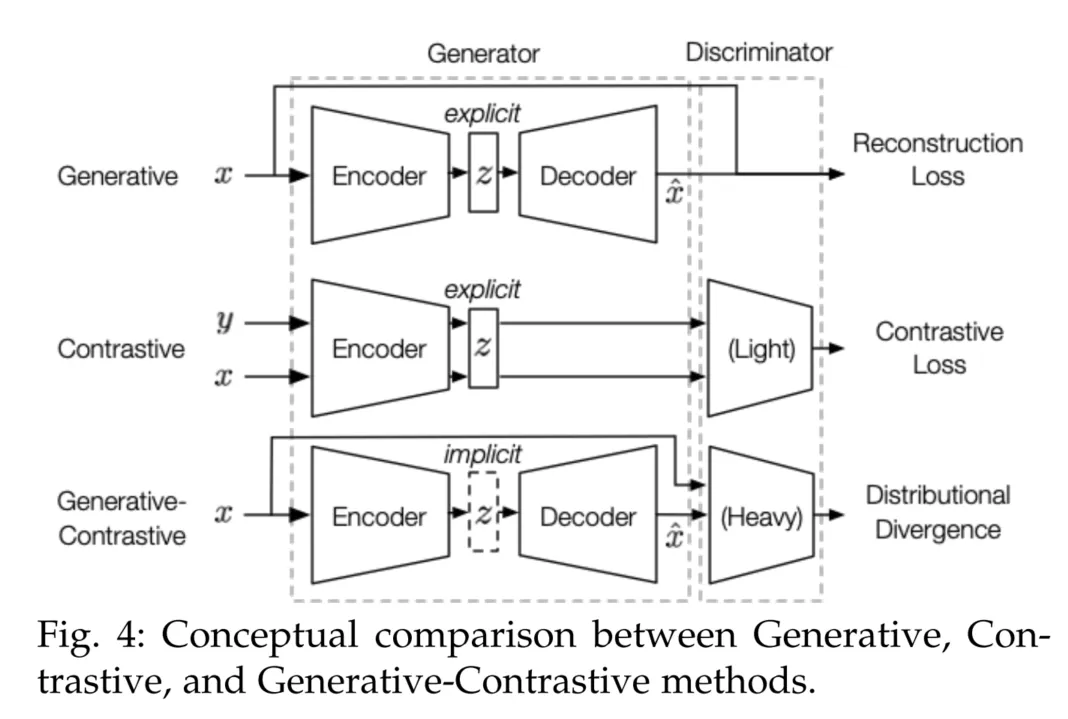
自监督表示学习的概览如下。缩写解释:“FOS”表示研究领域;“NS”表示负样本;“PS”表示正样本;“MI”表示互信息。类型中的字母含义为:G 生成式;C 对比式;G-C 生成-对比(对抗式)。在“Hard NS”和“Hard PS”中的符号说明:“-”表示不适用,“×”表示未采用,“X”表示已采用;“no NS”特别表示在实例-实例对比中不使用负样本。
基于生成模型的重要自监督学习方法
自回归(AR)模型
自回归(Auto-regressive,AR)模型可以视为“贝叶斯网络结构”(有向图模型)。联合分布可以被分解为条件概率的乘积:
其中,每个变量的概率依赖于前面的变量。
在自然语言处理(NLP)中,自回归语言建模的目标通常是在前向自回归分解下最大化似然 [148]。GPT [105] 和 GPT-2 [106] 使用 Transformer 解码器架构 [134] 来进行语言建模。与 GPT 不同,GPT-2 移除了不同任务的微调过程。为了学习能够泛化到不同任务的统一表示,GPT-2 模型通过 来实现,这意味着在给定不同任务的情况下,相同的输入可以产生不同的输出。
自回归模型也被应用于计算机视觉领域,例如 PixelRNN [133] 和 PixelCNN [131]。基本思想是使用自回归方法逐像素地建模图像。例如,图像中的下(右)方像素是基于上(左)方像素生成的。PixelRNN 和 PixelCNN 的像素分布分别由 RNN 和 CNN 建模。
自编码 (AE) 模型
Denoising AE Model
DAE 的架构与普通的 Autoencoder 类似,但在输入数据上加入了噪声。例如,给定一张干净的图片作为输入,模型会先人为地加入噪声(如高斯噪声或遮挡噪声),然后再利用编码器将含噪数据映射到隐空间,再由解码器进行重建,以还原出原始的干净图片。
