目录
Fish Speech 1.4:开源多语言语音合成与克隆解决方案
项目概述
Fish Speech 1.4 是一个领先的开源多语言语音合成模型,具备语音克隆功能。该模型基于大量的音频数据训练而成,支持多种语言,并且可以轻松部署和集成到各种应用中。
- 项目地址: GitHub - fishaudio/fish-speech
- 许可证: CC-BY-NC-SA-4.0(模型)和 BSD-3-Clause(源代码)
主要特性
多语言支持
Fish Speech 1.4 支持以下8种语言,覆盖了全球主要的语言需求:
- 英语 (English): ~300,000小时
- 中文 (Chinese): ~300,000小时
- 德语 (German): ~20,000小时
- 日语 (Japanese): ~20,000小时
- 法语 (French): ~20,000小时
- 西班牙语 (Spanish): ~20,000小时
- 韩语 (Korean): ~20,000小时
- 阿拉伯语 (Arabic): ~20,000小时
丰富的多语言支持使得 Fish Speech 1.4 能够满足全球不同用户的需求,广泛应用于跨语言的应用场景中。
语音克隆
除了基本的文本转语音功能,Fish Speech 1.4 还具备语音克隆能力。用户可以通过提供少量的目标语音样本,克隆出个性化的语音模型,实现更加自然和个性化的语音输出。
大规模训练数据
Fish Speech 1.4 基于 700,000小时 的音频数据进行训练,确保了模型的高质量和广泛适应性。庞大的训练数据量使得模型在不同语言和不同语境下都能表现出色。
易于部署
项目提供了完善的 Docker 支持,简化了本地部署的流程。开发者可以通过 Docker 容器快速启动和运行 Fish Speech 1.4,轻松集成到现有系统中。
活跃的社区与持续更新
Fish Speech 项目在 GitHub 上拥有 11.9k 星,906 个 Fork,并且有 43 位贡献者。团队和社区成员不断优化和更新项目,确保其在技术前沿保持领先。
微调项目实战
打包一个镜像
以下实现都要魔法:
bash展开代码# 进自己的目录
cd /root/xiedong/tts
# 拉代码
git clone https://github.com/fishaudio/fish-speech.git
# 进入项目
cd fish-speech/
# 拉模型
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
# china 拉模型这么拉
HF_ENDPOINT=https://hf-mirror.com huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
# 运行镜像
docker run -it --shm-size=16g --env=is_half=False --gpus all --net host -v /root/xiedong/tts:/root/xiedong/tts pytorch/pytorch:2.4.1-cuda12.1-cudnn9-devel bash
# 进入
mv /root/xiedong/tts/fish-speech/
cd /workspace/fish-speech
# 安装 fish-speech
pip3 install -e .[stable]
# (Ubuntu / Debian 用户) 安装 sox + ffmpeg
apt update && apt install libsox-dev ffmpeg -y
apt update && apt install vim wget curl -y
