【深度学习】使用ms-swift微调训练Qwen2-VL做印章识别
资料文件:
https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct/discussions/2
https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct/discussions/1
swift.readthedocs.io/zh-cn/latest/Multi-Modal/qwen2-vl最佳实践
环境准备
bash展开代码docker pull pytorch/pytorch:2.4.1-cuda12.1-cudnn9-devel
docker run -it --net host --gpus all -v /root/xiedong:/xiedong pytorch/pytorch:2.4.1-cuda12.1-cudnn9-devel bash
apt update && apt install git wget vim -y
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[all]
# 请关注这个ISSUE: https://github.com/QwenLM/Qwen2-VL/issues/12
# pip install torch>=2.4
pip install git+https://github.com/huggingface/transformers.git
pip install pyav qwen_vl_utils
# 如果你想要使用deepspeed.
pip install deepspeed -U
# 如果你想要使用基于auto_gptq的qlora训练. (推荐, 效果优于bnb)
# 支持auto_gptq的模型: `https://github.com/modelscope/swift/blob/main/docs/source/Instruction/支持的模型和数据集.md#模型`
# auto_gptq和cuda版本有对应关系,请按照`https://github.com/PanQiWei/AutoGPTQ#quick-installation`选择版本
pip install auto_gptq -U
# 如果你想要使用基于bnb的qlora训练.
pip install bitsandbytes -U
用这个镜像:kevinchina/deeplearning:ms-swift-train-qwen2vl
推理qwen2-vl-7b-instruct:
bash展开代码# Experimental environment: A100
# 16GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type qwen2-vl-7b-instruct --model_id_or_path /xiedong/Qwen2-VL-7B-Instruct --dtype bf16
每个问题都占用着显存,问两个问题后显存从16G来到27G:
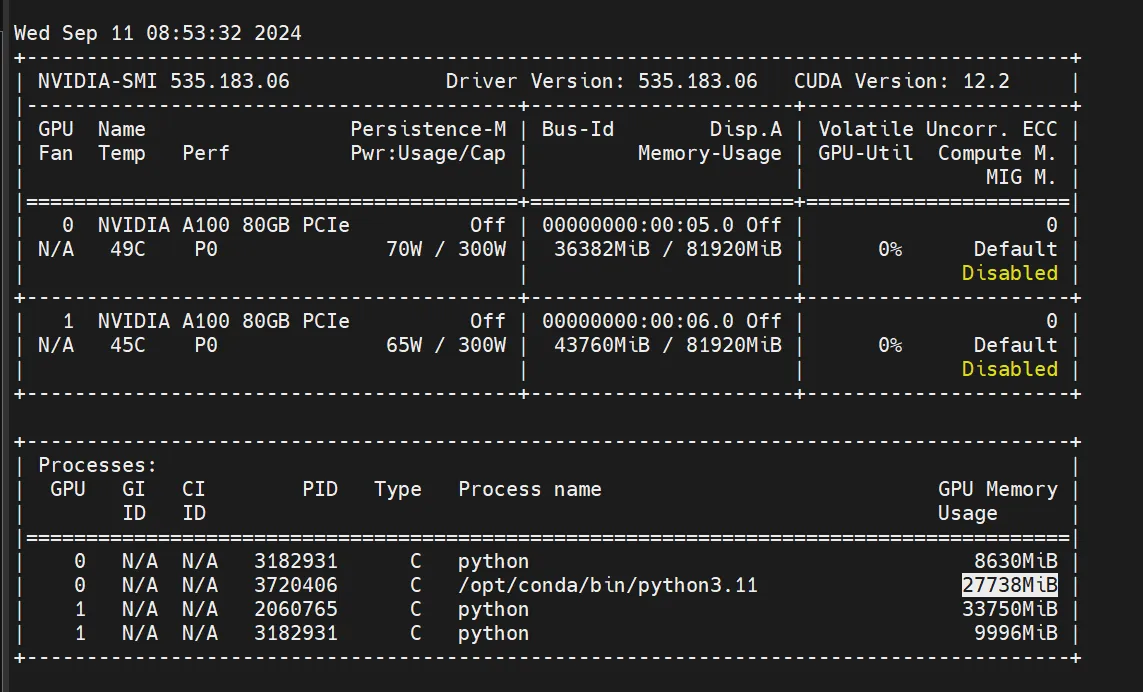
bash展开代码<<< <image><image>这两张图片有什么区别
Input an image path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
Input an image path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
[INFO:swift] Setting size_factor: 28. You can adjust this hyperparameter through the environment variable: `SIZE_FACTOR`.