DAE 的目标函数是最小化重建误差,使得模型能够在噪声数据的基础上尽可能还原无噪声的原始数据。常用的重建误差度量方法是均方误差(MSE),即:
其中, 表示原始数据, 表示模型输出。
Variational AE Model
传统的 Autoencoder 模型虽然可以学习到数据的特征表示,但缺乏生成能力。Variational Autoencoder 在普通 Autoencoder 的基础上引入了概率模型和变分推断,使得其不仅能够学习数据的隐含特征,还能生成与输入数据相似的新数据样本。
VAE 的结构与传统 Autoencoder 相似,包含编码器和解码器部分,但引入了概率分布的概念:
- 编码器:将输入数据映射到隐空间中的概率分布参数(均值 和标准差 )。
- 解码器:通过采样生成的隐变量,将其解码为数据分布的重建样本。
在编码阶段,VAE 不直接输出隐层表示,而是输出均值和方差参数,以构建隐变量的高斯分布。随后,通过重参数化技巧从这个分布中采样,以确保模型的可微性,使得梯度可以反向传播。
VAE 的目标函数由两部分组成:重构损失和正则化损失。
- 重构损失:确保重建数据与原始输入尽量接近,通常使用均方误差(MSE)或交叉熵。
- 正则化损失:鼓励隐变量的分布接近标准正态分布,使用Kullback-Leibler(KL)散度来衡量:
其中 是编码器输出的隐变量分布,而 是先验分布(通常设为标准正态分布)。
总的损失函数为:
这一目标函数实现了数据重构与隐空间结构化的平衡。
VAE 的工作流程如下:
- 编码阶段:编码器将输入数据映射到隐变量的均值和标准差,形成隐空间的高斯分布。
- 重参数化阶段:通过重参数化技巧从隐变量分布中采样,以确保可微性。
