目录
项目地址及配置指南
我们使用合成数据和经过筛选的公开数据来训练我们的模型。该模型已在 10 亿张图像上进行了预训练。微调数据包括 3000 万张专注于特定视觉内容和风格的高质量美学图像,以及 300 万张偏好数据图像。
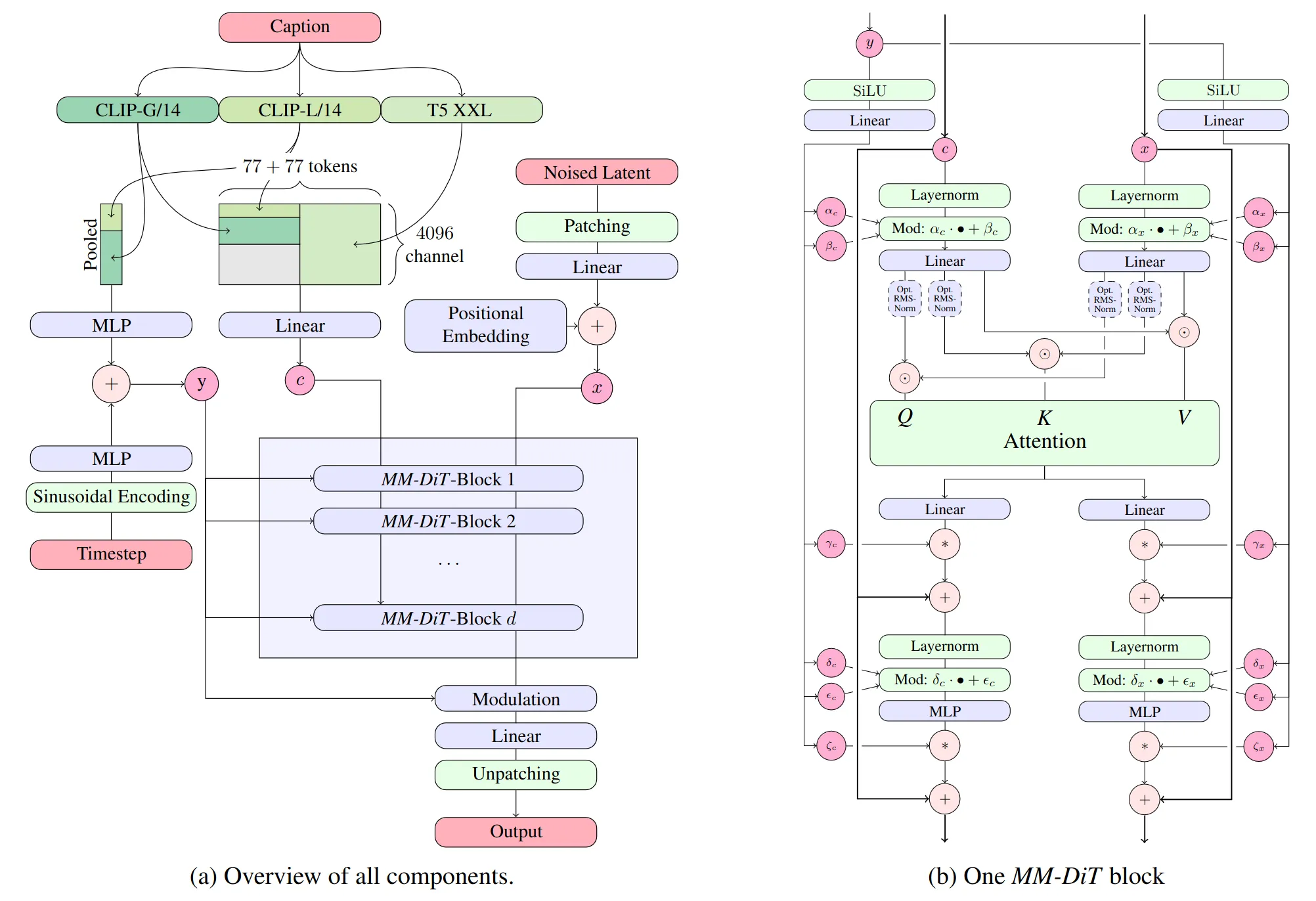
项目地址:Stable Diffusion 3 Medium
为了顺利拉取项目资源,您需要科学上网,并获取 Hugging Face Token。下面是获取 Token 的步骤。
如何获取 Hugging Face Token
- 前往 Hugging Face 官方教程,了解 Token 相关信息。
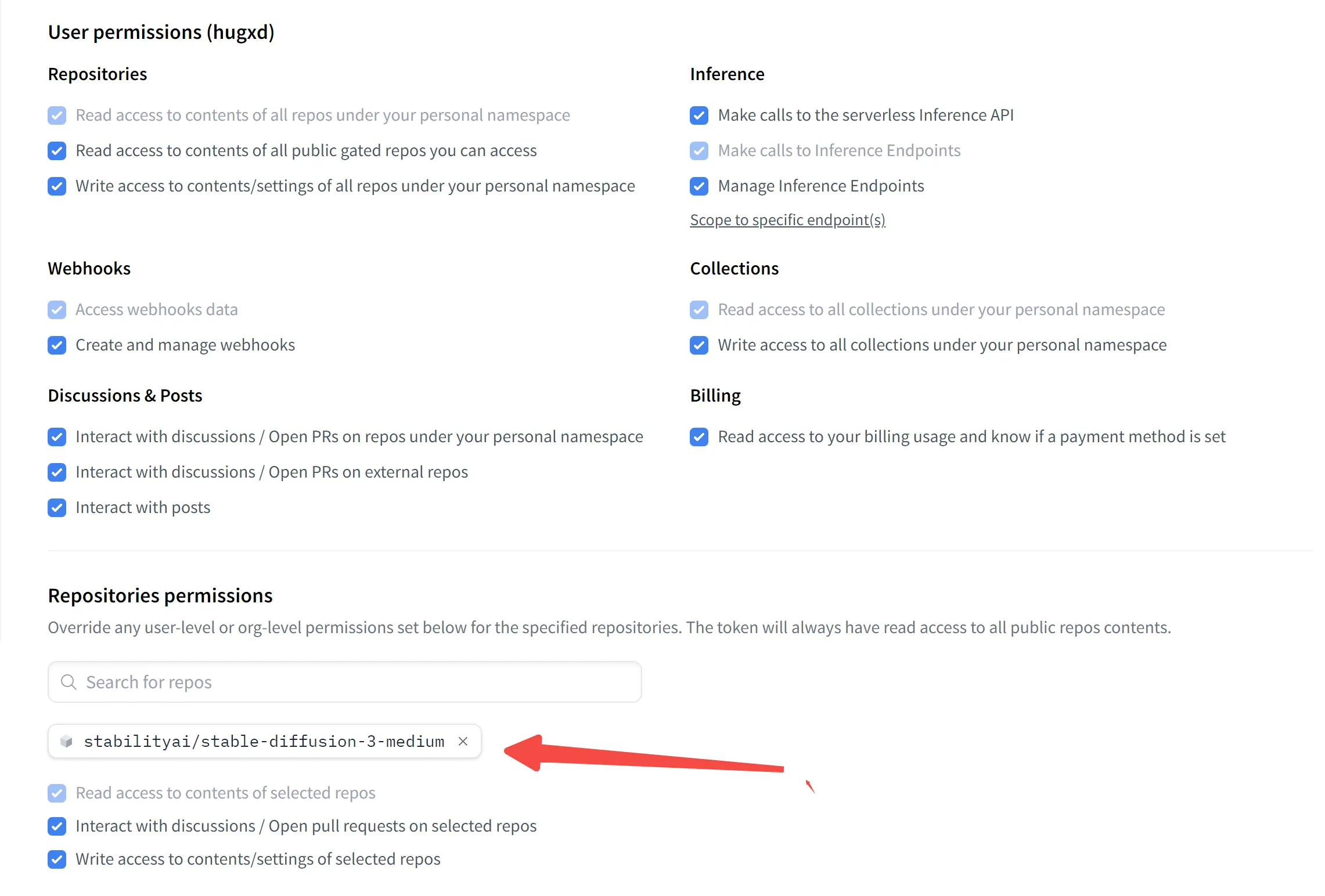
- 访问 Hugging Face Token 管理页面,并确保您已注册或登录账号。
- 在 Token 页面点击“新增 Token”,并确保赋予仓库访问权限。参考下图:
- 成功生成的 Token 格式类似如下:
展开代码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
复制并保存该 Token。
环境配置
接下来,使用 Conda 创建一个 Python 3.10 及以上版本的虚拟环境。
bash展开代码conda create -n py310bizhi python=3.10 -y
conda activate py310bizhi
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia -y
pip install torchao --extra-index-url https://download.pytorch.org/whl/cu121 # full options are cpu/cu118/cu121/cu124
pip install git+https://github.com/xhinker/sd_embed.git@main
并安装以下依赖包:
bash展开代码pip install git+https://github.com/huggingface/diffusers.git pip install -U transformers accelerate sentencepiece peft
运行代码
完成环境配置后,下载并执行以下链接中的 app.py 文件。该代码会自动拉取项目仓库内容,并生成一个基于 Gradio 的前端页面:
需要修改app.py里面的Token变量。
也就是这个: https://huggingface.co/spaces/ameerazam08/SD-3-Medium-GPU/blob/main/app.py
下载仓库代码解读
代码是:
python展开代码import os
import random
import uuid
import gradio as gr
import numpy as np
from PIL import Image
import spaces
import torch
from diffusers import StableDiffusion3Pipeline, DPMSolverMultistepScheduler, AutoencoderKL
from huggingface_hub import snapshot_download
huggingface_token = os.getenv("HF_TOKEN")
model_path = snapshot_download(
repo_id="stabilityai/stable-diffusion-3-medium",
# revision="refs/pr/26", # 这个删除就可以下载最新代码
repo_type="model",
