目录
训练 StableTTS:结合 Flow-Matching 和 DiT 的下一代语音合成模型
在这篇文章中,我将带你深入了解如何训练 StableTTS V1.1,这是一个结合了 flow-matching 和 Diffusion Transformer(DiT) 的下一代开源文本转语音(TTS)模型。受 Stable Diffusion 3 的启发,该模型针对中文、英文和日文的多语言语音生成进行了优化,音质和性能得到了显著提升。
https://github.com/KdaiP/StableTTS
StableTTS 简介
StableTTS 是一个 轻量且快速 的 TTS 模型,拥有 3100 万个参数,专为 文本转语音生成 设计,无需额外的特征提取或说话人身份识别。其模型架构结合了多项创新技术:
- Flow-matching 解码器:通过添加 跳跃连接 和 FiLM 层(用于条件化时间步嵌入),提升模型性能。
- 余弦时间步调度器:用于更好的收敛性和更优质的音频输出。
- 多语言支持:能够在单一模型中支持多语言的训练。
- 改进的注意力掩码:修复了之前版本中的问题,这些问题曾影响音频质量。
训练环境
bash展开代码cd /root/xiedong/tts
git clone https://github.com/KdaiP/StableTTS.git
# 运行镜像
docker run -it --shm-size=16g --env=is_half=False --gpus all --net host -v /root/xiedong/tts:/root/xiedong/tts pytorch/pytorch:2.4.1-cuda12.1-cudnn9-devel bash
# 进入
cp -r /root/xiedong/tts/StableTTS ./
cd StableTTS/
pip install -r requirements.txt
pip install gradio matplotlib
apt update && apt install vim wget curl git -y
echo 'export LD_LIBRARY_PATH=/opt/conda/lib/python3.11/site-packages/torch/lib:$LD_LIBRARY_PATH' >> ~/.bashrc
apt-get update && apt-get install -y locales