echo 'export LD_LIBRARY_PATH=/opt/conda/lib/python3.11/site-packages/torch/lib:$LD_LIBRARY_PATH' >> ~/.bashrc
apt-get update && apt-get install -y locales
locale-gen zh_CN.UTF-8
echo 'export LANG=zh_CN.UTF-8' >> ~/.bashrc
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
# 清理 pip 缓存
rm -rf /root/.cache/pip
推入镜像,以后这样操作就可以:
bash展开代码docker run -it --shm-size=16g --env=is_half=False --gpus all --net host -v /root/xiedong/tts:/root/xiedong/tts kevinchina/deeplearning:pytorch-2.4.1-cuda12.1-cudnn9-devel-fish1.4 bash
cd /workspace/fish-speech
数据准备
要创建一个这样的数据集放data里:
bash展开代码. ├── SPK1 │ ├── 21.15-26.44.lab │ ├── 21.15-26.44.mp3 │ ├── 27.51-29.98.lab │ ├── 27.51-29.98.mp3 │ ├── 30.1-32.71.lab │ └── 30.1-32.71.mp3 └── SPK2 ├── 38.79-40.85.lab └── 38.79-40.85.mp3

量提取语义 token
该命令会在 fishdata 目录下创建 .npy 文件。
bash展开代码cd /workspace/fish-speech
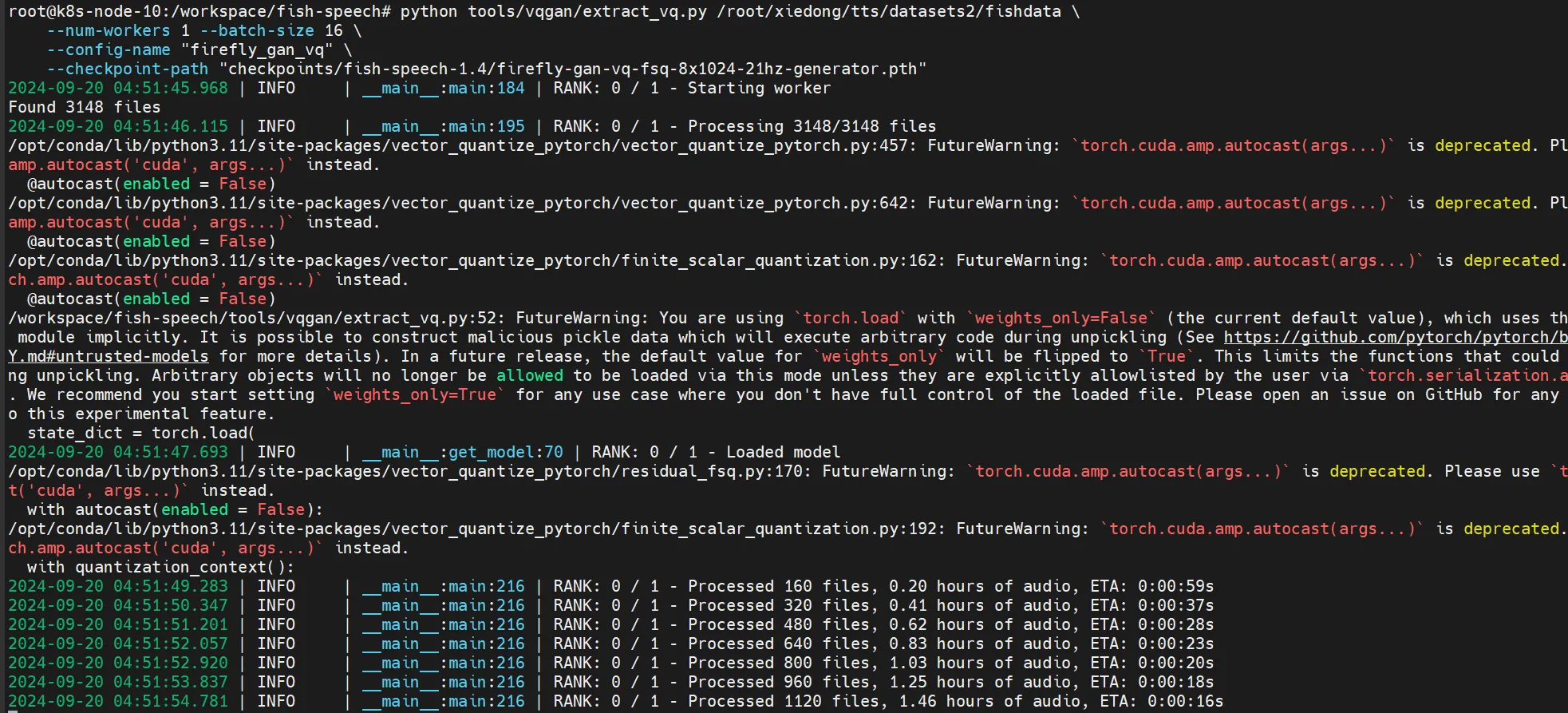
python tools/vqgan/extract_vq.py /root/xiedong/tts/datasets2/fishdata \
--num-workers 1 --batch-size 16 \
--config-name "firefly_gan_vq" \
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
打包数据集为 protobuf
bash展开代码cd /workspace/fish-speech
python tools/llama/build_dataset.py \
--input "/root/xiedong/tts/datasets2/fishdata" \
--output "/root/xiedong/tts/datasets2/fishdata/protos" \
--text-extension .lab \
--num-workers 16

使用 LoRA 进行微调
bash展开代码cd /workspace/fish-speech
vim fish_speech/configs/text2semantic_finetune.yaml # 修改自己的数据路径为/root/xiedong/tts/datasets2/fishdata/protos
export project=shiyu_fish
python fish_speech/train.py --config-name text2semantic_finetune \
project=$project \
+lora@model.model.lora_config=r_8_alpha_16
