目录
镜像
GPT-SoVITS v4出来好久了,使用一下。
代码
bash展开代码git clone https://github.com/RVC-Boss/GPT-SoVITS.git
build镜像
bash展开代码cd GPT-SoVITS
bash docker_build.sh --cuda 12.6
启动容器
bash展开代码docker run -it \
--shm-size=16g \
--env=is_half=False \
--gpus all --net host \
-v /data/xiedong/GPT-SoVITS:/data/xiedong/GPT-SoVITS \
xd/gpt-sovits:local bash
下载模型
1
下载预训练模型放到GPT_SoVITS/pretrained_models,是下面这个项目里所有文件都放进去:
https://huggingface.co/lj1995/GPT-SoVITS/tree/main/gsv-v4-pretrained
2
从 G2PWModel_1.1.zip 下载模型,解压并重命名为 G2PWModel,然后将其放置在 GPT_SoVITS/text 目录中。(仅限中文TTS) https://paddlespeech.bj.bcebos.com/Parakeet/released_models/g2p/G2PWModel_1.1.zip
3
git clone https://huggingface.co/lj1995/VoiceConversionWebUI
里面这个uvr5_weights/
放tools/uvr5/uvr5_weights 目录中。
bash展开代码/data/xiedong/GPT-SoVITS/tools/uvr5$ cp -r /data/xiedong/GPT-SoVITS/model/VoiceConversionWebUI/uvr5_weights/ .
开启
启动webui
bash展开代码cd /data/xiedong/GPT-SoVITS
python webui.py
洗数据
人声/伴奏分离与混响去除
清洗出我们的训练音频:
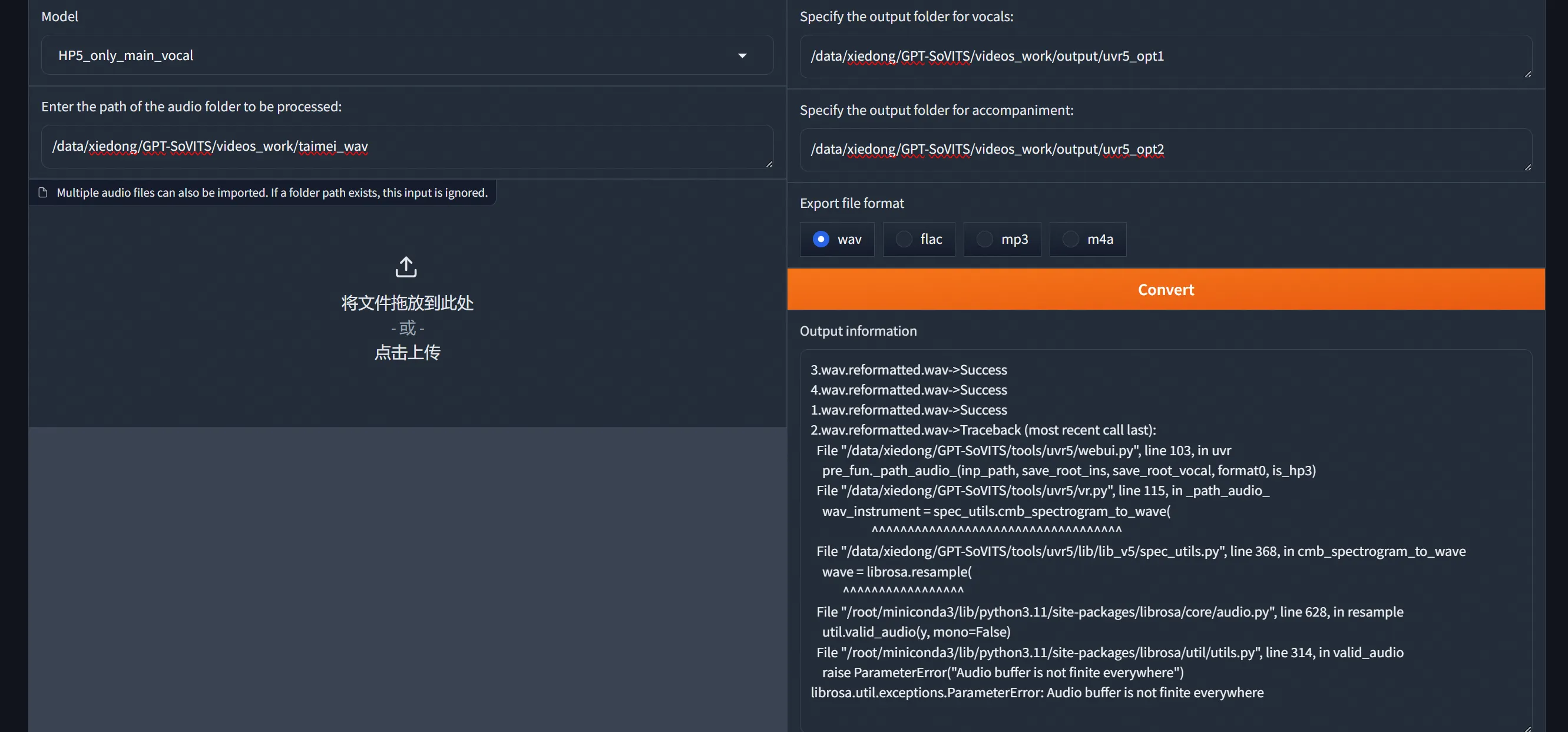
人声/伴奏分离与混响去除的任务。使用 model_bs_roformer_ep_317_sdr_12.9755 模型进行处理,这是当前效果最好的模型,目的是提取人声。
点击按钮打开:

9873端口。
