目录
官网教程
https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e/xyyqrfwiu3e2bgyk
https://github.com/RVC-Boss/GPT-SoVITS
GPT-SoVITS原理


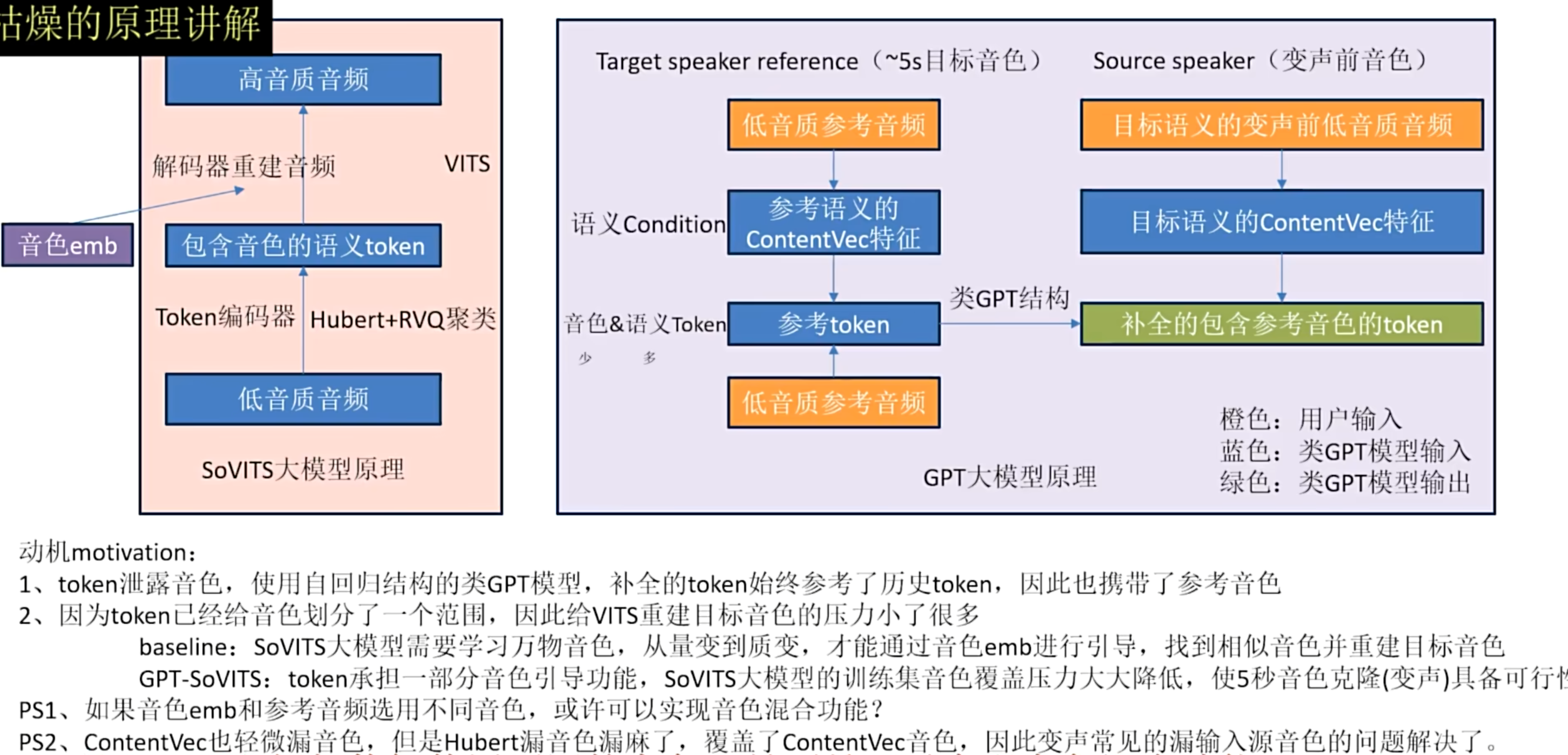
制作镜像
不用docker不行,不好分配显卡,
做个docker镜像:
bash展开代码docker pull pytorch/pytorch:2.1.2-cuda12.1-cudnn8-devel
执行:
bash展开代码docker run -it --gpus device=3 --net host -v /ssd/xd/tts/GPT-SoVITS:/ssd/xd/tts/GPT-SoVITS pytorch/pytorch:2.1.2-cuda12.1-cudnn8-devel bash
必要环境:
bash展开代码export http_proxy=101.136.19.261:10829
export https_proxy=101.136.19.261:10829
conda install -c conda-forge gcc -y
conda install -c conda-forge gxx -y
conda install ffmpeg cmake -y
cd /ssd/xd/tts/GPT-SoVITS
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
apt update && apt install -t git vim wget curl