[INFO:swift] Setting resized_height: None. You can adjust this hyperparameter through the environment variable: `RESIZED_HEIGHT`.
[INFO:swift] Setting resized_width: None. You can adjust this hyperparameter through the environment variable: `RESIZED_WIDTH`.
[INFO:swift] Setting min_pixels: 3136. You can adjust this hyperparameter through the environment variable: `MIN_PIXELS`.
[INFO:swift] Setting max_pixels: 12845056. You can adjust this hyperparameter through the environment variable: `MAX_PIXELS`.
这两个图片的区别在于它们的主题和内容。
1. **第一张图片**:这是一只小猫的特写照片。小猫有着黑白相间的毛发,大大的眼睛和长长的胡须,看起来非常可爱和迷人。
2. **第二张图片**:这是一幅卡通风格的插画,描绘了一群羊在草地上。背景是绿色的草地和远处的山脉,整体画面充满了温馨和自然的气息。
总结来说,第一张图片是一只可爱的小猫的特写,而第二张图片是一群卡通羊的插画。
--------------------------------------------------
<<< <image>对图片进行OCR
Input an image path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/ocr.png
以下是图片中的文本内容:
简介
SWIFT支持250+ LLM和35+ MLLM(多模态大模型)的训练、推理、评测和部署。开发者可以直接将我们的框架应用到自己的Research和生产环境中,实现模型训练评测到应用的完整链路。我们除支持了PEFT提供的轻量训练方案外,也提供了一个完整的Adapters库以支持最新的训练技术,如NEFTune、LoRA+、LLaMA-PRO等,这个适配器库可以脱离训练脚本直接使用在自己的自定流程中。
为方便不熟悉深度学习的用户使用,我们提供了一个Gradio的web-ui用于控制训练和推理,并提供了配套的深度学习课程和最佳实践供新手入门。
此外,我们也在拓展其他模态的能力,目前我们支持了AnimateDiff的全参数训练和LoRA训练。
SWIFT具有丰富的文档体系,如有使用问题请查看这里.
可以在Huggingface space 和 ModelScope创空间 中体验SWIFT web-ui功能了。
--------------------------------------------------
<<< clear
<<< 你是谁
我是来自阿里云的大规模语言模型,我叫通义千问。
--------------------------------------------------
clear 无法清除显存占用。
微调 图像OCR微调
bash展开代码# 单卡A10/3090可运行
# GPU Memory: 20GB
SIZE_FACTOR=8 MAX_PIXELS=602112 CUDA_VISIBLE_DEVICES=0,1 NPROC_PER_NODE=2 swift sft \
--model_type qwen2-vl-7b-instruct \
--model_id_or_path /xiedong/Qwen2-VL-7B-Instruct \
--sft_type lora \
--dataset latex-ocr-print#20000
# 全参数训练并freeze vit
# GPU Memory: 4 * 60GB
CUDA_VISIBLE_DEVICES=0,1 NPROC_PER_NODE=2 swift sft \
--model_type qwen2-vl-7b-instruct \
--model_id_or_path /xiedong/Qwen2-VL-7B-Instruct \
--sft_type full \
--freeze_vit true \
--deepspeed default-zero2 \
--dataset latex-ocr-print#20000
# 更少的显存消耗: QLoRA
# GPU Memory: 10GB
SIZE_FACTOR=8 MAX_PIXELS=602112 CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type qwen2-vl-7b-instruct-gptq-int4 \
--model_id_or_path qwen/Qwen2-VL-7B-Instruct-GPTQ-Int4 \
--sft_type lora \
--dataset latex-ocr-print#20000
开webui:
bash展开代码WEBUI_SERVER='0.0.0.0' swift web-ui
bash展开代码web-ui可以通过环境变量或者参数控制UI行为。环境变量如下: WEBUI_SHARE=1/0 默认为0 控制gradio是否是share状态 SWIFT_UI_LANG=en/zh 控制web-ui界面语言 WEBUI_SERVER server_name参数,web-ui host ip,0.0.0.0代表所有ip均可访问,127.0.0.1代表只允许本机访问 WEBUI_PORT web-ui的端口号 USE_INFERENCE=1/0 默认0. 控制gradio的推理页面是直接加载模型推理或者部署(USE_INFERENCE=0)
训练指令:
bash展开代码CUDA_VISIBLE_DEVICES=0,1 NPROC_PER_NODE=2 nohup swift sft --model_id_or_path '/xiedong/Qwen2-VL-7B-Instruct' --template_type 'qwen2-vl' --system 'You are a helpful assistant.' --dataset alpaca-zh --lora_target_modules ALL --lora_rank '32' --lora_alpha '64' --init_lora_weights 'True' --learning_rate '1e-4' --use_flash_attn 'True' --gradient_accumulation_steps '16' --eval_steps '500' --save_steps '500' --eval_batch_size '1' --model_type 'qwen2-7b-instruct' --add_output_dir_suffix False --output_dir /workspace/output/qwen2-7b-instruct/v2-20240911-013530 --logging_dir /workspace/output/qwen2-7b-instruct/v2-20240911-013530/runs --ignore_args_error True > /workspace/output/qwen2-7b-instruct/v2-20240911-013530/runs/run.log 2>&1 &
