原生多模态(Native Multimodality)
目录
1. 《Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context》
- 来源: Google DeepMind
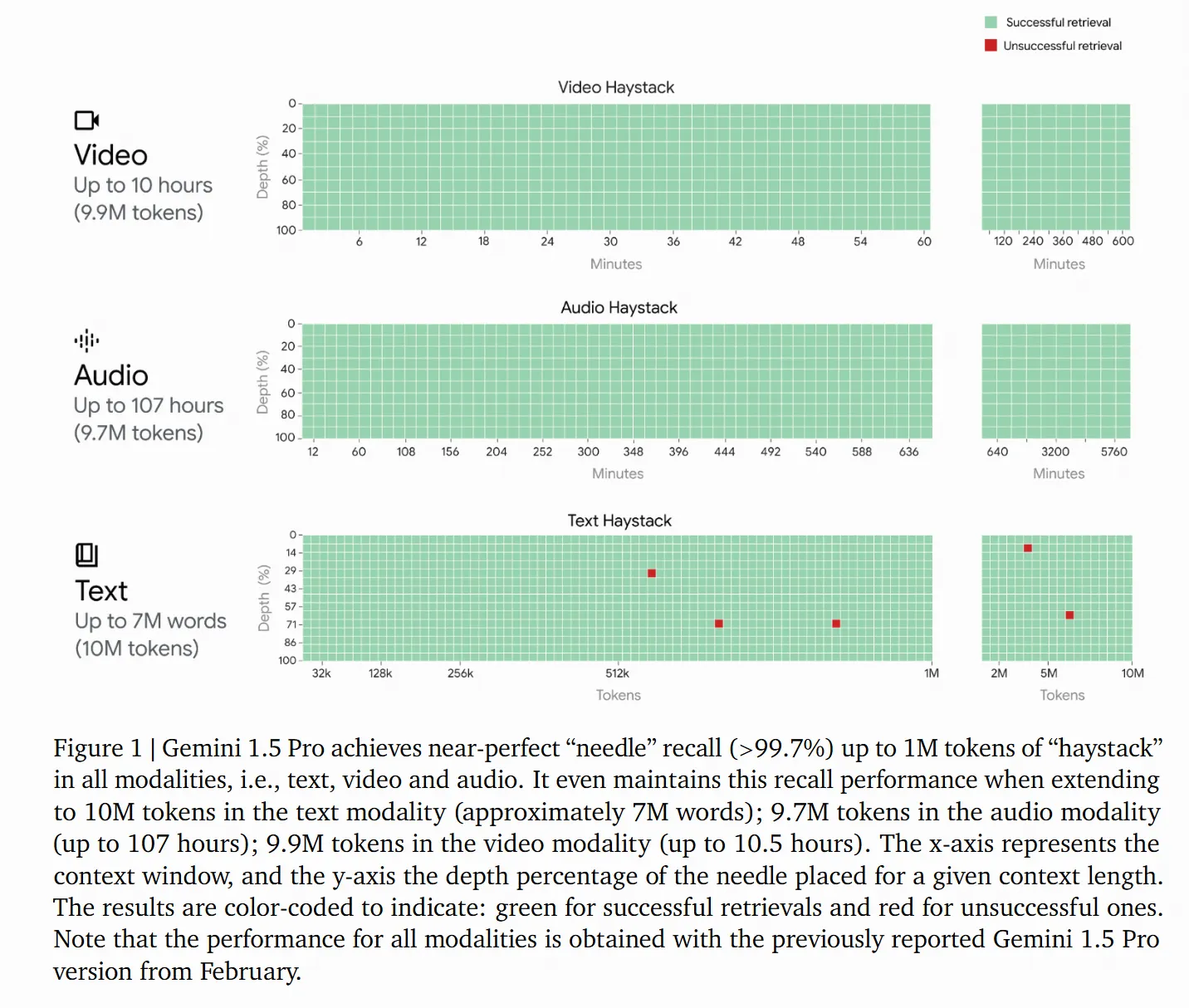
- 核心点: 介绍了如何将视频、音频和文本统一在一个混合专家模型(MoE)架构下。
- 技术解密: 它不再是将视频音频转成文字后再理解,而是将音频信号直接切碎成“音频 Token”,与视频帧
2. 《Audio-Visual LLM for Video Understanding》 (ICCV 2025)
- 来源: 学术界最新研究
- 核心点: 专门讨论了“全方位视频理解”。
- 技术解密: 论文提出了一种模态增强技术,利用特定 Token 触发视觉或听觉编码器。它强调了视觉和听觉的“互补性”——比如画面里只有手指滑动,但音频里有“咔哒”一声,模型能通过音频补全视觉上的逻辑。
3. 《UniAVLM: Unified Large Audio-Visual Language Models》 (PRICAI 2025)
- 来源: IBM Research
- 核心点: 解决音频和视频流“割裂”的问题。
- 技术解密: 之前的模型可能是“看一遍视频,听一遍音频”,而这篇论文研究的是如何让模型像人类一样**实时同步(Temporal Alignment)**视听信号,从而在对话中实现极高的准确度。
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录