加一句到~/.bashrc:
go展开代码export LD_LIBRARY_PATH=/opt/conda/lib/python3.10/site-packages/torch/lib:$LD_LIBRARY_PATH
一般的miniconda安装路径在这里:/root/miniconda3/envs/gsv/lib/python3.10/site-packages/torch/lib
设置容器语言环境: 你可以尝试在容器内设置语言环境,以支持中文字符显示。可以使用以下命令:
bash展开代码apt-get update && apt-get install -y locales
locale-gen zh_CN.UTF-8
export LANG=zh_CN.UTF-8
dockerfile:
bash展开代码RUN apt-get update && apt-get install -y locales \ && locale-gen zh_CN.UTF-8 \ && /usr/sbin/update-locale LANG=zh_CN.UTF-8 ENV LANG zh_CN.UTF-8
装一个合适的onnxruntime-gpu:

https://onnxruntime.ai/docs/install/#requirements
bash展开代码wget https://aiinfra.pkgs.visualstudio.com/PublicPackages/_apis/packaging/feeds/d3daa2b0-aa56-45ac-8145-2c3dc0661c87/pypi/packages/ort-nightly-gpu/versions/1.17.dev20240118002/ort_nightly_gpu-1.17.0.dev20240118002-cp310-cp310-manylinux_2_28_x86_64.whl/content