如果要使用自定义数据集,只需按以下方式进行指定:
bash展开代码--dataset train.jsonl \ --val_dataset val.jsonl \
自定义数据集支持json和jsonl(就是一行一个json字符串)样式,以下是自定义数据集的样例:
bash展开代码{"query": "<image>识别印章上的公司名字", "response": "咖啡壶有限公司", "images": ["image_path"]}
{"query": "eeeee<image>eeeee<image>eeeee", "response": "fffff", "history": [], "images": ["image_path1", "image_path2"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response2"], ["query2", "response2"]], "images": []}
制作了一个印章数据集:
python展开代码import os
import json
# Set the root directory for the images and text files
root_dir = "/root/xiedong/yinzhang/save_dst"
# The output JSONL file path
output_file = "output.jsonl"
# Create a function to generate the JSONL data
def generate_jsonl():
# Open the output file for writing
with open(output_file, 'w', encoding='utf-8') as jsonl_file:
# Iterate over all the files in the root directory
for filename in os.listdir(root_dir):
# Check if the file is a jpg image
if filename.endswith(".jpg"):
# Build the full path to the image file
image_path = os.path.join(root_dir, filename)
# Build the full path to the corresponding txt file
txt_filename = filename.replace(".jpg", ".txt")
txt_path = os.path.join(root_dir, txt_filename)
# Read the content of the txt file if it exists
if os.path.exists(txt_path):
with open(txt_path, 'r', encoding='utf-8') as txt_file:
label = txt_file.readline().strip()
else:
label = ""
print(f"Warning: No text file found for {filename}")
# Create a dictionary with the required structure
jsonl_entry = {
"query": "<image>识别图片里红色印章上的公司名称或单位名称(印章主文字)。",
"response": json.dumps({"印章主文字": label}, ensure_ascii=False),
"images": [str(image_path).replace("/root", "")]
}
# Write the dictionary as a JSON string to the JSONL file
jsonl_file.write(json.dumps(jsonl_entry, ensure_ascii=False) + '\n')
print(f"JSONL file has been created: {output_file}")
# Call the function to generate the JSONL file
generate_jsonl()
jsonl的内容:
bash展开代码 Wed Sep 11 # 13:43:43 # /root/xiedong/yinzhang # ll
total 46456
drwxr-xr-x 3 root root 4096 Sep 11 13:42 ./
drwxr-xr-x 10 root root 4096 Sep 10 18:05 ../
-rw-r--r-- 1 root root 11555925 Sep 11 13:43 output.jsonl
-rw-r--r-- 1 root root 14685740 Sep 10 18:07 platech.ttf
drwxr-xr-x 2 root root 2928640 Sep 11 12:28 save_dst/
-rw-r--r-- 1 root root 18214472 Sep 10 18:07 simsun.ttc
-rw-r--r-- 1 root root 138376 Sep 10 18:05 x04_filtered.txt
-rw-r--r-- 1 root root 11131 Sep 10 18:05 x04_gongsixingzhi.txt
-rw-r--r-- 1 root root 14900 Sep 11 12:00 x06_muti_proces.py
-rw-r--r-- 1 root root 1972 Sep 11 13:43 x06jsonl.py
Wed Sep 11 # 13:44:18 # /root/xiedong/yinzhang # head output.jsonl
{"query": "<image>识别图片里红色印章上的公司名称或单位名称(印章主文字)。", "response": "{\"印章主文字\": \"饮酒太原近似收益有限公司\"}", "images": ["/xiedong/yinzhang/save_dst/010155.jpg"]}
{"query": "<image>识别图片里红色印章上的公司名称或单位名称(印章主文字)。", "response": "{\"印章主文字\": \"薏烦日内瓦有限责任公司\"}", "images": ["/xiedong/yinzhang/save_dst/020540.jpg"]}