ignore_patterns=["*.md", "*..gitattributes"],
local_dir="stable-diffusion-3-medium",
token=huggingface_token,
)
这段代码主要用于从 Hugging Face Hub 下载特定的模型仓库(repository)到本地。下面逐步解释代码的功能及其具体操作:
-
导入必要的库和模块:
-
- os:用于与操作系统进行交互,如获取环境变量。
- random 和 uuid:用于生成随机数和唯一标识符,可能在后续代码中用于生成随机输入或标识。
- gradio:用于构建用户界面,可能用于展示生成的图像或接受用户输入。
- numpy 和 PIL:用于处理图像数据。
- spaces 和 torch:与 Hugging Face 的 Spaces 和 PyTorch 相关,用于深度学习模型的加载和运行。
- diffusers 模块中的类:用于处理和运行稳定扩散模型(Stable Diffusion)。
- huggingface_hub.snapshot_download:用于从 Hugging Face Hub 下载模型的快照。
-
获取 Hugging Face 的访问令牌:
python展开代码huggingface_token = os.getenv("HF_TOKEN")这里通过环境变量
HF_TOKEN获取 Hugging Face 的访问令牌,用于身份验证和授权访问私有模型或需要权限的资源。 -
下载模型仓库的快照:
python展开代码model_path = snapshot_download( repo_id="stabilityai/stable-diffusion-3-medium", revision="refs/pr/26", repo_type="model", ignore_patterns=["*.md", "*..gitattributes"], local_dir="stable-diffusion-3-medium", token=huggingface_token, )- repo_id:指定要下载的仓库名称,这里是
"stabilityai/stable-diffusion-3-medium",即稳定扩散 3 中等版本的模型。 - revision:指定要下载的特定版本或分支,这里是
"refs/pr/26",通常表示一个 Pull Request 的第 26 号。 - repo_type:指定仓库类型,这里是
"model",表示这是一个模型仓库。 - ignore_patterns:指定要忽略的文件模式,这里忽略了所有
.md文件和.gitattributes文件,避免下载不必要的文档或配置文件。 - local_dir:指定本地保存目录,这里设置为
"stable-diffusion-3-medium",即当前工作目录下的一个名为stable-diffusion-3-medium的文件夹。 - token:使用前面获取的 Hugging Face 访问令牌进行身份验证。
功能说明:
snapshot_download函数会从 Hugging Face Hub 下载指定仓库的快照(即特定版本的文件集合)。- 由于指定了
ignore_patterns,并不会下载整个仓库,而是排除了匹配这些模式的文件。 - 下载的内容会保存在当前工作目录下的
stable-diffusion-3-medium文件夹中。如果该文件夹不存在,函数会自动创建。
- repo_id:指定要下载的仓库名称,这里是
-
总结:
- 是否下载完整的仓库:不完全是。代码通过