mv content ort_nightly_gpu-1.17.0.dev20240118002-cp310-cp310-manylinux_2_28_x86_64.whl
pip install ort_nightly_gpu-1.17.0.dev20240118002-cp310-cp310-manylinux_2_28_x86_64.whl
pip install onnx
docker push
push镜像给大家用:
go展开代码docker push kevinchina/deeplearning:2.1.2-cuda12.1-cudnn8-devel-gptsovitsv4
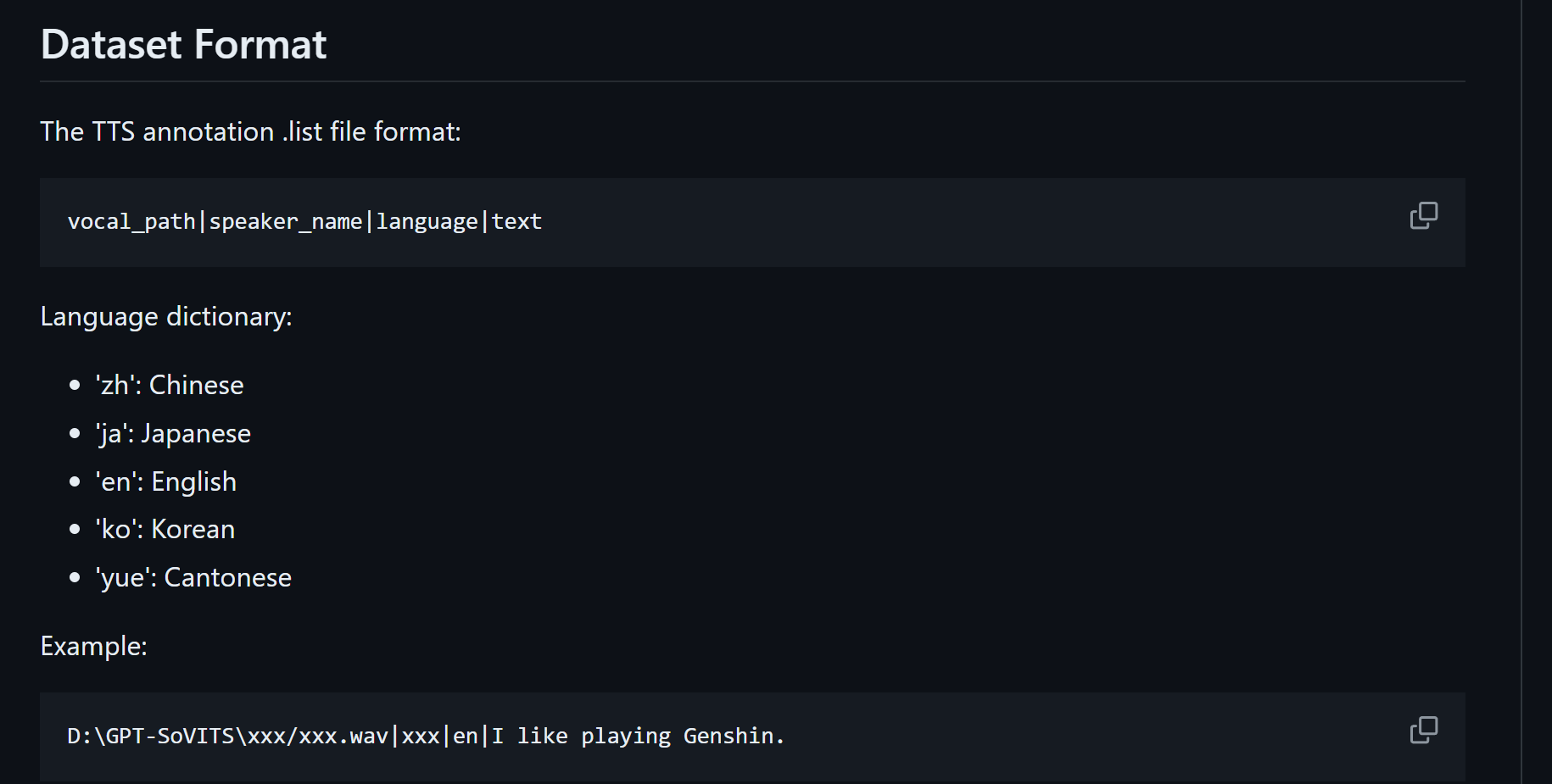
数据格式
拉取代码&下载模型
拉最新的代码:
bash展开代码cd /root/xiedong/tts
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
需要下载一些文件到对应目录。
-
下载预训练模型:
bash展开代码# https://huggingface.co/lj1995/GPT-SoVITS/tree/main 下载预训练模型,并将其放置在 GPT_SoVITS/pretrained_models 目录中。 我这里不再演示,注意,GPT-SoVITS项目下面的GPT-SoVITS目录里面有一个pretrained_models目录,别搞错了。 scp -r -P 16120 xiedong@101.136.19.26:/ssd/xiedong/tts/GPT-SoVITS/GPT_SoVITS/pretrained_models ./ -