训练,打开容器:
bash展开代码docker run -it --net host --gpus all -v /root/xiedong:/xiedong kevinchina/deeplearning:ms-swift-train-qwen2vl bash
训练指令:
bash展开代码SIZE_FACTOR=8 MAX_PIXELS=602112 CUDA_VISIBLE_DEVICES=0,1 NPROC_PER_NODE=2 swift sft --model_id_or_path '/xiedong/Qwen2-VL-7B-Instruct' --system '你是一个有用的助手,可以按图片类型提取信息,输出json字符串.' --dataset '/xiedong/yinzhang/output.jsonl' --lora_target_modules ALL --lora_rank '32' --lora_alpha '64' --init_lora_weights 'True' --learning_rate '1e-4' --use_flash_attn 'True' --gradient_accumulation_steps '16' --eval_steps '500' --save_steps '500' --eval_batch_size '1' --model_type 'qwen2-7b-instruct' --add_output_dir_suffix False --output_dir /workspace/output/qwen2-7b-instruct/v2trainseal --logging_dir /workspace/output/qwen2-7b-instruct/v2trainseal/runs --ignore_args_error True --deepspeed default-zero2 --template_type 'qwen2-vl'
下面是噶了的日志。我去隔壁用LLaMA-Factory了。
bash展开代码[INFO:swift] Successfully registered `/workspace/swift/swift/llm/data/dataset_info.json`
[INFO:swift] No vLLM installed, if you are using vLLM, you will get `ImportError: cannot import name 'get_vllm_engine' from 'swift.llm'`
[INFO:swift] No LMDeploy installed, if you are using LMDeploy, you will get `ImportError: cannot import name 'prepare_lmdeploy_engine_template' from 'swift.llm'`
[INFO:swift] Start time of running main: 2024-09-11 06:12:27.791574
[INFO:swift] Using deepspeed: {'fp16': {'enabled': 'auto', 'loss_scale': 0, 'loss_scale_window': 1000, 'initial_scale_power': 16, 'hysteresis': 2, 'min_loss_scale': 1}, 'bf16': {'enabled': 'auto'}, 'optimizer': {'type': 'AdamW', 'params': {'lr': 'auto', 'betas': 'auto', 'eps': 'auto', 'weight_decay': 'auto'}}, 'scheduler': {'type': 'WarmupCosineLR', 'params': {'total_num_steps': 'auto', 'warmup_num_steps': 'auto'}}, 'zero_optimization': {'stage': 2, 'offload_optimizer': {'device': 'none', 'pin_memory': True}, 'allgather_partitions': True, 'allgather_bucket_size': 200000000.0, 'overlap_comm': True, 'reduce_scatter': True, 'reduce_bucket_size': 200000000.0, 'contiguous_gradients': True}, 'gradient_accumulation_steps': 'auto', 'gradient_clipping': 'auto', 'steps_per_print': 2000, 'train_batch_size': 'auto', 'train_micro_batch_size_per_gpu': 'auto', 'wall_clock_breakdown': False}
[INFO:swift] Setting args.lazy_tokenize: True
[INFO:swift] Setting args.dataloader_num_workers: 1
[2024-09-11 06:12:27,838] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-09-11 06:12:27,862] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-09-11 06:12:28,868] [INFO] [comm.py:652:init_distributed] cdb=None
device_count: 2
rank: 1, local_rank: 1, world_size: 2, local_world_size: 2
[2024-09-11 06:12:28,952] [INFO] [comm.py:652:init_distributed] cdb=None
[2024-09-11 06:12:28,952] [INFO] [comm.py:683:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