ignore_patterns参数排除了部分文件(如.md和.gitattributes文件),因此下载的内容是仓库的一个子集,主要是模型相关的文件,而非整个仓库的所有内容。 - 下载位置:下载的文件会保存在当前工作目录下名为
stable-diffusion-3-medium的文件夹中。你可以在运行脚本的目录中找到这个文件夹,里面包含了下载的模型文件和相关资源。
- 是否下载完整的仓库:不完全是。代码通过
如果你希望查看下载的具体内容,可以进入 stable-diffusion-3-medium 文件夹,查看其中的文件和子目录。此外,如果需要下载整个仓库而不忽略任何文件,可以移除或调整 ignore_patterns 参数。
最新仓库
删除代码里这一行,从而下载到最新的仓库文件:revision="refs/pr/26"
修改后就可以下载最新的模型:_medium_incl_clips_t5xxlfp16.safetensors
推理教程
https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_3
推理代码
介绍:
- sd3_medium.safetensors 包括 MMDiT 和 VAE 权重,但不包括任何文本编码器。
- sd3_medium_incl_clips_t5xxlfp16.safetensors包含所有必要的权重,包括 T5XXL 文本编码器的 fp16 版本。
- sd3_medium_incl_clips_t5xxlfp8.safetensors包含所有必要的权重,包括 T5XXL 文本编码器的 fp8 版本,在质量和资源要求之间提供平衡。
- sd3_medium_incl_clips.safetensors包括除 T5XXL 文本编码器之外的所有必要权重。它需要的资源很少,但如果没有 T5XXL 文本编码器,模型的性能会有所不同。
- 该text_encoders文件夹包含三个文本编码器及其原始模型卡链接,以方便用户使用。text_encoders 文件夹中的所有组件(以及嵌入在其他包中的等效组件)均受其各自的原始许可证约束。
- 该example_workfows文件夹包含舒适的工作流程示例。
登录,输入指令后给Token:
bash展开代码huggingface-cli login
然后执行推理代码:
sd3_medium_incl_clips_t5xxlfp16.safetensors推理代码:
python展开代码import torch
from diffusers import StableDiffusion3Pipeline
# 从单一文件加载模型,并启用 T5XXL 文本编码器 (fp16 版本)
pipe = StableDiffusion3Pipeline.from_single_file(
"/ssd/xiedong/SD-3-Medium-GPU/stable-diffusion-3-medium/sd3_medium_incl_clips_t5xxlfp16.safetensors",
torch_dtype=torch.float16,
)
# 启用 CPU 模型卸载以节省显存资源
pipe.enable_model_cpu_offload()
# 将模型移动到 GPU
pipe.to("cuda")
# 设置生成图片的提示词 (prompt)
prompt = "a picture of a cat holding a sign that says hello world"
# 执行推理并生成图像
image = pipe(
prompt=prompt,
num_inference_steps=28, # 设置推理步数
height=1024, # 设置图像高度
width=1024, # 设置图像宽度
guidance_scale=7.0, # 设置引导比例
).images[0]
