https://mp.weixin.qq.com/s/dU428dZEB9HoNtxnBRFISQ
论文标题:
EvoLM: In Search of Lost Language Model Training Dynamics
论文链接:
https://arxiv.org/pdf/2506.16029
项目主页:
https://zhentingqi.github.io/internal/projects/EvoLM/
代码链接:
https://github.com/zhentingqi/evolm
EvoLM训练流程:
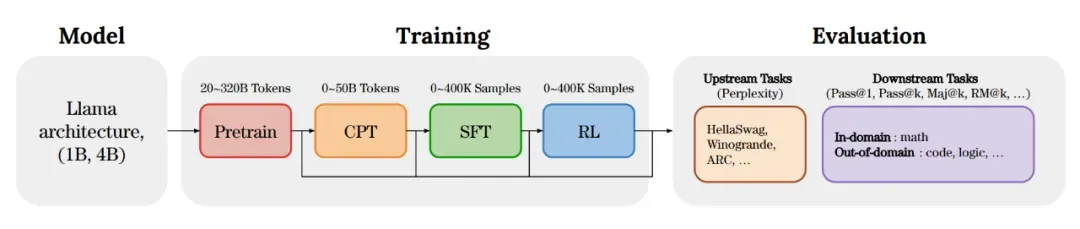
根据EvoLM论文的研究结果,以下是针对"8张4090"算力条件下的LLM炼丹最优配方总结:
📋 核心配方要点
- 基础模型选择
• 优先小模型:选择1B-3B参数的充分训练基座(如TinyLlama)
• 避坑:不要使用大模型的中间checkpoint,性能会显著下降
- 持续预训练(CPT) - 最关键步骤
• 必须执行:领域适配的CPT不能跳过
• 黄金比例:通用数据:领域数据 = 1:5(约16%通用数据回放)
• 算力分配:30-40B Tokens即可饱和,约需几天时间

- 监督微调(SFT)策略
• epoch控制:严格限制在2-4个epoch(3个为最佳)
• 防过拟合:超过4个epoch会损害泛化能力
• 留有余地:不要用SFT填满模型,为RL预留空间
- 强化学习(RL)取舍
• 饱和点:4-8个epoch或50-100K样本即达收益饱和
• 作用本质:RL主要提升置信度而非根本推理能力
• 算力警告:PPO需要4个模型副本,显存消耗巨大
⚖️ 算力分配决策树
场景一:追求领域专家(数学/医疗/法律)
• 配方:重SFT + 轻RL(70-90%预算给SFT)
• 理由:SFT对域内任务提升最直接稳定
场景二:追求通用推理能力
• 配方:轻SFT + 重RL(10% SFT + 90% RL)
• 风险:RL容易导致输出冗长,需要精细调优
🎯 监控指标革新
• 弃用:Validation Loss和PPL(后训练阶段零相关)
• 采用:ORM分数(与下游性能强相关0.62-0.84)
• 工具:使用现成Reward Model(如Skywork)进行验证
💡 终极建议
对于大多数资源受限场景,最稳妥路径是:
- 选择质量基座
- 执行带Replay的CPT
- 进行3个epoch的SFT
- 跳过RL(除非算力充裕)
EvoLM证明:精心调教的SFT模型往往优于配置错误的RL模型,在算力有限时尤为明显。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!