[INFO:swift] args: SftArguments(model_type='qwen2-7b-instruct', model_id_or_path='/xiedong/Qwen2-VL-7B-Instruct', model_revision='master', full_determinism=False, sft_type='lora', freeze_parameters=[], freeze_vit=False, freeze_parameters_ratio=0.0, additional_trainable_parameters=[], tuner_backend='peft', template_type='qwen2-vl', output_dir='/workspace/output/qwen2-7b-instruct/v2trainseal', add_output_dir_suffix=False, ddp_backend='nccl', ddp_find_unused_parameters=None, ddp_broadcast_buffers=None, ddp_timeout=1800, seed=42, resume_from_checkpoint=None, resume_only_model=False, ignore_data_skip=False, dtype='bf16', packing=False, train_backend='transformers', tp=1, pp=1, min_lr=None, sequence_parallel=False, model_kwargs=None, loss_name=None, dataset=['/xiedong/yinzhang/output.jsonl'], val_dataset=[], dataset_seed=42, dataset_test_ratio=0.01, use_loss_scale=False, loss_scale_config_path='/workspace/swift/swift/llm/agent/default_loss_scale_config.json', system='你是一个有用的助手,可以按图片类型提取信息,输出json字符串.', tools_prompt='react_en', max_length=2048, truncation_strategy='delete', check_dataset_strategy='none', streaming=False, streaming_val_size=0, streaming_buffer_size=16384, model_name=[None, None], model_author=[None, None], quant_method=None, quantization_bit=0, hqq_axis=0, hqq_dynamic_config_path=None, bnb_4bit_comp_dtype='bf16', bnb_4bit_quant_type='nf4', bnb_4bit_use_double_quant=True, bnb_4bit_quant_storage=None, rescale_image=-1, target_modules=['ALL'], target_regex=None, modules_to_save=[], lora_rank=32, lora_alpha=64, lora_dropout=0.05, lora_bias_trainable='none', lora_dtype='AUTO', lora_lr_ratio=None, use_rslora=False, use_dora=False, init_lora_weights='True', fourier_n_frequency=2000, fourier_scaling=300.0, rope_scaling=None, boft_block_size=4, boft_block_num=0, boft_n_butterfly_factor=1, boft_dropout=0.0, vera_rank=256, vera_projection_prng_key=0, vera_dropout=0.0, vera_d_initial=0.1, adapter_act='gelu', adapter_length=128, use_galore=False, galore_target_modules=None, galore_rank=128, galore_update_proj_gap=50, galore_scale=1.0, galore_proj_type='std', galore_optim_per_parameter=False, galore_with_embedding=False, galore_quantization=False, galore_proj_quant=False, galore_proj_bits=4, galore_proj_group_size=256, galore_cos_threshold=0.4, galore_gamma_proj=2, galore_queue_size=5, adalora_target_r=8, adalora_init_r=12, adalora_tinit=0, adalora_tfinal=0, adalora_deltaT=1, adalora_beta1=0.85, adalora_beta2=0.85, adalora_orth_reg_weight=0.5, ia3_feedforward_modules=[], llamapro_num_new_blocks=4, llamapro_num_groups=None, neftune_noise_alpha=None, neftune_backend='transformers', lisa_activated_layers=0, lisa_step_interval=20, reft_layer_key=None, reft_layers=None, reft_rank=4, reft_intervention_type='LoreftIntervention', reft_args=None, use_liger=False, gradient_checkpointing=True, deepspeed={'fp16': {'enabled': 'auto', 'loss_scale': 0, 'loss_scale_window': 1000, 'initial_scale_power': 16, 'hysteresis': 2, 'min_loss_scale': 1}, 'bf16': {'enabled': 'auto'}, 'optimizer': {'type': 'AdamW', 'params': {'lr': 'auto', 'betas': 'auto', 'eps': 'auto', 'weight_decay': 'auto'}}, 'scheduler': {'type': 'WarmupCosineLR', 'params': {'total_num_steps': 'auto', 'warmup_num_steps': 'auto'}}, 'zero_optimization': {'stage': 2, 'offload_optimizer': {'device': 'none', 'pin_memory': True}, 'allgather_partitions': True, 