# 保存生成的图像
image.save('sd3_t5_fp16_output.png')
这样就可以得到一只肥猫:

最佳实践
在提示词的使用上,SD3 引入了显著的变化,现在用户可以输入长达 10,000 个字符的提示词。这一突破极大地拓展了我们与模型互动的空间,克服了以往 CLIP 文本编码器仅支持 77 个令牌的限制。虽然提示词过长可能会让模型忽略部分内容,但这一功能却极大提升了模型在生成图像时对提示词的遵从度,帮助用户实现更加精细的控制。
然而,值得注意的是,SD3 在训练过程中并未使用负向提示词。因此,负向提示词在这个模型中可能不会如预期那样有效,甚至会带来噪音或不必要的输出变化。这意味着,我们需要重新审视提示词的使用策略。
对于撰写提示词,建议大家使用清晰、详细的描述性语句,而不是简单的关键词堆叠。这将有助于模型更好地理解我们的意图,从而生成更符合预期的图像。
占用显存
删除这句后pipe.enable_model_cpu_offload(),占用显存17G左右。

多进程生图
将文本'res_answer.txt'里每一行都用来生图,3个进程,一个显卡里一个进程:
python展开代码import torch
from diffusers import StableDiffusion3Pipeline
import multiprocessing
import os
# 从文件中读取所有提示词
def read_prompts(file_path):
with open(file_path, 'r') as file:
prompts = file.readlines()
return [prompt.strip() for prompt in prompts]
# 每个进程的工作函数
def generate_images(gpu_id, prompts, start_idx):
# 加载模型
pipe = StableDiffusion3Pipeline.from_single_file(
"/ssd/xiedong/SD-3-Medium-GPU/stable-diffusion-3-medium/sd3_medium_incl_clips_t5xxlfp16.safetensors",
torch_dtype=torch.float16,
)
# 将模型移动到对应的 GPU
pipe.to(f"cuda:{gpu_id}")
# 生成图像
for i, prompt in enumerate(prompts):
image = pipe(
prompt=prompt,
num_inference_steps=28,
height=1024,
width=1024,
guidance_scale=7.0,
).images[0]
# 保存图像,文件名从 start_idx 开始递增
image_path = f"img_sd3/{start_idx + i:04d}.png"
image.save(image_path)
print(f"GPU {gpu_id}: Saved image {image_path}")
if __name__ == "__main__":
# 提示词文件路径
prompt_file = 'res_answer.txt'
prompts = read_prompts(prompt_file)
# 将提示词分成三份,分别由三个进程处理
num_gpus = 3
prompts_split = [prompts[i::num_gpus] for i in range(num_gpus)]
# 创建多个进程
processes = []
for gpu_id in range(num_gpus):
start_idx = gpu_id * len(prompts_split[gpu_id])