从 G2PWModel_1.1.zip 下载模型,解压并重命名为 G2PWModel,然后将其放置在 GPT_SoVITS/text 目录中。(仅限中文TTS) https://paddlespeech.bj.bcebos.com/Parakeet/released_models/g2p/G2PWModel_1.1.zip
bash展开代码scp -r -P 16120 xiedong@101.136.19.26:/ssd/xiedong/tts/GPT-SoVITS/GPT_SoVITS/text/G2PWModel ./ -
对于 UVR5(人声/伴奏分离和混响移除,额外功能),从 UVR5 Weights 下载模型,并将其放置在 tools/uvr5/uvr5_weights 目录中。
bash展开代码scp -r -P 16120 xiedong@101.136.19.26:/ssd/xiedong/tts/GPT-SoVITS/tools/uvr5/uvr5_weights/* ./
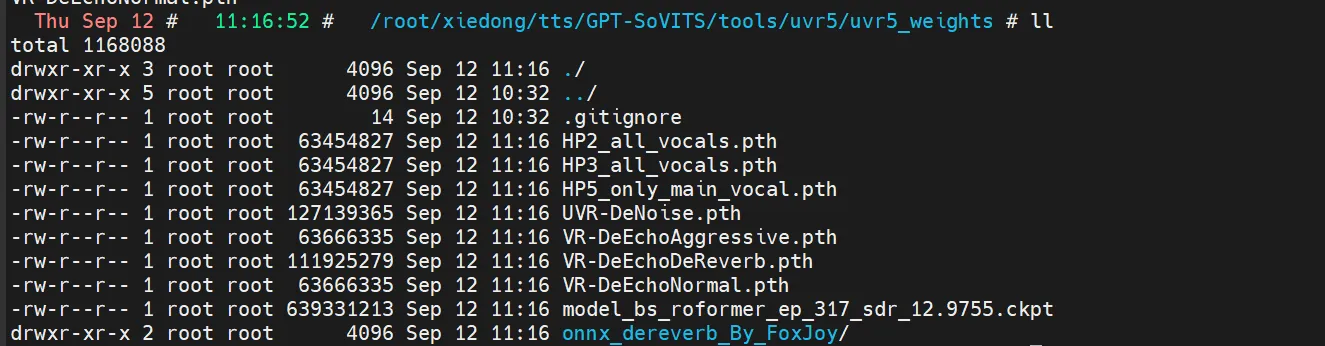
-
对于中文 ASR(额外功能),从 Damo ASR Model、Damo VAD Model 和 Damo Punc Model 下载模型,并将它们放置在 tools/asr/models 目录中。
-
对于英语或日语 ASR(额外功能),从 Faster Whisper Large V3 下载模型,并将其放置在 tools/asr/models 目录中。此外,其他模型 可能具有类似效果且占用更少的磁盘空间。 https://huggingface.co/Systran/faster-whisper-large-v3/tree/main