locale-gen zh_CN.UTF-8
echo 'export LANG=zh_CN.UTF-8' >> ~/.bashrc
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
# 清理 pip 缓存
rm -rf /root/.cache/pip
docker commit 95990619dbea kevinchina/deeplearning:pytorch-2.4.1-cuda12.1-cudnn9-devel-stablettsv1.1
启动:
bash展开代码docker run -it --shm-size=16g --env=is_half=False --gpus all --net host -v /root/xiedong/tts:/root/xiedong/tts kevinchina/deeplearning:pytorch-2.4.1-cuda12.1-cudnn9-devel-stablettsv1.1 bash
准备数据
bash展开代码cd /workspace/StableTTS
仓库提供了脚本和示例,位于 ./recipes 目录中,供生成文件列表。长这样:
bash展开代码./audio1.wav|你好,世界。 ./audio2.wav|Hello, world.
对于 多语言数据集,请确保通过调整 preprocess.py DataConfig 单独处理不同语言的数据。模型本身是要么用于中文、要么用于英文,不能中英混合训练。
运行预处理脚本。该脚本会生成所需的 mel 频谱图 和 音素序列,并将其存储在一个 JSON 文件中,你将需要这些文件用于训练。
bash展开代码python preprocess.py
我直接向 ./filelists/filelist.txt 写入标记,然后执行 python preprocess.py 。执行的时候要升级一下:pip install --upgrade numpy pyopenjtalk
这样就成功:

训练模型
数据准备完成后,接下来就是配置并开始训练。你可以选择从头开始训练,也可以利用提供的 预训练模型 进行微调。
-
调整训练配置: 在
config.py中,修改TrainConfig,将其指向你的文件列表,并根据需要设置训练参数,例如batch_size、learning_rate和num_epochs。 -
启动训练: 运行以下命令启动训练:
bash展开代码pip install numpy==2.0 python train.py -