HP5_only_main_vocal
提取人声:
混响去除
onnx_dereverb_By_FoxJoy
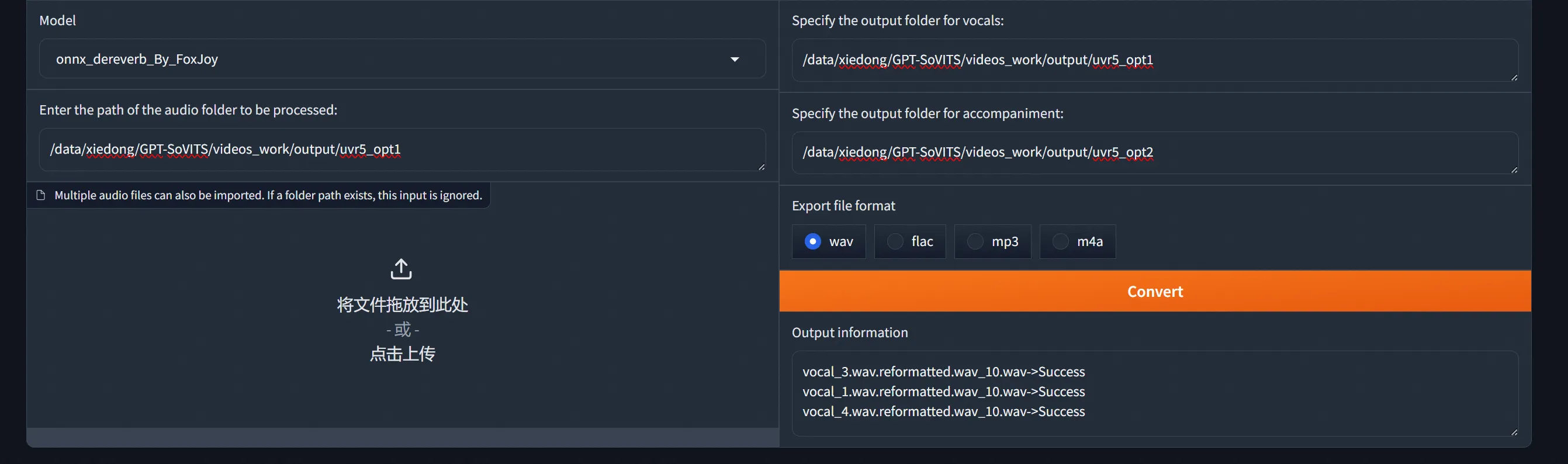
混响去除 使用 DeEcho-Aggressive 进行最后的混响去除。
处理
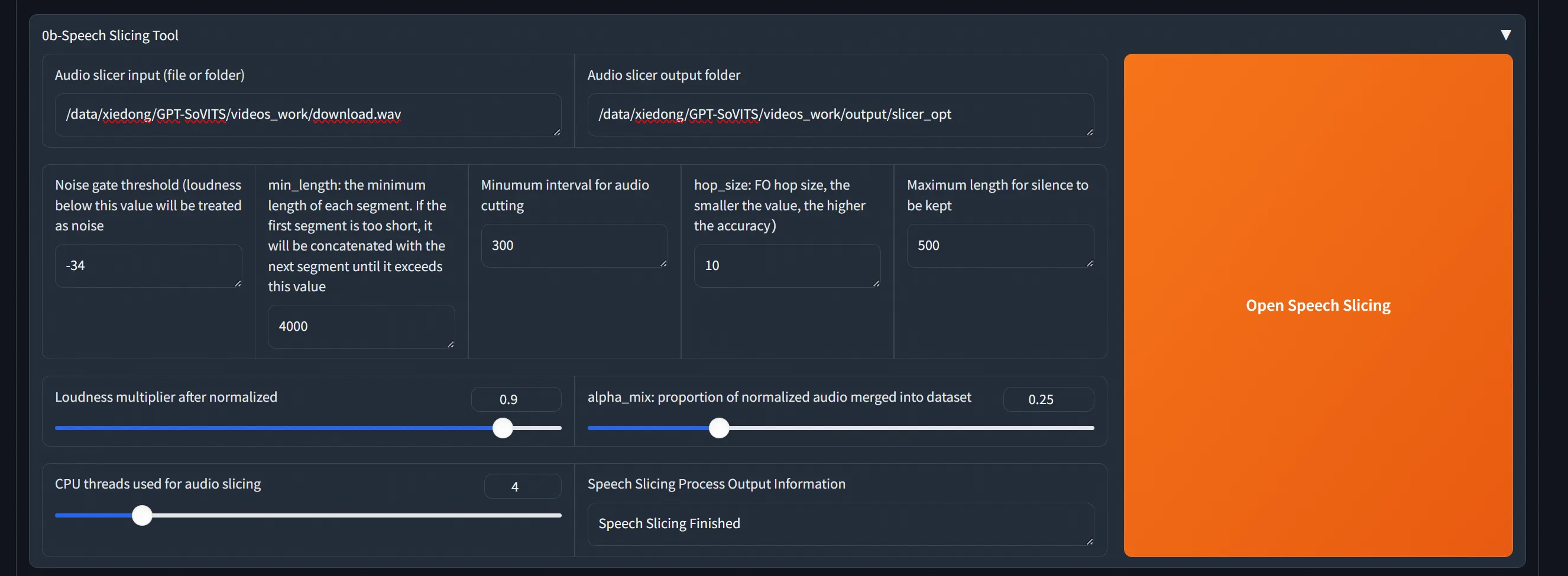
给一个音频文件,然后点击按钮开始切分:
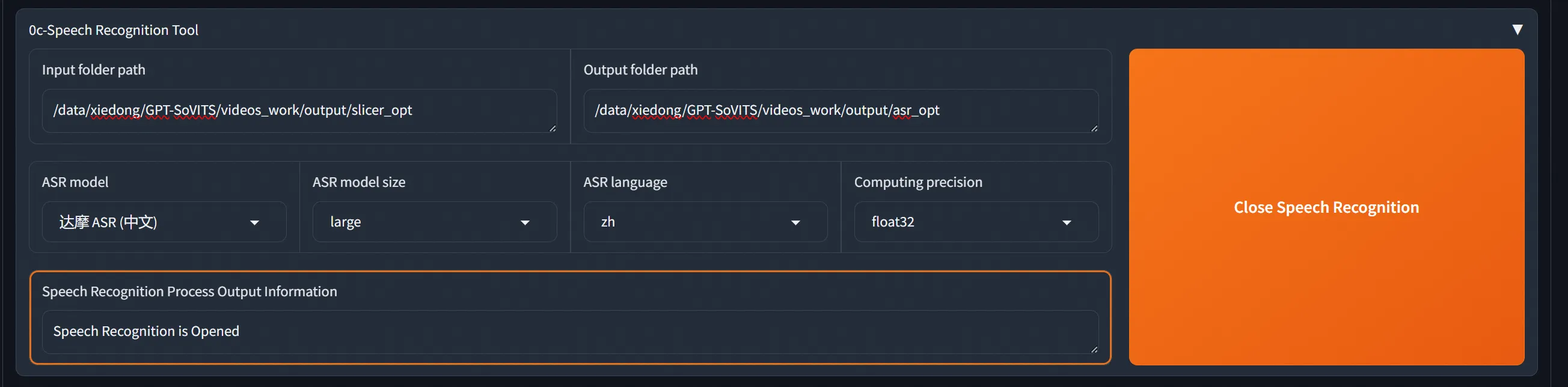
设置好输入输出,开始asr:
点击按钮,进行音频标注:

后台日志:
bash展开代码
"/root/miniconda3/bin/python" -s tools/subfix_webui.py --load_list "/data/xiedong/GPT-SoVITS/videos_work/output/asr_opt/slicer_opt.list" --webui_port 9871 --is_share False
Running on local URL: http://0.0.0.0:9871
To create a public link, set `share=True` in `launch()`.