p = multiprocessing.Process(target=generate_images, args=(gpu_id, prompts_split[gpu_id], start_idx))
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()
更高级的生图代码-突破77 tokens 限制
需要这个库,克服77个tokens限制:
https://github.com/xhinker/sd_embed?tab=readme-ov-file#stable-diffusion-3
安装sd_embed:
bash展开代码pip install torchao --extra-index-url https://download.pytorch.org/whl/cu121 # full options are cpu/cu118/cu121/cu124
pip install git+https://github.com/xhinker/sd_embed.git@main
就可以跑生图:
bash展开代码import gc
import torch
from diffusers import StableDiffusion3Pipeline
from sd_embed.embedding_funcs import get_weighted_text_embeddings_sd3
# 加载模型
pipeline = StableDiffusion3Pipeline.from_single_file(
"/ssd/xiedong/SD-3-Medium-GPU/stable-diffusion-3-medium/sd3_medium_incl_clips_t5xxlfp16.safetensors",
torch_dtype=torch.float16,
)
# 将模型移动到对应的 GPU
pipeline.to('cuda:0')
prompt = """\
A cyberpunk cockpit of a futuristic aircraft, filled with glowing screens and intricate controls, surrounded by sleek metallic panels. The cabin is illuminated by a spectrum of neon colors, primarily vibrant blues and purples, creating a high-tech ambiance. Through the large, panoramic windows, a sprawling metropolis can be seen below, with bright neon lights and bustling streets, reflecting the essence of a thriving city at night. The cockpit is framed with high-definition digital readouts displaying flight data, while a pilot, clad in an illuminated visor and tactical gear, focuses intently on the controls. The scene is dynamic, with a sense of speed emphasized by streaks of light visible through the windows, captured in sharp detail using a super long lens.