- 解码阶段:解码器根据采样隐变量,生成与原始输入相似的重建样本。
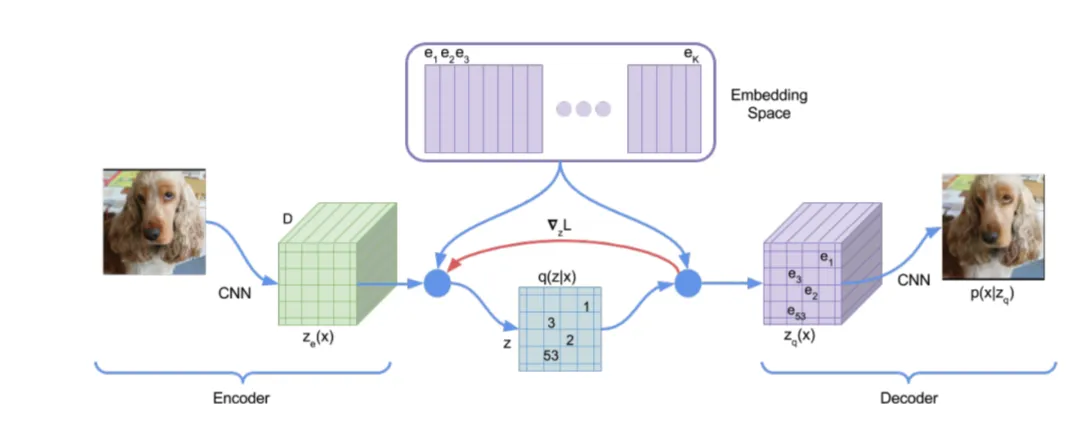
与 VAE 相比,VQ-VAE 用量化向量字典替换了原始的隐藏分布。此外,VQ-VAE 中的先验分布被替换为一个预训练的 PixelCNN,用于建模图像的层次特征。
深度度量学习家族:SimCLR/NNCLR/MeanSHIFT/SCL
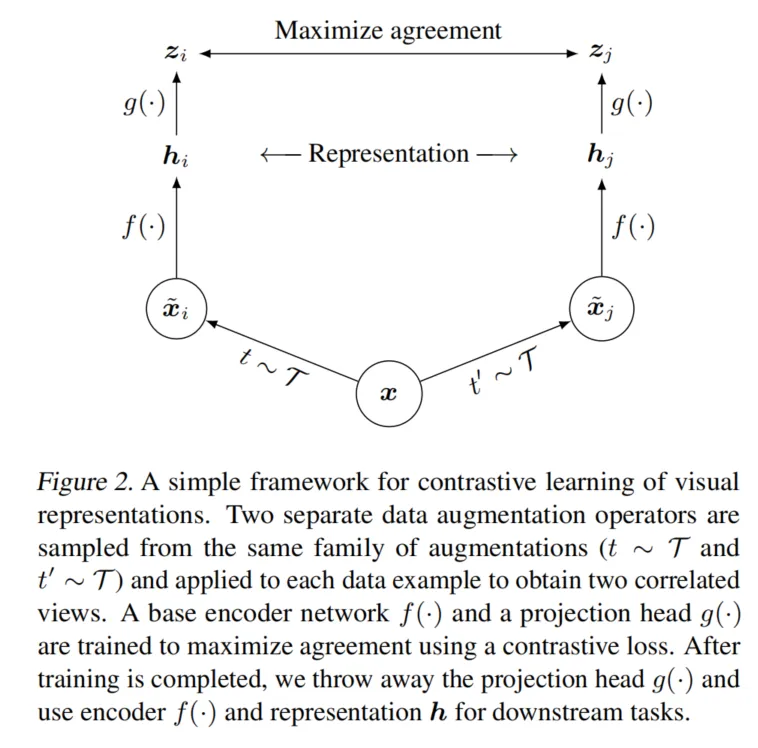
SimCLR:
NNCLR:
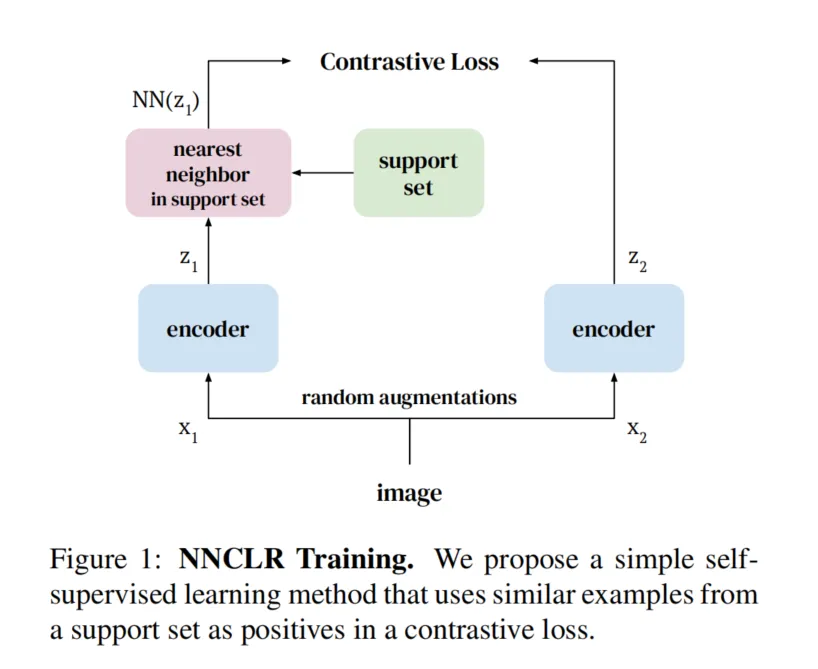
NNCLR和SimCLR都是基于对比学习的自监督学习方法,但它们在正样本选择和数据增强依赖上存在显著区别:
-
正样本选择:
- SimCLR:使用数据增强生成的同一图像的不同视图(例如随机裁剪、颜色扰动等)作为正样本。这些正样本实际上是同一个实例的变体,目标是让模型在潜在空间中保持这些变体的一致性。
- NNCLR:引入了“最近邻”的概念,利用潜在空间中的语义相似性,将来自支持集的最近邻样本作为正样本。也就是说,NNCLR选择的正样本不仅仅是同一图像的变体,还可能是不同图像但具有相似语义的样本。通过这种方式,NNCLR扩展了正样本的范围,提高了学习到的特征的泛化性。
-
数据增强的依赖:
- SimCLR:高度依赖于复杂的数据增强策略,以生成足够的图像变体,从而帮助模型学习有区分度的特征。例如SimCLR会应用随机裁剪、颜色抖动、高斯模糊等多种增强方法。
- NNCLR:减少了对复杂数据增强的依赖,因为通过最近邻搜索得到的正样本已经具有自然的语义多样性。实验表明,在仅使用简单随机裁剪的情况下,NNCLR的性能损失较小,这表明NNCLR在正样本构建上比SimCLR更为灵活。
-
性能表现:
- 在ImageNet分类任务中,NNCLR通过最近邻正样本构建策略显著提高了性能。在相同设置下,NNCLR比SimCLR提升了大约3.8%的Top-1准确率,这说明NNCLR的最近邻正样本策略比SimCLR的单实例变体策略效果更好。
SimCLR强调通过数据增强构造同一实例的不同视图,而NNCLR则利用潜在空间中的最近邻作为正样本,进一步扩展了正样本的语义多样性并减少了对数据增强的依赖,从而提升了模型的性能。
自蒸馏家族:BYOL/SimSIAM/DINO
BYOL 架构。BYOL(Bootstrap Your Own Latent)是一种自监督学习方法,其训练方式独特,不依赖负样本对,而是通过自举(bootstrap)机制逐步改进表示。
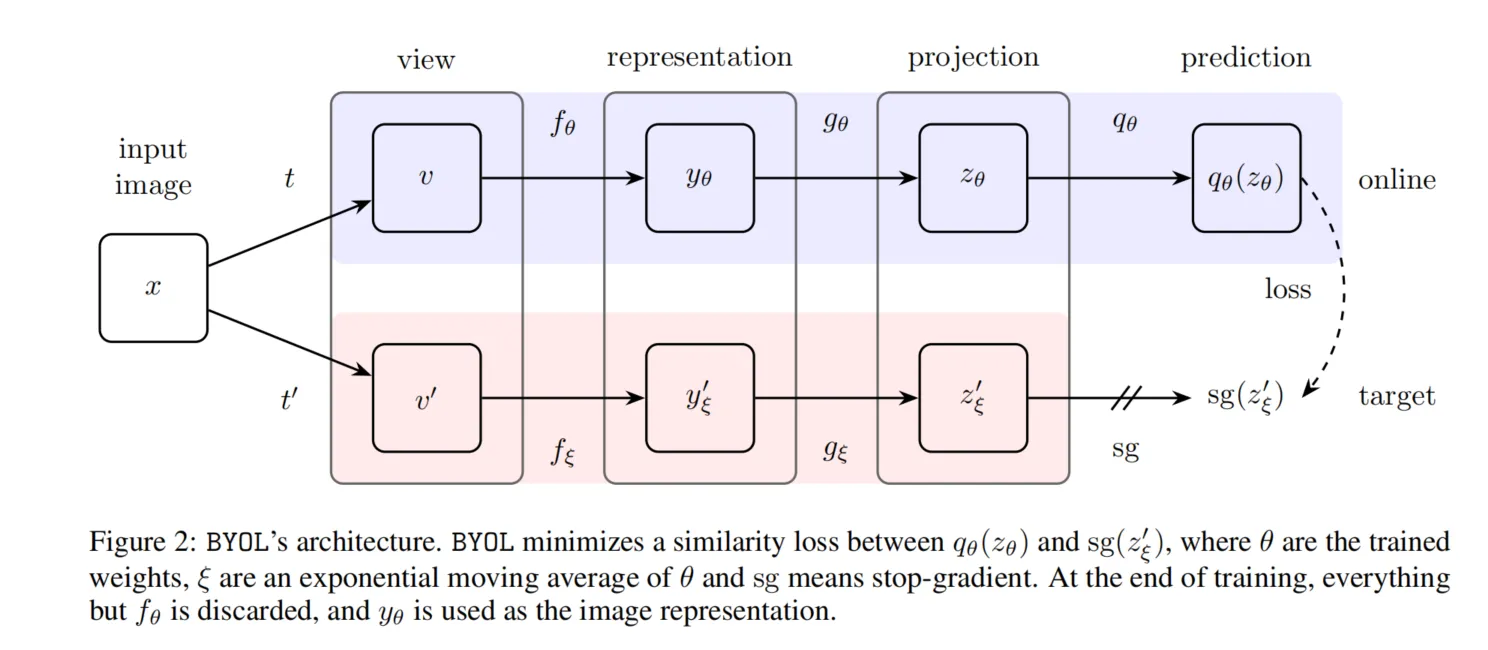
BYOL(Bootstrap Your Own Latent)是一种自监督学习方法,其训练方式独特,不依赖负样本对,而是通过自举(bootstrap)机制逐步改进表示。具体来说,BYOL 使用两个网络(在线网络和目标网络)来进行训练。以下是其训练过程的主要步骤:
1. 双网络结构
BYOL 包含两个神经网络:在线网络(online network)和目标网络(target network)。这两个网络结构相同,但参数独立。在线网络的参数是 ,目标网络的参数是 。
-
在线网络 包括三个模块:
- 编码器 :将输入图像变换为表示(representation)。
- 投影器 :将表示投影到更低维的空间,以便于后续计算。
- 预测器 :生成一个预测输出,用于与目标网络的投影进行比较。
-
目标网络 与在线网络的结构相同,但没有预测器。目标网络的参数是在线网络参数的指数移动平均更新(EMA),确保其更新速度较慢,从而保持一定的稳定性。
2. 数据增强与视图生成