音频标注,访问9871端口。
标注完来到第二个tab。跟着点就行了,有问题就看后台日志。或者下面直接一件三连。
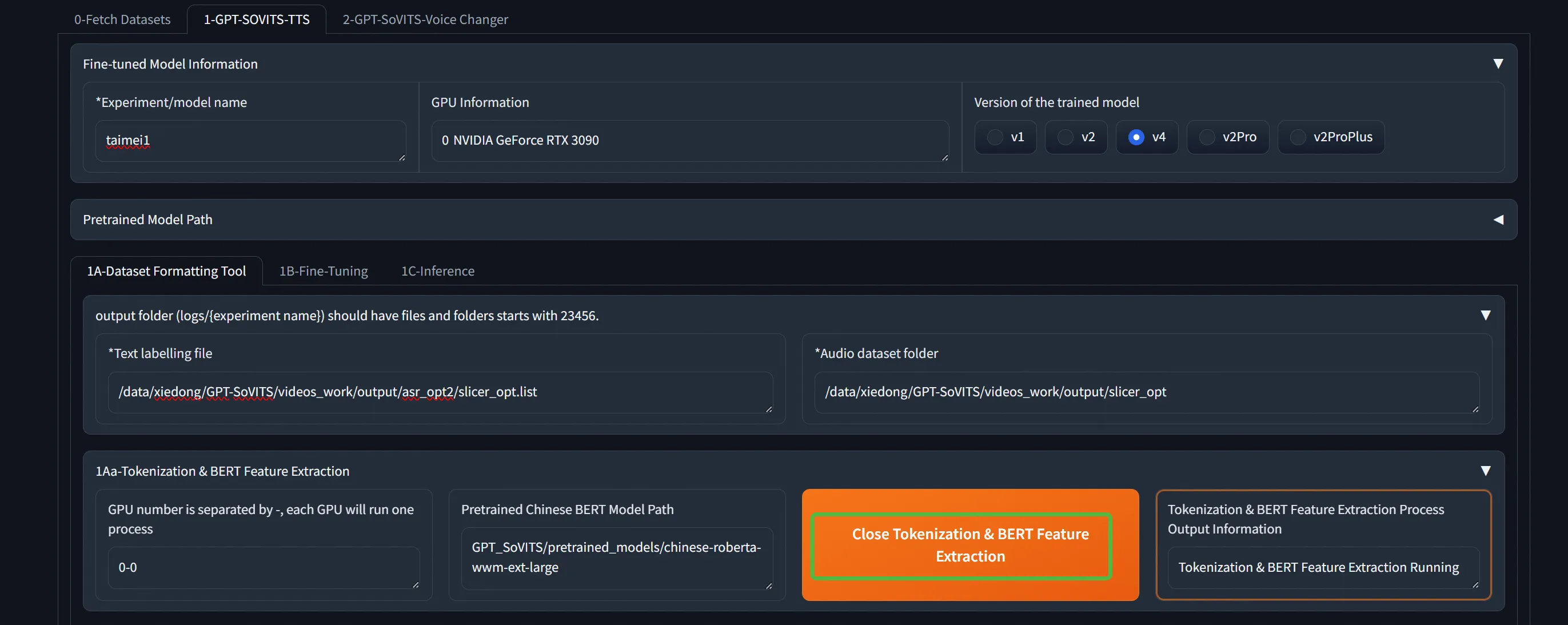
来到新的tab开始训练。依次进行2个训练。
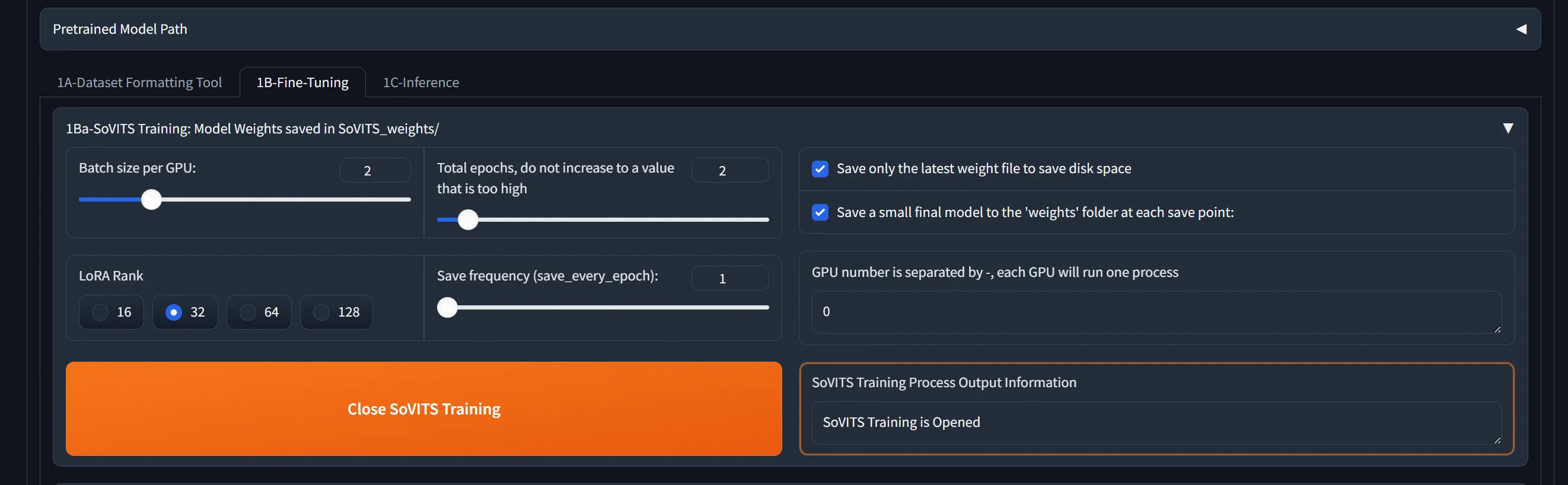
训练完后,在新tab,选好权重开始webui:
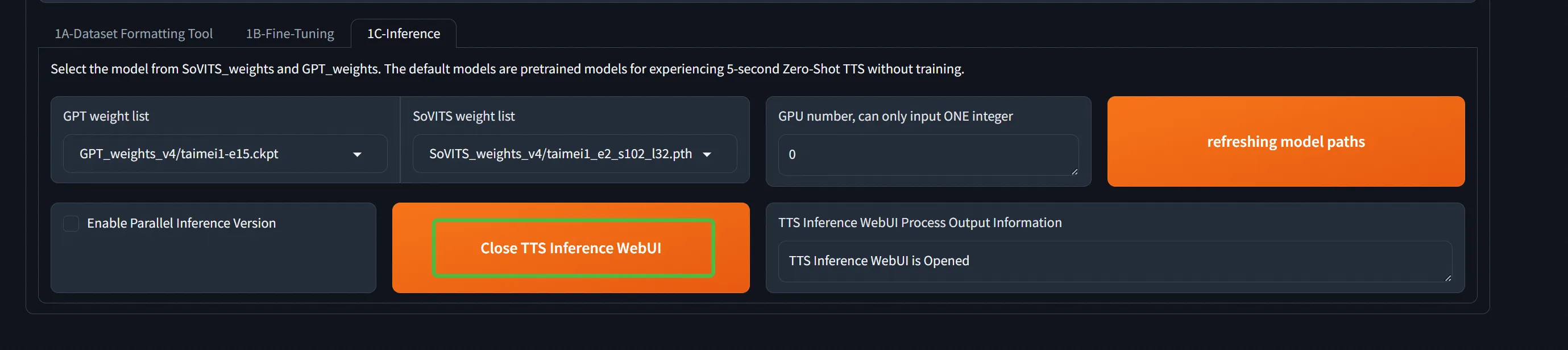
端口记录
推理
mkdir -p /data/xiedong/GPT-SoVITS/GPT_SoVITS/pretrained_models/fast_langdetect 不然报错
启动服务
创建custom_tts_config.yaml:
bash展开代码custom:
bert_base_path: GPT_SoVITS/pretrained_models/chinese-roberta-wwm-ext-large
cnhuhbert_base_path: GPT_SoVITS/pretrained_models/chinese-hubert-base
device: cuda
is_half: true
t2s_weights_path: GPT_weights_v4/taimei2-e15.ckpt
version: v4
vits_weights_path: SoVITS_weights_v4/taimei2_e2_s92_l32.pth
运行服务:
bash展开代码python3 api_v2.py -a 0.0.0.0 -p 9875 -c custom_tts_config.yaml
请求:
python展开代码import requests
import io
import soundfile as sf
# 流式请求
url = "http://101.126.150.28:9875/tts"