'allgather_bucket_size': 200000000.0, 'overlap_comm': True, 'reduce_scatter': True, 'reduce_bucket_size': 200000000.0, 'contiguous_gradients': True}, 'gradient_accumulation_steps': 'auto', 'gradient_clipping': 'auto', 'steps_per_print': 2000, 'train_batch_size': 'auto', 'train_micro_batch_size_per_gpu': 'auto', 'wall_clock_breakdown': False}, batch_size=1, eval_batch_size=1, auto_find_batch_size=False, num_train_epochs=1, max_steps=-1, optim='adamw_torch', adam_beta1=0.9, adam_beta2=0.95, adam_epsilon=1e-08, learning_rate=0.0001, weight_decay=0.1, gradient_accumulation_steps=16, max_grad_norm=1, predict_with_generate=False, lr_scheduler_type='cosine', lr_scheduler_kwargs={}, warmup_ratio=0.05, warmup_steps=0, eval_steps=500, save_steps=500, save_only_model=False, save_total_limit=2, logging_steps=5, acc_steps=1, dataloader_num_workers=1, dataloader_pin_memory=True, dataloader_drop_last=False, push_to_hub=False, hub_model_id=None, hub_token=None, hub_private_repo=False, hub_strategy='every_save', test_oom_error=False, disable_tqdm=False, lazy_tokenize=True, preprocess_num_proc=1, use_flash_attn=True, ignore_args_error=True, check_model_is_latest=True, logging_dir='/workspace/output/qwen2-7b-instruct/v2trainseal/runs', report_to=['tensorboard'], acc_strategy='token', save_on_each_node=False, evaluation_strategy='steps', save_strategy='steps', save_safetensors=True, gpu_memory_fraction=None, include_num_input_tokens_seen=False, local_repo_path=None, custom_register_path=None, custom_dataset_info=None, device_map_config=None, device_max_memory=[], max_new_tokens=2048, do_sample=None, temperature=None, top_k=None, top_p=None, repetition_penalty=None, num_beams=1, fsdp='', fsdp_config=None, sequence_parallel_size=1, model_layer_cls_name=None, metric_warmup_step=0, fsdp_num=1, per_device_train_batch_size=None, per_device_eval_batch_size=None, eval_strategy=None, self_cognition_sample=0, train_dataset_mix_ratio=0.0, train_dataset_mix_ds=['ms-bench'], train_dataset_sample=-1, val_dataset_sample=None, safe_serialization=None, only_save_model=None, neftune_alpha=None, deepspeed_config_path=None, model_cache_dir=None, lora_dropout_p=None, lora_target_modules=['ALL'], lora_target_regex=None, lora_modules_to_save=[], boft_target_modules=[], boft_modules_to_save=[], vera_target_modules=[], vera_modules_to_save=[], ia3_target_modules=[], ia3_modules_to_save=[], custom_train_dataset_path=[], custom_val_dataset_path=[], device_map_config_path=None, push_hub_strategy=None)
[INFO:swift] Global seed set to 42
device_count: 2
rank: 0, local_rank: 0, world_size: 2, local_world_size: 2
[INFO:swift] Loading the model using model_dir: /xiedong/Qwen2-VL-7B-Instruct
Unrecognized keys in `rope_scaling` for 'rope_type'='default': {'mrope_section'}
Unrecognized keys in `rope_scaling` for 'rope_type'='default': {'mrope_section'}
[INFO:swift] model_kwargs: {'low_cpu_mem_usage': True, 'device_map': {'': 0}}
[rank1]: Traceback (most recent call last):
[rank1]: File "/workspace/swift/swift/cli/sft.py", line 5, in <module>
[rank1]: sft_main()
[rank1]: File "/workspace/swift/swift/utils/run_utils.py", line 32, in x_main