BYOL 从数据集中随机采样一张图像,然后通过两种不同的数据增强(如裁剪、翻转、颜色扰动等)生成该图像的两个不同视图。这两个视图被输入到在线网络和目标网络中,用于学习表示。
3. 前向传播与表示学习
- 第一个增强视图 输入在线网络,生成表示 ,然后通过投影器生成投影 。
- 第二个增强视图 输入目标网络,生成目标表示 ,再通过投影器生成目标投影 。
4. 预测与损失计算
- 在线网络生成的投影 通过预测器 进行预测,得到预测结果 。
- 对 和 进行 归一化,然后计算二者之间的均方误差损失:
- 为对称化损失,BYOL 还会将增强视图交换(即将 输入在线网络,将 输入目标网络),计算另一个损失 。最终损失为:
5. 参数更新
- 使用随机梯度下降(SGD)或类似优化器,仅针对在线网络的参数 优化损失 ,而目标网络的参数 通过 EMA 更新:
其中, 是衰减因子,控制目标网络的更新速度(通常设定在 0.99 或更高,以保持稳定性)。
6. 训练细节与停止梯度
- 在目标网络中,梯度是“停止”的,即不会反向传播梯度到目标网络的参数,这种设计避免了目标网络直接受到在线网络参数更新的影响。
- BYOL 通过迭代上述过程,不断更新在线网络的参数和目标网络的 EMA,使得在线网络能够逐步学习到稳定而有用的表示。
7. 最终模型
训练结束后,只保留在线网络的编码器部分 ,用于下游任务。预测器和投影器部分在最终模型中通常不保留,因为它们主要用于自监督学习阶段的优化,而非下游任务的实际表示使用。
BYOL 的训练方法通过自举过程,不需要负样本对,从而避免了对比学习中的一些缺点(如对大批量数据和复杂的负样本选择的依赖)。它通过在线网络和目标网络的协同训练,实现了无监督条件下的高质量表示学习。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!