data = {
"text": "你好,这是一个测试语音合成。",
"text_lang": "zh",
"ref_audio_path": r"/data/xiedong/GPT-SoVITS/videos_work/output/taimei_processed/2.wav_0001233600_0001397440.wav",
"prompt_lang": "zh",
"prompt_text": "我相信威哥不会真的说坏话的啦,可能只是在开玩笑呢。",
"streaming_mode": True,
"media_type": "wav"
}
response = requests.post(url, json=data, stream=True)
# 保存流式音频数据
with open("output.wav", "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
请求参数:
bash展开代码
### 必需参数
- `text`: 要合成的文本内容
- `text_lang`: 文本语言,支持 "zh", "en", "ja", "ko", "yue", "auto", "auto_yue"
- `ref_audio_path`: 参考音频文件路径
- `prompt_lang`: 参考音频的语言
### 可选参数
#### 基础参数
- `prompt_text`: 参考音频对应的文本内容(可选)
- `aux_ref_audio_paths`: 辅助参考音频路径列表(多说话人音色融合)
- `streaming_mode`: 是否启用流式输出,`true`/`false`
- `media_type`: 音频格式,支持 "wav", "ogg", "aac", "raw"
- `text_split_method`: 文本切分方法
- `cut0`: 不切分
- `cut1`: 按标点符号切分
- `cut2`: 按句子切分
- `cut3`: 按段落切分
- `cut4`: 智能切分
- `cut5`: 长文本切分
#### 模型控制参数
- `top_k`: Top-K采样,默认5
- `top_p`: Top-P采样,默认1.0
- `temperature`: 温度参数,默认1.0
- `repetition_penalty`: 重复惩罚,默认1.35
- `sample_steps`: VITS模型采样步数,默认32
- `super_sampling`: 是否使用超采样,`true`/`false`
#### 批处理参数
- `batch_size`: 批处理大小,流式模式建议设为1
- `batch_threshold`: 批处理阈值,默认0.75
- `split_bucket`: 是否分桶处理,`true`/`false`
- `parallel_infer`: 是否并行推理,`true`/`false`
#### 音频控制参数
- `speed_factor`: 语速控制,1.0为正常速度
- `fragment_interval`: 音频片段间隔,默认0.3秒
- `return_fragment`: 是否返回片段,`true`/`false`
#### 其他参数
- `seed`: 随机种子,-1为随机
- `inp_refs`: 输入参考音频列表
bash展开代码"zh" - 中英混合 (Chinese-English Mixed)
"all_zh" - 纯中文
"en" - 纯英文
"ja" - 日英混合
"ko" - 韩英混合
"yue" - 粤英混合
"auto" - 多语种混合(自动识别)
"auto_yue" - 多语种混合(粤语)
中英混合支持不是那么好。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!