微调owl32b,让mobile agent v3更聪明
目录
背景
这是我的命令:
bash展开代码python run_mobileagentv3.py --adb_path "D:\platform-tools\adb.exe" --api_key "123" --base_url "http://10.142.18.204:8006/v1" --model "owl32b" --instruction "帮我整理所有与'黄金第4天'相关的微博动态" --add_info "整理某东西的微博动态的操作如下,全程不需要滚动操作:1. 微博应用图标不在可见范围内, 使用 open_app 微博 动作直接打开微博应用(无需滑动)。 2. 点击发现 icon。 3. 输入搜索词,但不要打开智搜开关。 4. 点击橙色的搜索按钮。 5. 在搜索结果里再去点击上方Tab里出现的智搜按钮,进入到智搜的结果页面。 6. 点击左下角的 继续问智搜 ,点击一次即可,再次出现就不要点击。 7. 关闭可能会弹出来的弹窗,然后点击右下方出现的'⬇'的 icon 按钮到内容的最底部,而不要使用滚动操作去滚动到最底部。 8. 点击屏幕最左边的下方的复制按钮,点击复制按钮的动作描述(Action description)要写成 点击复制按钮,之后就退出agent。"
构建一点微调数据训练这个模型:https://huggingface.co/mPLUG/GUI-Owl-32B
这个模型其实就是来源于:https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
理想上,GUI-Owl-32B会变成微博操作的一个专家。事实上又会如何呢?
分析
agent是这个:
https://github.com/X-PLUG/MobileAgent/tree/main/Mobile-Agent-v3
根据调用的源码看如何组织数据。
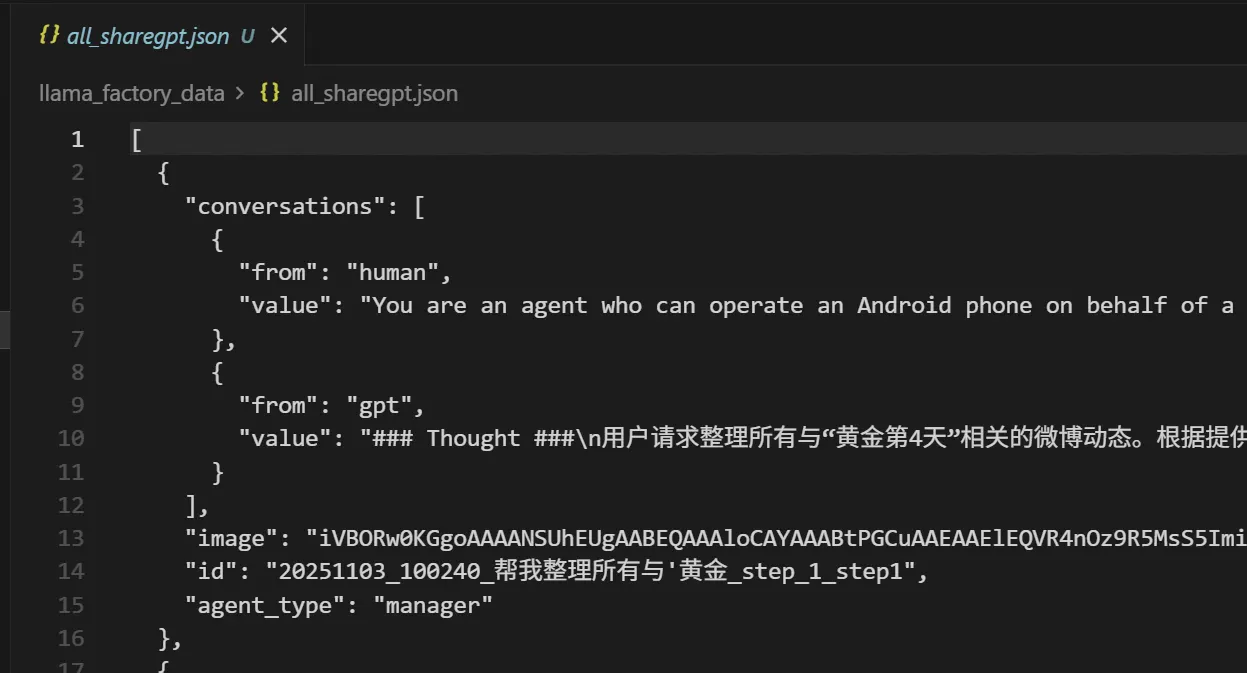
将log里数据转为训练数据格式
原始数据:
脚本 :convert_to_llama_factory.py
执行:
bash展开代码python convert_to_llama_factory.py --logs_dir logs --format sharegpt
转为这样:
启动镜像
bash展开代码llamafactory-qwen3vl:v3
准备训个lora,8卡直接训。
dataset_info.json:
bash展开代码{
"all_sharegpt": {
"file_name": "all_sharegpt.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"images": "images"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "human",
"assistant_tag": "gpt",
"system_tag": "system"
},
"info": "sharegpt数据,训练owl32B"
}
}
训练
bash展开代码#!/bin/bash
export SWANLAB_API_KEY=pM7Xvs5OS2EeXPO5gKXfJ # 设置在线跟踪模式API,这里我随便填的
export SWANLAB_LOG_DIR=/swanlab_log # 设置本地日志存储路径
export SWANLAB_MODE=cloud # 包含四种模式:cloud云端跟踪模式(默认)、cloud-only仅云端跟踪本地不保存文件、local本地跟踪模式、disabled完全不记录用于debug
# 重要参数自定义
# 多机训练参数
NUM_NODES=1 # 机器总数,根据需要修改s
JOB_NAME="run-owl32b" # k8s job 名称
CACHE_DIR=/mnt/jfs/cache/run-owl32b # 清理了数据
GROUP_NAME="aos" # 资源组名称
MODEL_NAME_OR_PATH="/mnt/jfs6/model/GUI-Owl-32B" # agent2训练结果
OUTPUT_DIR="/mnt/jfs/output/${JOB_NAME}" # 训练后模型保存路径
SWANLAB_NAME=$JOB_NAME # swanlab 项目名称
llamafactory-cli train \
--model_name_or_path $MODEL_NAME_OR_PATH \
--dataset_dir /mnt/s3fs/code_xd/X_23_owl模型训练 \
--cache_dir ${CACHE_DIR}/cache_dir \
--tokenized_path ${CACHE_DIR}/tokenized_cache \
--overwrite_cache false \
--dataset all_sharegpt \
--template qwen2_vl \