[rank1]: result = llm_x(args, **kwargs)
[rank1]: ^^^^^^^^^^^^^^^^^^^^^
[rank1]: File "/workspace/swift/swift/llm/sft.py", line 211, in llm_sft
[rank1]: model, tokenizer = get_model_tokenizer(
[rank1]: ^^^^^^^^^^^^^^^^^^^^
[rank1]: File "/workspace/swift/swift/llm/utils/model.py", line 6620, in get_model_tokenizer
[rank1]: model, tokenizer = get_function(model_dir, torch_dtype, model_kwargs, load_model, **kwargs)
[rank1]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank1]: File "/workspace/swift/swift/llm/utils/model.py", line 3521, in get_model_tokenizer_qwen2_chat
[rank1]: return get_model_tokenizer_with_flash_attn(model_dir, torch_dtype, model_kwargs, load_model, **kwargs)
[rank1]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank1]: File "/workspace/swift/swift/llm/utils/model.py", line 2628, in get_model_tokenizer_with_flash_attn
[rank1]: return get_model_tokenizer_from_repo(
[rank1]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank1]: File "/workspace/swift/swift/llm/utils/model.py", line 942, in get_model_tokenizer_from_repo
[rank1]: model = automodel_class.from_pretrained(
[rank1]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank1]: File "/opt/conda/lib/python3.11/site-packages/modelscope/utils/hf_util.py", line 65, in from_pretrained
[rank1]: module_obj = module_class.from_pretrained(model_dir, *model_args,
[rank1]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank1]: File "/opt/conda/lib/python3.11/site-packages/transformers/models/auto/auto_factory.py", line 560, in from_pretrained
[rank1]: raise ValueError(
[rank1]: ValueError: Unrecognized configuration class <class 'transformers.models.qwen2_vl.configuration_qwen2_vl.Qwen2VLConfig'> for this kind of AutoModel: AutoModelForCausalLM.
[rank1]: Model type should be one of BartConfig, BertConfig, BertGenerationConfig, BigBirdConfig, BigBirdPegasusConfig, BioGptConfig, BlenderbotConfig, BlenderbotSmallConfig, BloomConfig, CamembertConfig, LlamaConfig, CodeGenConfig, CohereConfig, CpmAntConfig, CTRLConfig, Data2VecTextConfig, DbrxConfig, ElectraConfig, ErnieConfig, FalconConfig, FalconMambaConfig, FuyuConfig, GemmaConfig, Gemma2Config, GitConfig, GPT2Config, GPT2Config, GPTBigCodeConfig, GPTNeoConfig, GPTNeoXConfig, GPTNeoXJapaneseConfig, GPTJConfig, GraniteConfig, JambaConfig, JetMoeConfig, LlamaConfig, MambaConfig, Mamba2Config, MarianConfig, MBartConfig, MegaConfig, MegatronBertConfig, MistralConfig, MixtralConfig, MptConfig, MusicgenConfig, MusicgenMelodyConfig, MvpConfig, NemotronConfig, OlmoConfig, OlmoeConfig, OpenLlamaConfig, OpenAIGPTConfig, OPTConfig, PegasusConfig, PersimmonConfig, PhiConfig, Phi3Config, PLBartConfig, ProphetNetConfig, QDQBertConfig, Qwen2Config, Qwen2MoeConfig, RecurrentGemmaConfig, ReformerConfig, RemBertConfig, RobertaConfig, RobertaPreLayerNormConfig, RoCBertConfig, RoFormerConfig, RwkvConfig, Speech2Text2Config, StableLmConfig, Starcoder2Config, TransfoXLConfig, TrOCRConfig, WhisperConfig, XGLMConfig, XLMConfig, XLMProphetNetConfig, XLMRobertaConfig, XLMRobertaXLConfig, XLNetConfig, XmodConfig.