text2semantic_finetune.yaml是这样的,要根据自己需要改 batch_size, gradient_accumulation_steps,data/protos
bash展开代码# 默认配置列表,首先应用 `base` 配置,然后应用当前文件自身的配置
defaults:
- base
- _self_
# 项目名称,指定为 `text2semantic_finetune_dual_ar`
project: text2semantic_finetune_dual_ar
# 模型的最大输入长度,设置为 4096
max_length: 4096
# 预训练模型的检查点路径,指向 `checkpoints/fish-speech-1.4`
pretrained_ckpt_path: checkpoints/fish-speech-1.4
# Lightning Trainer 配置部分
trainer:
# 累积的梯度批次数,设置为 1
accumulate_grad_batches: 1
# 梯度裁剪的阈值,设置为 1.0
gradient_clip_val: 1.0
# 梯度裁剪的算法,使用 "norm"
gradient_clip_algorithm: "norm"
# 最大训练步数,设置为 1000
max_steps: 1000
# 训练精度,使用 bf16 格式并启用
precision: bf16-true
# 限制验证批次数,设置为 10
limit_val_batches: 10
# 验证检查间隔步数,设置为 100
val_check_interval: 100
# 分词器配置部分
tokenizer:
# 指定分词器的目标类,从预训练模型中加载分词器
_target_: transformers.AutoTokenizer.from_pretrained
# 预训练模型的名称或路径,引用 `pretrained_ckpt_path`
pretrained_model_name_or_path: ${pretrained_ckpt_path}
# 训练数据集配置
train_dataset:
# 指定训练数据集的目标类
_target_: fish_speech.datasets.semantic.AutoTextSemanticInstructionDataset
# 原型文件路径列表
proto_files:
- data/protos
# 使用的分词器,引用 `tokenizer`
tokenizer: ${tokenizer}
# 是否使用因果关系,设置为 true
causal: true
# 最大输入长度,引用 `max_length`
max_length: ${max_length}
# 是否使用说话者信息,设置为 false
use_speaker: false
# 交互概率,设置为 0.7
interactive_prob: 0.7
# 验证数据集配置
val_dataset:
# 指定验证数据集的目标类
_target_: fish_speech.datasets.semantic.AutoTextSemanticInstructionDataset
# 原型文件路径列表
proto_files:
- data/protos
# 使用的分词器,引用 `tokenizer`
tokenizer: ${tokenizer}
# 是否使用因果关系,设置为 true
causal: true
# 最大输入长度,引用 `max_length`
max_length: ${max_length}
# 是否使用说话者信息,设置为 false
use_speaker: false
# 交互概率,设置为 0.7
interactive_prob: 0.7
# 数据模块配置
data:
# 指定数据模块的目标类
_target_: fish_speech.datasets.semantic.SemanticDataModule
# 训练数据集,引用 `train_dataset`
train_dataset: ${train_dataset}
# 验证数据集,引用 `val_dataset`
val_dataset: ${val_dataset}
# 数据加载时使用的工作线程数,设置为 4
num_workers: 4
# 批量大小,设置为 8
batch_size: 8
# 使用的分词器,引用 `tokenizer`
tokenizer: ${tokenizer}
# 最大输入长度,引用 `max_length`
max_length: ${max_length}
# 模型配置部分
model:
# 指定模型的目标类
_target_: fish_speech.models.text2semantic.lit_module.TextToSemantic
model:
# 指定底层模型的目标类,从预训练模型中加载
_target_: fish_speech.models.text2semantic.llama.BaseTransformer.from_pretrained
# 预训练模型的路径,引用 `pretrained_ckpt_path`
path: ${pretrained_ckpt_path}
# 是否加载权重,设置为 true
load_weights: true
# 最大输入长度,引用 `max_length`
max_length: ${max_length}
# LoRA 配置,设置为 null(不使用)
lora_config: null
# 优化器配置
optimizer:
# 指定优化器的目标类,使用 AdamW
_target_: torch.optim.AdamW
# 部分参数化,设置为 true
_partial_: true
# 学习率,设置为 1e-4
lr: 1e-4
# 权重衰减,设置为 0
weight_decay: 0
# Adam 优化器的 beta 参数
betas: [0.9, 0.95]
# Adam 优化器的 epsilon 参数
eps: 1e-5
# 学习率调度器配置
lr_scheduler:
# 指定学习率调度器的目标类,使用 LambdaLR
_target_: torch.optim.lr_scheduler.LambdaLR
# 部分参数化,设置为 true
_partial_: true
# 学习率变化函数
lr_lambda:
# 指定学习率变化函数的目标类
_target_: fish_speech.scheduler.get_constant_schedule_with_warmup_lr_lambda
# 部分参数化,设置为 true
_partial_: true
# 预热步数,设置为 10
num_warmup_steps: 10
# 回调函数配置
callbacks:
# 模型检查点回调配置
model_checkpoint:
# 每隔多少训练步保存一次检查点,引用 `trainer.val_check_interval`
every_n_train_steps: ${trainer.val_check_interval}
使用 LoRA 进行微调的反思
官网说的这个:
默认配置下, 基本只会学到说话人的发音方式, 而不包含音色, 你依然需要使用 prompt 来保证音色的稳定性. 如果你想要学到音色, 请将训练步数调大, 但这有可能会导致过拟合.
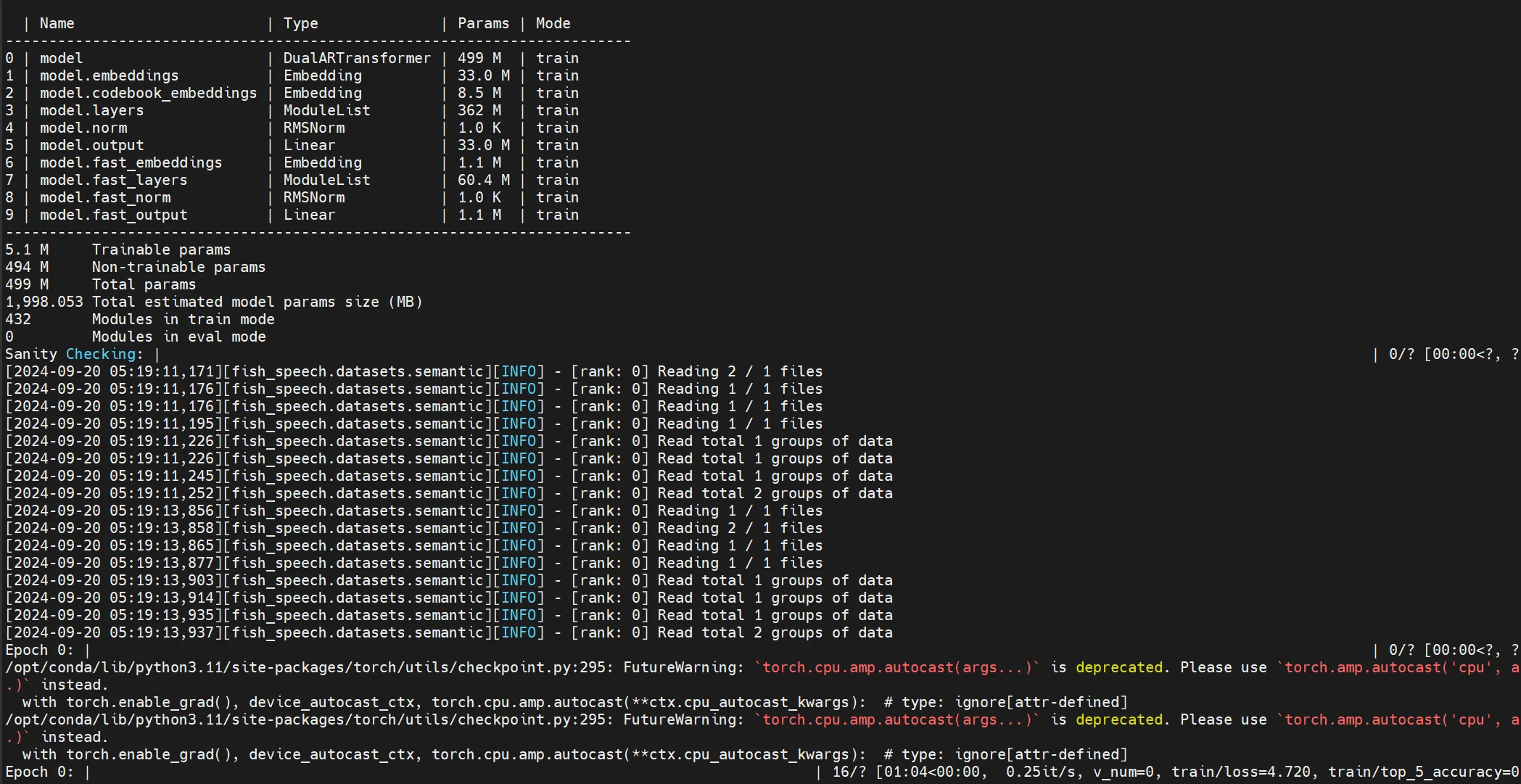
分布式后端为 nccl。模型类型为 DualARTransformer,总参数量为 499M,其中可训练参数为 5.1M,不可训练参数为 494M。Md这和不开源有啥区别???