--output_dir $OUTPUT_DIR \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--trust_remote_code true \
--stage sft \
--do_train true \
--finetuning_type lora \
--freeze_vision_tower false \
--freeze_multi_modal_projector false \
--freeze_language_model false \
--cutoff_len 8192 \
--preprocessing_num_workers 1 \
--preprocessing_batch_size 1 \
--dataloader_num_workers 4 \
--logging_steps 10 \
--plot_loss True \
--overwrite_output_dir false \
--save_only_model false \
--learning_rate 1.0e-6 \
--num_train_epochs 5.0 \
--save_steps 100 \
--lr_scheduler_type cosine \
--bf16 True \
--flash_attn auto \
--report_to none \
--use_swanlab True \
--swanlab_project $SWANLAB_NAME \
--swanlab_mode cloud \
--save_strategy steps \
--data_shared_file_system true \
--ddp_timeout 180000000
lora_rank 默认是8
lora_alpha 默认是lora_rank * 2
导出模型
bash展开代码llamafactory-cli export \
--model_name_or_path /mnt/jfs6/model/GUI-Owl-32B \
--adapter_name_or_path /mnt/jfs/output/run-owl32b-6/checkpoint-1000 \
--template qwen2_vl \
--finetuning_type lora \
--export_dir /mnt/jfs/output/run-owl32b-merge-6 \
--export_size 5 \
--export_device cpu \
--export_legacy_format false
启动
融合模型启动:
bash展开代码python -m vllm.entrypoints.openai.api_server \
--model /mnt/jfs/output/run-owl32b-merge-6 \
--served-model-name owl32b \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--max-model-len 8192 \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 4 \
--api-key "123" --max-num-seqs 2
带lora,但vllm目前不知道视觉部分的lora,所以这个不好:
bash展开代码python -m vllm.entrypoints.openai.api_server \
--model /mnt/jfs6/model/GUI-Owl-32B \
--enable-lora \
--lora-modules owl32b=/mnt/jfs/output/run-owl32b \
--served-model-name owl32b \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--max-model-len 8192 \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 4 \
--api-key "123" \
--max-num-seqs 2 \
--max-lora-rank 8
llamafactory-cli api 部署:
bash展开代码LLAMAFACTORY_VERBOSITY=WARN llamafactory-cli api --model_name_or_path /mnt/jfs6/model/GUI-Owl-32B --adapter_name_or_path /mnt/jfs/output/run-owl32b-5/checkpoint-500 --template qwen2_vl --finetuning_type lora --infer_backend huggingface --trust_remote_code
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录