[rank0]: Traceback (most recent call last):
[rank0]: File "/workspace/swift/swift/cli/sft.py", line 5, in <module>
[rank0]: sft_main()
[rank0]: File "/workspace/swift/swift/utils/run_utils.py", line 32, in x_main
[rank0]: result = llm_x(args, **kwargs)
[rank0]: ^^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/workspace/swift/swift/llm/sft.py", line 211, in llm_sft
[rank0]: model, tokenizer = get_model_tokenizer(
[rank0]: ^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/workspace/swift/swift/llm/utils/model.py", line 6620, in get_model_tokenizer
[rank0]: model, tokenizer = get_function(model_dir, torch_dtype, model_kwargs, load_model, **kwargs)
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/workspace/swift/swift/llm/utils/model.py", line 3521, in get_model_tokenizer_qwen2_chat
[rank0]: return get_model_tokenizer_with_flash_attn(model_dir, torch_dtype, model_kwargs, load_model, **kwargs)
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/workspace/swift/swift/llm/utils/model.py", line 2628, in get_model_tokenizer_with_flash_attn
[rank0]: return get_model_tokenizer_from_repo(
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/workspace/swift/swift/llm/utils/model.py", line 942, in get_model_tokenizer_from_repo
[rank0]: model = automodel_class.from_pretrained(
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/opt/conda/lib/python3.11/site-packages/modelscope/utils/hf_util.py", line 65, in from_pretrained
[rank0]: module_obj = module_class.from_pretrained(model_dir, *model_args,
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: File "/opt/conda/lib/python3.11/site-packages/transformers/models/auto/auto_factory.py", line 560, in from_pretrained
[rank0]: raise ValueError(
[rank0]: ValueError: Unrecognized configuration class <class 'transformers.models.qwen2_vl.configuration_qwen2_vl.Qwen2VLConfig'> for this kind of AutoModel: AutoModelForCausalLM.
[rank0]: Model type should be one of BartConfig, BertConfig, BertGenerationConfig, BigBirdConfig, BigBirdPegasusConfig, BioGptConfig, BlenderbotConfig, BlenderbotSmallConfig, BloomConfig, CamembertConfig, LlamaConfig, CodeGenConfig, CohereConfig, CpmAntConfig, CTRLConfig, Data2VecTextConfig, DbrxConfig, ElectraConfig, ErnieConfig, FalconConfig, FalconMambaConfig, FuyuConfig, GemmaConfig, Gemma2Config, GitConfig, GPT2Config, GPT2Config, GPTBigCodeConfig, GPTNeoConfig, GPTNeoXConfig, GPTNeoXJapaneseConfig, GPTJConfig, GraniteConfig, JambaConfig, JetMoeConfig, LlamaConfig, MambaConfig, Mamba2Config, MarianConfig, MBartConfig, MegaConfig, MegatronBertConfig, MistralConfig, MixtralConfig, MptConfig, MusicgenConfig, MusicgenMelodyConfig, MvpConfig, NemotronConfig, OlmoConfig, OlmoeConfig, OpenLlamaConfig, OpenAIGPTConfig, OPTConfig, PegasusConfig, PersimmonConfig, PhiConfig, Phi3Config, PLBartConfig, ProphetNetConfig, QDQBertConfig, Qwen2Config, Qwen2MoeConfig, RecurrentGemmaConfig, ReformerConfig, RemBertConfig, RobertaConfig, RobertaPreLayerNormConfig, RoCBertConfig, RoFormerConfig, RwkvConfig, Speech2Text2Config, StableLmConfig, Starcoder2Config, TransfoXLConfig, TrOCRConfig, WhisperConfig, XGLMConfig, XLMConfig, XLMProphetNetConfig, XLMRobertaConfig, XLMRobertaXLConfig, XLNetConfig, XmodConfig.
W0911 06:12:30.963000 140338065270592 torch/distributed/elastic/multiprocessing/api.py:858] Sending process 611 closing signal SIGTERM
E0911 06:12:31.128000 140338065270592 torch/distributed/elastic/multiprocessing/api.py:833] failed (exitcode: 1) local_rank: 1 (pid: 612) of binary: /opt/conda/bin/python3.11
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "/opt/conda/lib/python3.11/site-packages/torch/distributed/run.py", line 905, in <module>
main()
File "/opt/conda/lib/python3.11/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 348, in wrapper
return f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/torch/distributed/run.py", line 901, in main
run(args)
File "/opt/conda/lib/python3.11/site-packages/torch/distributed/run.py", line 892, in run
elastic_launch(
File "/opt/conda/lib/python3.11/site-packages/torch/distributed/launcher/api.py", line 133, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/torch/distributed/launcher/api.py", line 264, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
/workspace/swift/swift/cli/sft.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2024-09-11_06:12:30
host : k8s-node-101.136.22.140
rank : 1 (local_rank: 1)
exitcode : 1 (pid: 612)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!