FakeLocation 可以辅助Android的一些便捷开发,但有时候打开后就有强制更新弹窗,很烦人。
看b站教程,可以用magisk+lsposed 里阻止弹窗,我以小米6测试一下如何使用。
LSPosed 安装教程的总纲是这样: https://github.com/LSPosed/LSPosed/wiki/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8
如何评估大语言模型(LLM)性能
训练了一个大型语言模型(LLM)后,接下来的关键问题就是如何评估模型的好坏。评估LLM的性能不仅涉及到对模型的语言生成能力的测量,还包括对其通用性、鲁棒性和适应性等多个维度的考察。
本文将从以下几个方面探讨评估LLM的常用方法,并介绍各种评估指标与实践技巧。
探索大模型训练中的关键标签:system、user、role、content、assistant、observation、function
在大语言模型(如 GPT-4、GPT-5)的训练和使用过程中,标签(tags)起到了至关重要的作用。通过这些标签,模型能够理解并处理不同类型的信息,准确识别对话的角色、内容、功能调用以及外部工具交互。这些标签帮助模型保持对话的上下文连贯性,执行复杂任务并生成高质量的响应。在这篇博客中,我们将深入探讨七个重要的标签:system、user、role、content、assistant、observation 和 function,并探讨它们在大模型训练中的作用和重要性。
PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习算法,由OpenAI于2017年提出,主要用于解决强化学习中策略更新时的不稳定性问题。PPO是深度强化学习领域中非常流行的一种策略优化方法,因其高效性和稳定性,广泛应用于许多复杂任务中,如机器人控制、视频游戏AI和自然语言处理等。
背景与问题
在强化学习中,智能体(agent)通过与环境交互,学习一个策略(policy),以便最大化累积奖励。经典的强化学习方法如策略梯度(Policy Gradient)和Q学习(Q-Learning)在策略更新时会遇到一些问题:
- 策略更新过大:当策略在更新时,如果变化过大,可能会导致策略的性能急剧下降,甚至偏离最优解。这种不稳定性使得算法在许多复杂环境下表现不佳。
- 样本效率低:在高维度环境中,传统的强化学习方法往往需要大量的样本才能找到较好的策略,样本效率较低。
计算随机取汉字的概率与期望次数
在一个包含2万个汉字的集合中,如果我们每次随机取一个汉字,想要取到全部汉字的概率是多少?又需要取多少次,才能期望取到所有汉字?这些问题可以借助概率论中的“优惠券收集问题(Coupon Collector's Problem)”来解答。
这里有个收费的印章制作:https://tools.kalvinbg.cn/convenience/seal
这里有个java的印章制作:https://github.com/xxddccaa/SealUtil
这里还有一个别人的印章数据集:https://drive.usercontent.google.com/download?id=125SgEmHFUIzDexsrj2d3yMJdYMVhovti&export=download&authuser=0
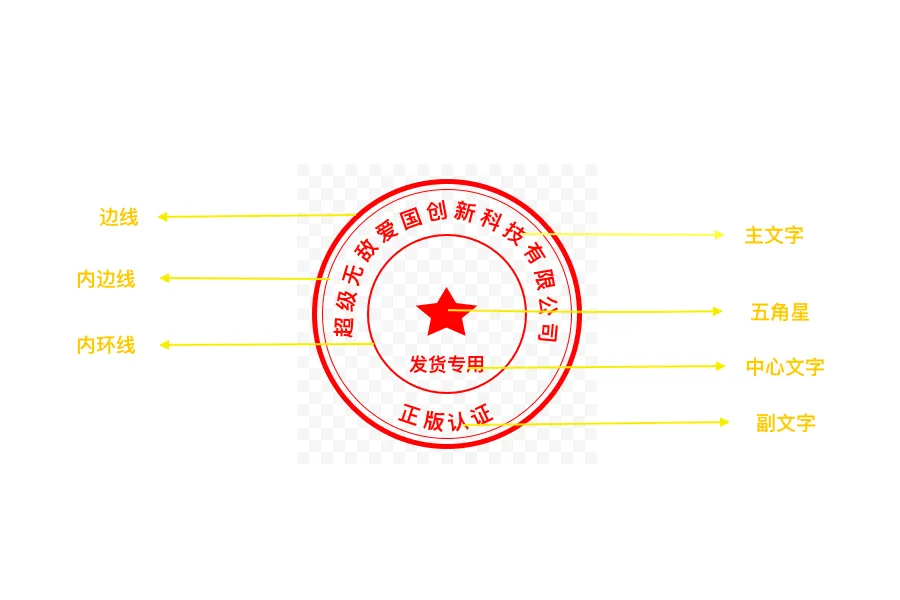
本篇文章也用java制作一下印章数据集,可以应用于印章检测和印章识别。
使用 tar 命令在 Linux 中压缩文件:实际案例分享
在 Linux 系统中,tar 是一个非常常用的命令,用来打包和压缩文件。最近,我和一位朋友讨论了如何将一个目录压缩为 .tar 文件,过程中分享了一个非常简洁的命令。这篇博客就是为了记录下这次有趣的对话和技巧,帮助大家更好地理解 tar 的使用。