"""
neg_prompt = """\
deformed, distorted, disfigured, poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, mutated hands and fingers, disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation, NSFW
"""
(
prompt_embeds
, prompt_neg_embeds
, pooled_prompt_embeds
, negative_pooled_prompt_embeds
) = get_weighted_text_embeddings_sd3(
pipeline
, prompt=prompt
, neg_prompt=neg_prompt
)
image = pipeline(
prompt_embeds=prompt_embeds
, negative_prompt_embeds=prompt_neg_embeds
, pooled_prompt_embeds=pooled_prompt_embeds
, negative_pooled_prompt_embeds=negative_pooled_prompt_embeds
, num_inference_steps=30
, height=1024
, width=1024 + 512
, guidance_scale=4.0
, generator=torch.Generator('cuda:0').manual_seed(2)
).images[0]
# 构建保存路径和文件名
image_filename = f"1.png"
# 保存图像
image.save(image_filename)
del prompt_embeds, prompt_neg_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
gc.collect()
torch.cuda.empty_cache()
效果是ok的:

警告是正常的,不用理会:
Token indices sequence length is longer than the specified maximum sequence length for this model (107 > 77). Running this sequence through the model will result in indexing errors

数据为json格式:
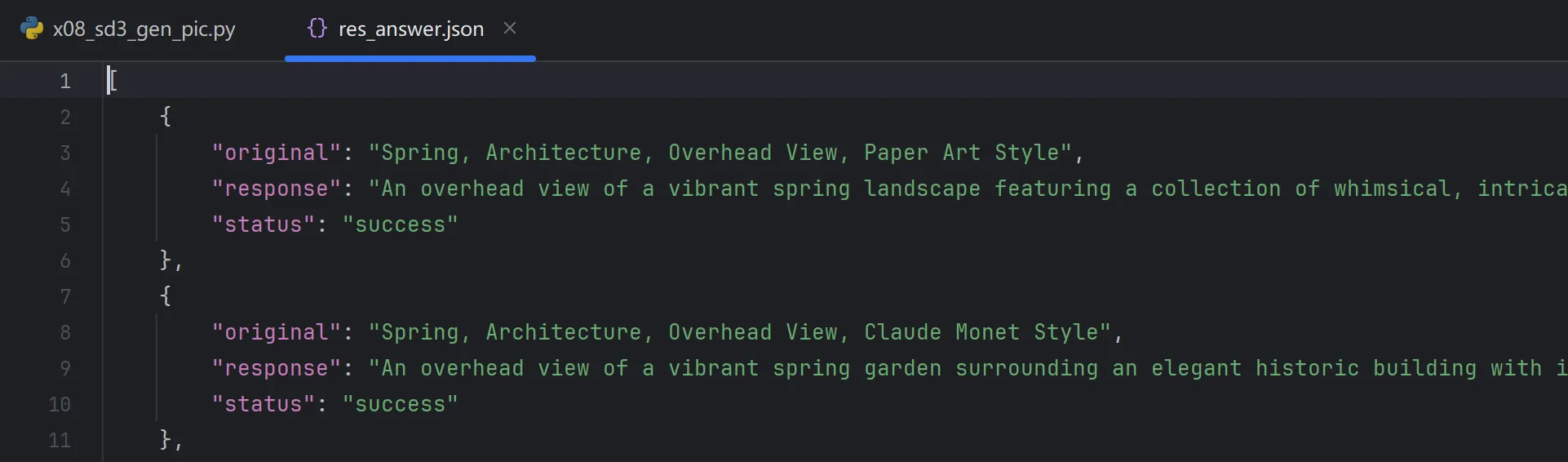
多进程跑这些数据生图:
bash展开代码import torch
from diffusers import StableDiffusion3Pipeline
import multiprocessing
import os
import json
import gc
import torch
from diffusers import StableDiffusion3Pipeline
from sd_embed.embedding_funcs import get_weighted_text_embeddings_sd3
# 从JSON文件中读取所有response提示词
def read_prompts(file_path):
with open(file_path, 'r') as file:
data = json.load(file)
# 提取所有状态为 "success" 的 response 字段
return [entry['response'] for entry in data if entry['status'] == 'success']
# 创建保存图像的目录
def create_directory(directory_path):
if not os.path.exists(directory_path):
os.makedirs(directory_path)
# 保存提示词到文本文件
def save_prompt_to_txt(file_path, prompt):
with open(file_path, 'w') as file:
file.write(prompt)
# 每个进程的工作函数
def generate_images(gpu_id, prompts, start_idx):
# 加载模型
pipeline = StableDiffusion3Pipeline.from_single_file(