合并Lora权重进行推理
bash展开代码cd /workspace/fish-speech
export project=shiyu_fish
python tools/llama/merge_lora.py \
--lora-config r_8_alpha_16 \
--base-weight checkpoints/fish-speech-1.4 \
--lora-weight results/$project/checkpoints/step_000000700.ckpt \
--output checkpoints/fish-speech-1.4-yth-lora3/
WebUI 推理
克隆了说话人的音色,效果听起来还是可以。
bash展开代码cd /workspace/fish-speech
export project=shiyu_fish
python -m tools.webui \
--llama-checkpoint-path "checkpoints/fish-speech-1.4-yth-lora3" \
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
--decoder-config-name firefly_gan_vq
HTTP API 推理
开服务:
bash展开代码cd /workspace/fish-speech
python -m tools.api \
--listen 0.0.0.0:8080 \
--llama-checkpoint-path "checkpoints/fish-speech-1.4-yth-lora3" \
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
--decoder-config-name firefly_gan_vq
可以一次使用多个 参考音频路径 和 参考音频的文本内容。在命令里用空格隔开即可。
bash展开代码cd /workspace/fish-speech
conda install pyaudio
python -m tools.post_api \
--text "要输入的文本" \
--reference_audio "参考音频路径1" "参考音频路径2" \
--reference_text "参考音频的文本内容1" "参考音频的文本内容2"\
--streaming False \
--output "generated" \
--format "mp3"
比如,会有很多幻觉读音:
bash展开代码conda install pyaudio
python -m tools.post_api \
--text "要输入的文本" \
--reference_audio "/root/xiedong/tts/datasets2/shiyuv2_vk2/3206.wav.reformatted_vocals.wav_main_vocal.wav" "/root/xiedong/tts/datasets2/shiyuv2_vk2/3209.wav.reformatted_vocals.wav_main_vocal.wav" \
--reference_text "我猛地从沙发上站起来,心跳在胸腔里狂跳,仿佛要跳出喉咙。" "你怎么可以这么不小心我几乎是咆哮着说出这句话,声音里满是失望和愤怒。" \
--output "generated" \
--format "wav" --play False
总结
有太多幻觉,不玩了,没啥用。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!