启动容器
目录介绍:
- GPT-SoVITS/GPT_weights_v2/ 存放训练后的GPT模型,pt结尾
- GPT-SoVITS/SoVITS_weights_v2/ 存放训练后的SoVITS模型,pth结尾
运行容器:
bash展开代码docker run -it --shm-size=16g --env=is_half=False --gpus all --net host -v /root/xiedong/tts:/root/xiedong/tts kevinchina/deeplearning:2.1.2-cuda12.1-cudnn8-devel-gptsovitsv4 bash
启动webui
bash展开代码cd /root/xiedong/tts/GPT-SoVITS-items
python webui.py
用自带的UVR5处理音频
第一步:分离人声:
- 人声/伴奏分离与混响去除的任务。使用 model_bs_roformer_ep_317_sdr_12.9755 模型进行处理,这是当前效果最好的模型,目的是提取人声。
展开代码记住:一定要mkdir创建好文件目录再开始。我的wav文件目录是/root/xiedong/tts/datasets/shiyu,我vocal存/root/xiedong/tts/datasets/shiyu_uvr5,我accompaniment存/root/xiedong/tts/datasets/shiyu_uvr5_accompaniment。我就像下图设么设置。
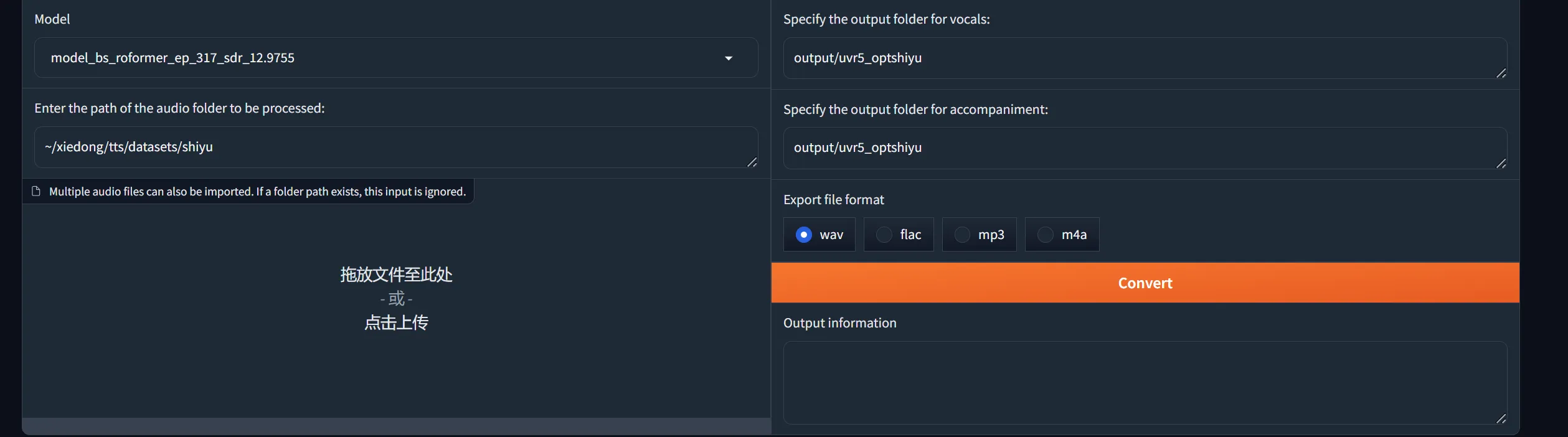
第二步:混响去除:
将输出的干声音频使用 onnx_dereverb_By_FoxJoy 处理去混响。
展开代码再mkdir一个存人声的目录:mkdir /root/xiedong/tts/datasets/shiyu_uvr5_2,然后这样写入去除这个路径的混响:/root/xiedong/tts/datasets/shiyu_uvr5。这一步很慢。
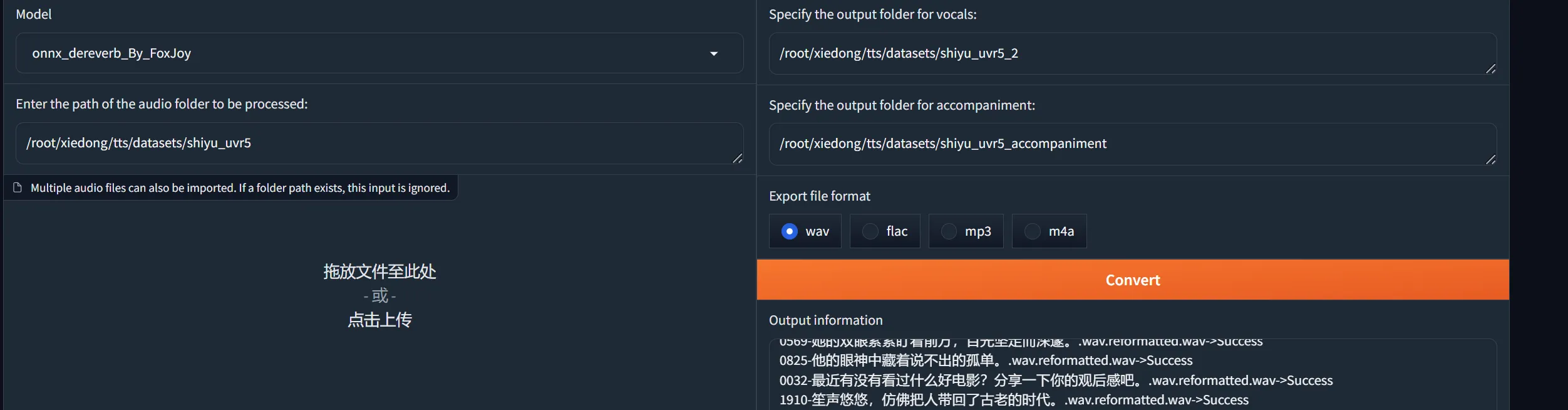
-
第三步:混响去除 使用 DeEcho-Aggressive 进行最后的混响去除。
-
输出格式:
- 输出格式选择 wav。
-
输出路径:
- 默认输出文件夹为 GPT-SoVITS-beta\output\uvr5_opt,建议不要修改输出路径,避免后续找不到文件。
-
处理结果文件说明:
(vocal)表示处理后的人声。(instrument)表示伴奏。(_vocal_main_vocal)表示无混响的音频文件。(others)是混响文件。- 最终使用的文件是
(vocal)和(_vocal_main_vocal),其他文件可以删除。
-
结束步骤:
- 处理结束后,记得在 WebUI 中关闭 UVR5 来节省显存。
切割音频
我不切
音频降噪
我不降噪
打标
开启打标后,模型会对所有wav打标记,生成一个文件/root/xiedong/tts/datasets/shiyu_uvr5/asr_opt/shiyu_uvr5.list
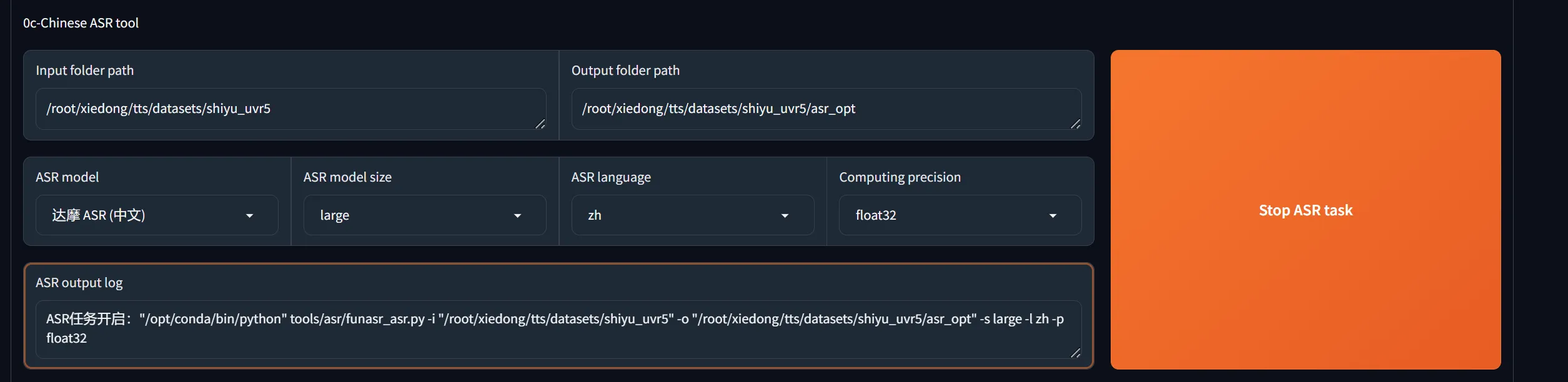
现在这个/root/xiedong/tts/datasets/shiyu_uvr5/asr_opt/shiyu_uvr5.list里是这个样子:
也就是这个格式:
bash展开代码vocal_path|speaker_name |language|text
校对标注
我其实本身有标注,我要把/root/xiedong/tts/datasets2/shiyuv2_vk2下面所有wav文件都标注出来。
我希望生成一个文件/root/xiedong/tts/datasets2/shiyuv2_vk2.list,每一行都是一个数据集的一个样本,格式是这样的:
bash展开代码vocal_path|speaker_name|language|text
- vocal_path 是wav文件绝对路径
- speaker_name 是说话人,我希望写成“shiyu”
- language得看情况,tts文本如果全是中文,那就是zh;全是英文,那就是en;两者都有,那也给zh。
展开代码Language dictionary: 'zh': Chinese 'ja': Japanese 'en': English 'ko': Korean 'yue': Cantonese
- text 是tts的文本。
我希望整体顺序是先zh,再en,最后中英混合的zh。
启动webui训练
bash展开代码cd /root/xiedong/tts/GPT-SoVITS-items
python webui.py
检查是否有这几个文件:
bash展开代码root@k8s-node-10:~/xiedong/tts/GPT-SoVITS# ll GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth
-rw-r--r-- 1 root root 106035259 Sep 12 03:09 GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth
root@k8s-node-10:~/xiedong/tts/GPT-SoVITS# ll GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2D2333k.pth
-rw-r--r-- 1 root root 93534164 Sep 12 03:09 GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2D2333k.pth
root@k8s-node-10:~/xiedong/tts/GPT-SoVITS# ll GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt
-rw-r--r-- 1 root root 155315150 Sep 12 03:09 'GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt'
0-前置数据集获取工具
一键三连:
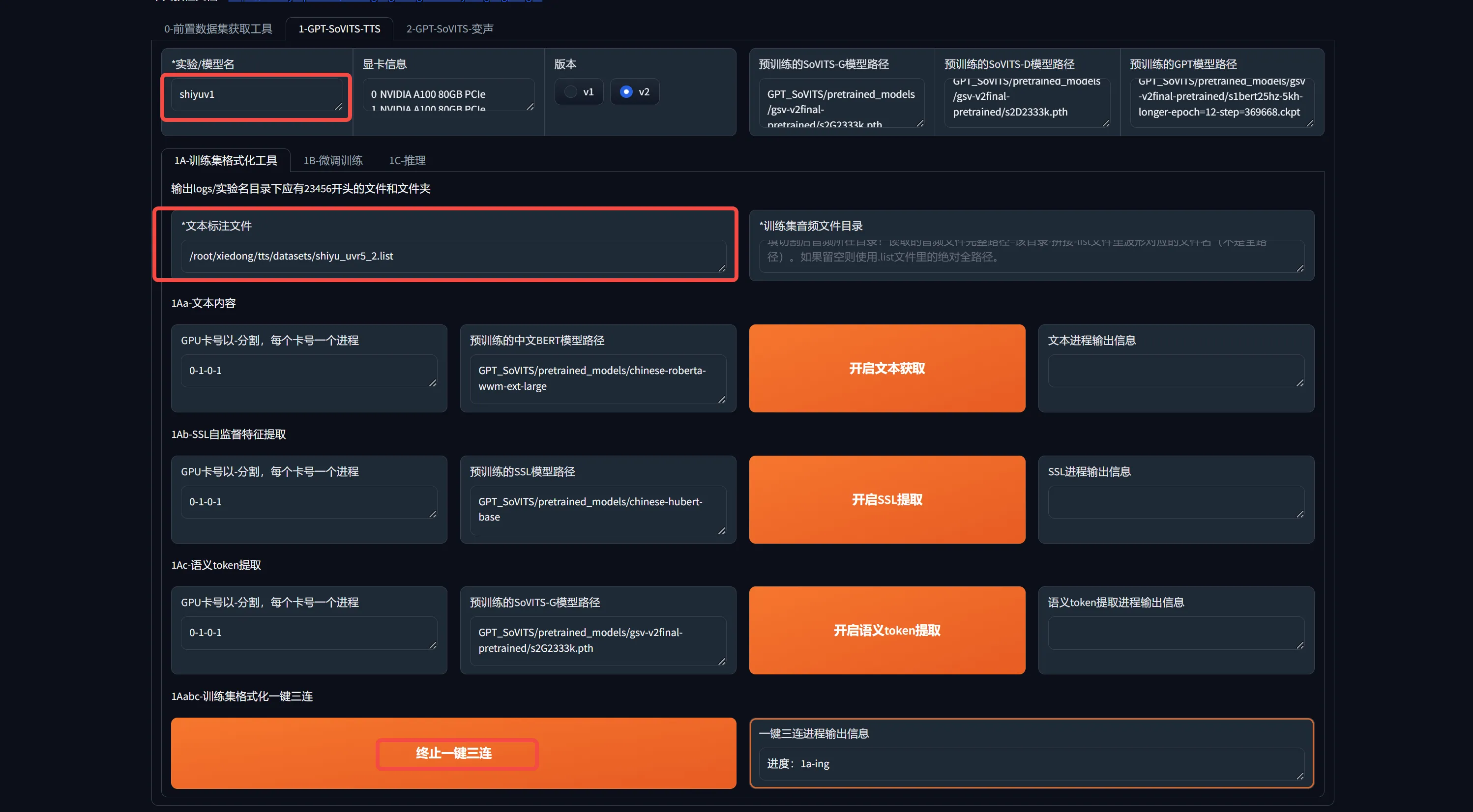
1B-微调训练
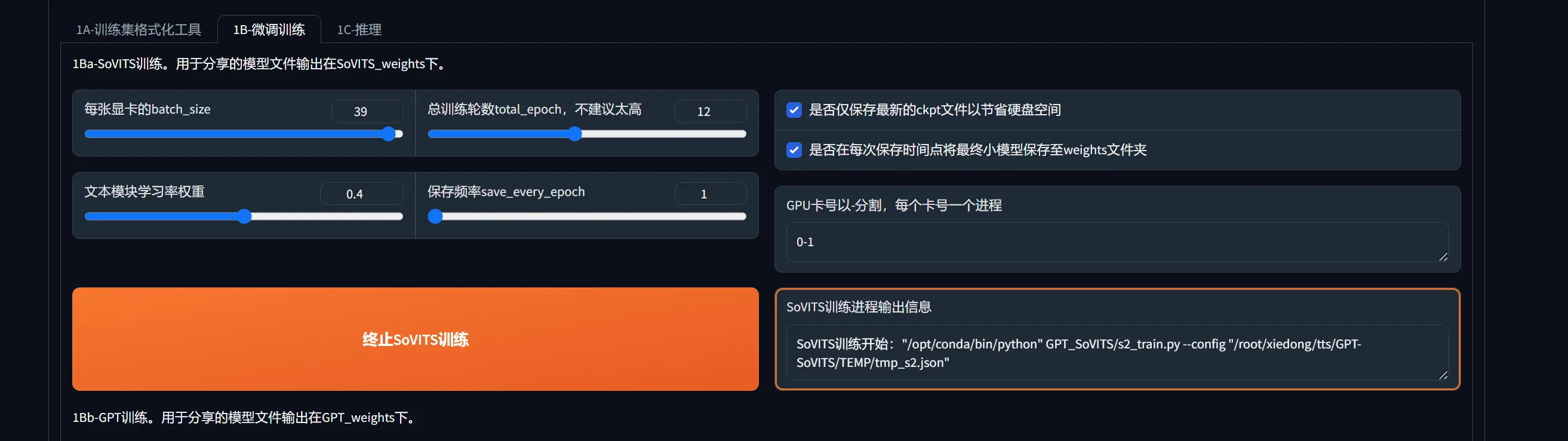
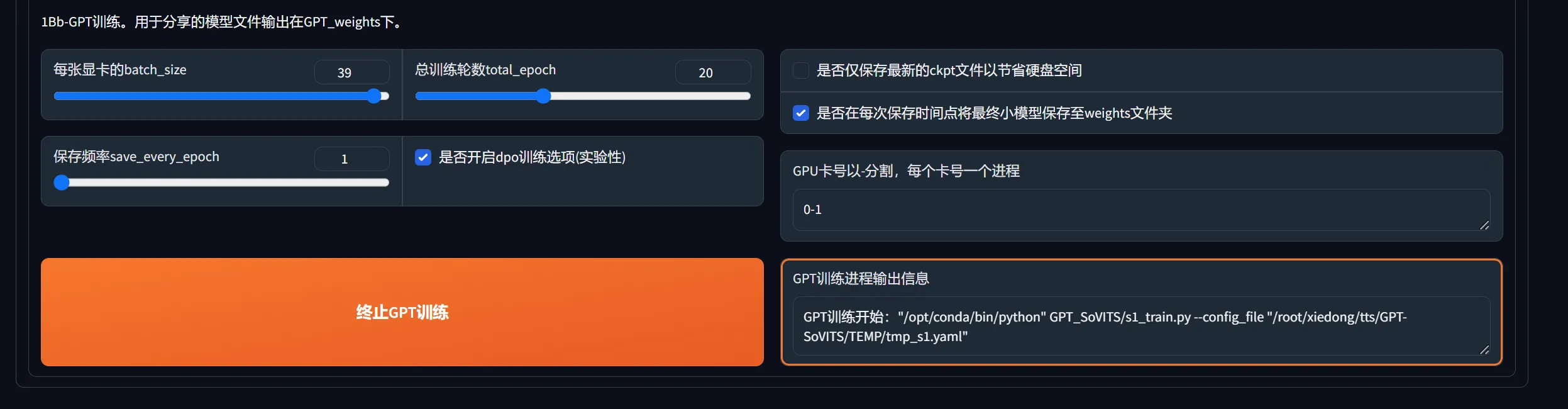
1C-推理
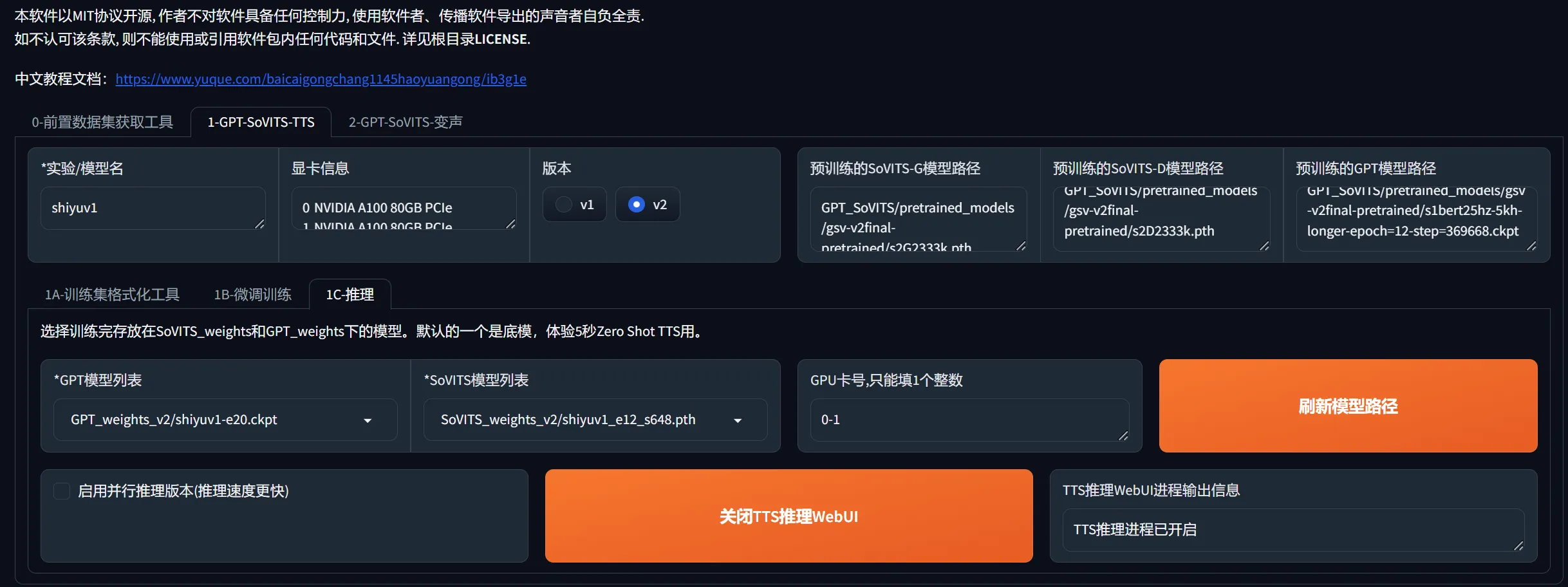
源码的推理


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!