"/ssd/xiedong/SD-3-Medium-GPU/stable-diffusion-3-medium/sd3_medium_incl_clips_t5xxlfp16.safetensors",
torch_dtype=torch.float16,
)
# 将模型移动到对应的 GPU
pipeline.to(gpu_id)
# 生成图像
for i, prompt in enumerate(prompts):
neg_prompt = """\
deformed, distorted, disfigured, poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, mutated hands and fingers, disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation, NSFW
"""
(
prompt_embeds
, prompt_neg_embeds
, pooled_prompt_embeds
, negative_pooled_prompt_embeds
) = get_weighted_text_embeddings_sd3(
pipeline
, prompt=prompt
, neg_prompt=neg_prompt
)
image = pipeline(
prompt_embeds=prompt_embeds
, negative_prompt_embeds=prompt_neg_embeds
, pooled_prompt_embeds=pooled_prompt_embeds
, negative_pooled_prompt_embeds=negative_pooled_prompt_embeds
, num_inference_steps=30
, height=1024
, width=1024 + 512
, guidance_scale=4.0
, generator=torch.Generator(gpu_id).manual_seed(2)
).images[0]
# 构建保存路径和文件名
image_filename = f"img_sd3/{start_idx + i:04d}.png"
txt_filename = f"img_sd3/{start_idx + i:04d}.txt"
# 保存图像
image.save(image_filename)
# 保存提示词到文本文件
save_prompt_to_txt(txt_filename, prompt)
print(f"GPU {gpu_id}: Saved image {image_filename} and prompt text {txt_filename}")
del prompt_embeds, prompt_neg_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
gc.collect()
torch.cuda.empty_cache()
if __name__ == "__main__":
multiprocessing.set_start_method('spawn')
# JSON文件路径
json_file = 'res_answer.json'
prompts = read_prompts(json_file)
# 创建保存图像和文本文件的目录
output_dir = 'img_sd3'
create_directory(output_dir)
# 定义任务列表,指定每个进程要使用的GPU
tasks = ["cuda:0", "cuda:1", "cuda:2"] # 可以根据需求修改此列表来控制进程和GPU的分配
# 将提示词分成与tasks长度相等的份数
num_tasks = len(tasks)
prompts_split = [prompts[i::num_tasks] for i in range(num_tasks)]
# 创建多个进程
processes = []
for idx, gpu_id in enumerate(tasks):
start_idx = idx * len(prompts_split[idx])
p = multiprocessing.Process(target=generate_images, args=(gpu_id, prompts_split[idx], start_idx))
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!