监控进展: 该模型提供了详细的训练日志。特别留意 Mel 频谱图 损失,确保模型正在正确收敛。
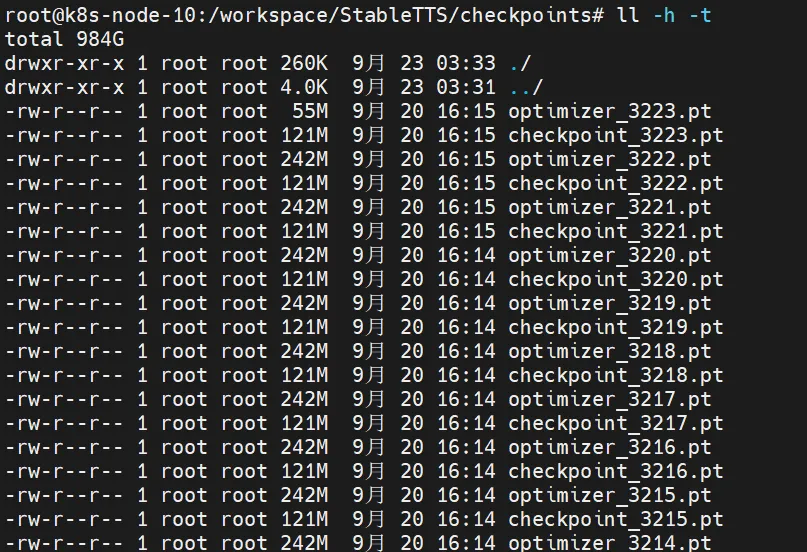
训练后的模型在这里:
微调模型
StableTTS 支持对 预训练模型 进行微调。下载预训练模型并将其放置在 TrainConfig 中指定的路径中,训练脚本会自动加载该模型并继续用你的数据进行训练。
对于声码器(vocoder)的微调,建议使用 FireflyGAN 或 Vocos。这两种声码器与 StableTTS 无缝集成,处理 mel-to-wav 转换 时的保真度非常高。
推理与 WebUI
训练完成后,你可以使用提供的 推理笔记本 (inference.ipynb) 测试模型。你还可以通过 Gradio 启动的 WebUI 提供服务。
-
本地运行推理:
bash展开代码pip install notebook jupyter notebook --allow-root --ip 0.0.0.0 --port 8888 --no-browserbash展开代码python inference.ipynb -
部署 WebUI:
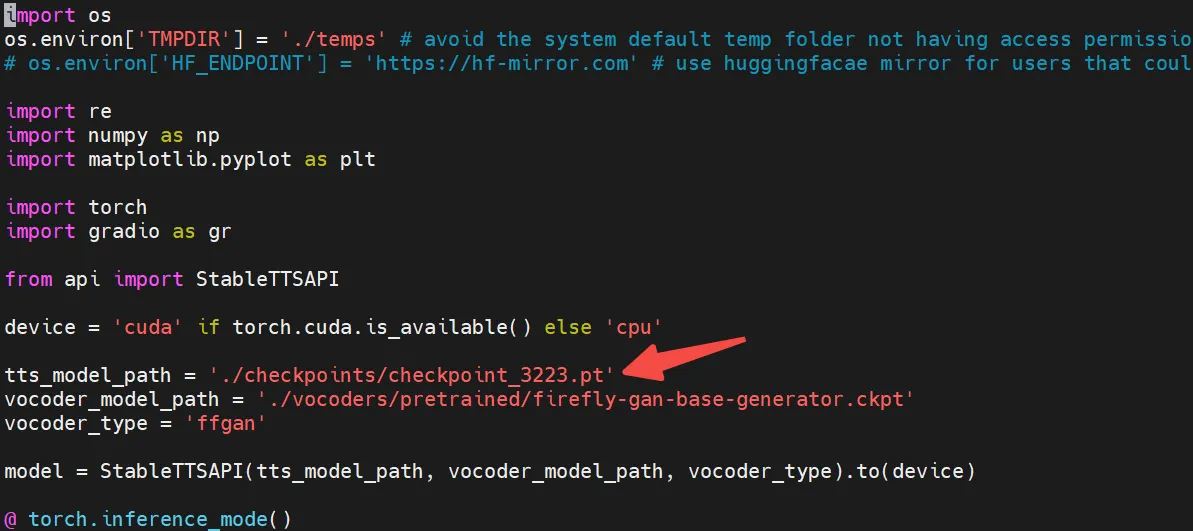
修改webui.py这里的checkpoint:
可通过运行以下命令启动基于 Gradio 的 WebUI:
bash展开代码python webui.py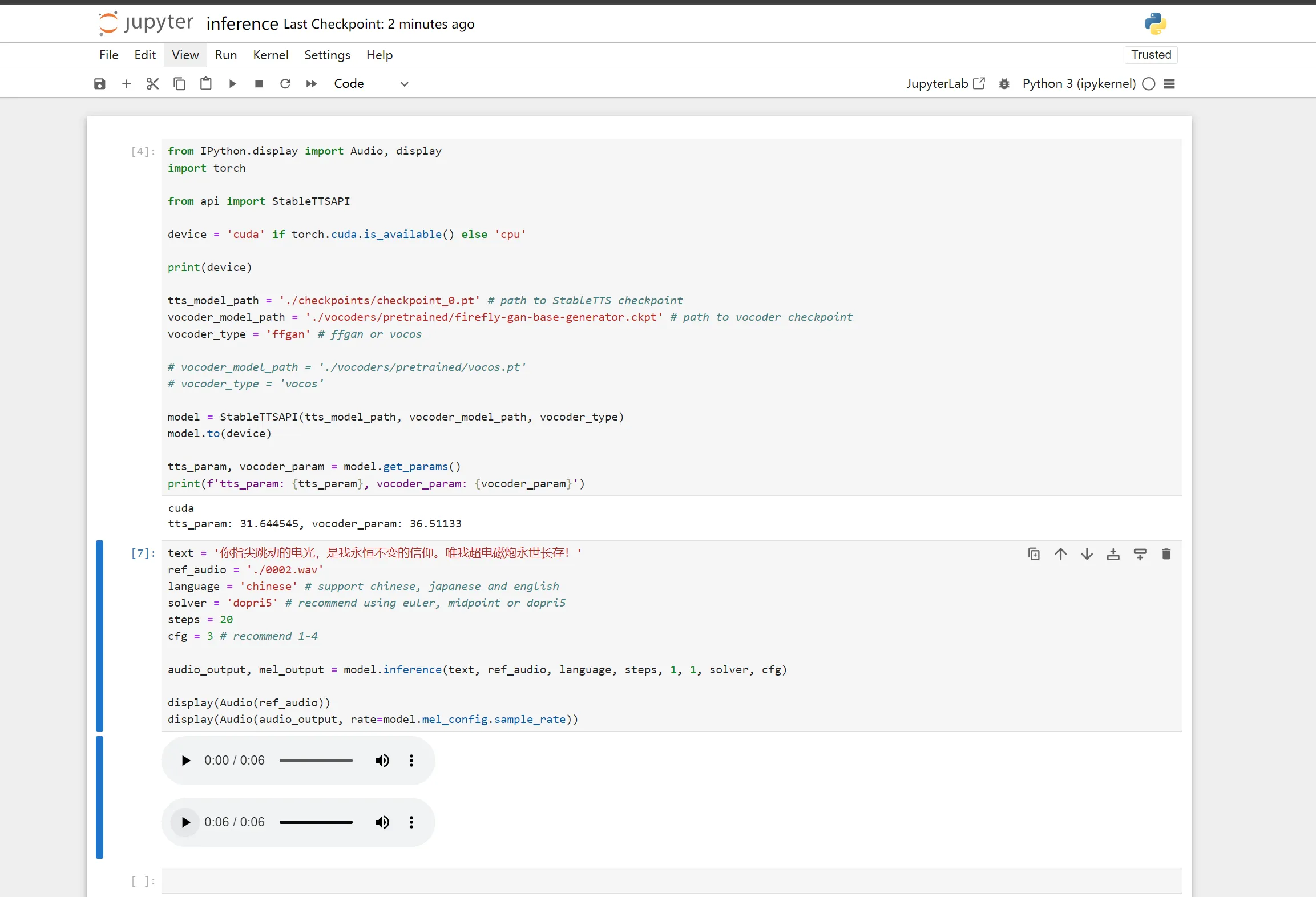
StableTTS 的关键创新
以下是使 StableTTS 独具一格的亮点:
- Flow-matching 解码器中的跳跃连接:改进了长时依赖关系,确保语音更加流畅。
- 无分类器引导(CFG):允许更好地控制语音生成。
- ODE 求解器:使用
torchdiffeq进行高效的微分方程求解,这对于生成高质量的 mel 频谱图至关重要。 - FireflyGAN 声码器:提供逼真的波形生成能力。
- 多语言 TTS:无缝支持中、英、日语,无需为每种语言单独训练模型。
未来发展方向
根据最新的路线图,StableTTS V2.0 将引入 自回归模型,提供更好的韵律控制,进一步提升自然语音合成的边界。请关注即将发布的版本,社区将继续优化这一先进的 TTS 模型。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!