大模型安全研究1-abliteration
目录
原理
现代LLM在安全性和遵循指令方面进行了微调,这意味着他们接受过拒绝有害请求的训练。在他们的博客文章中,Arditi 等人。已经表明这种拒绝行为是由模型残差流中的特定方向调节的。如果我们阻止模型表示这个方向,它就会失去拒绝请求的能力。相反,人为添加此方向可能会导致模型拒绝无害的请求。
按照 此文 的描述,下面三个地方的残差块:
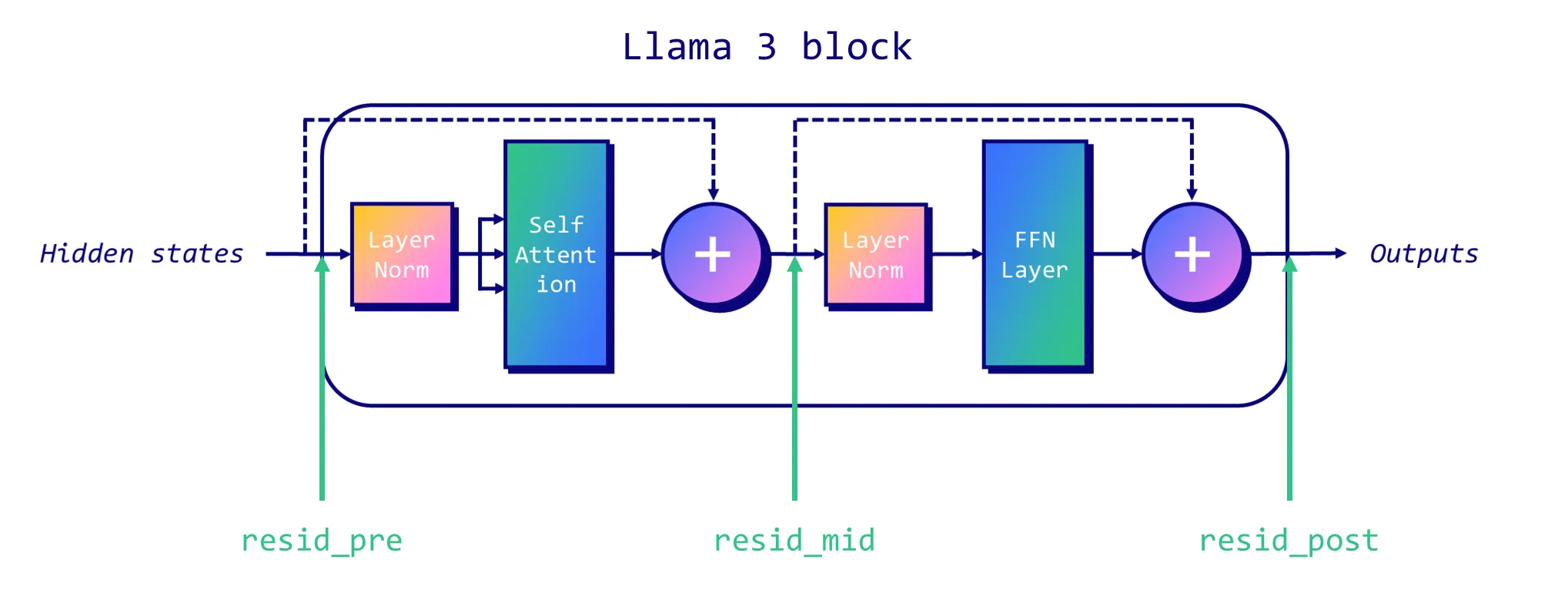
区分含义
在failspy的这篇说明里区分了概念:
“Abliteration” 的词源和定义:
这个词是 Ablation(消融) + Obliteration( obliteration) 的组合。
- Ablation(消融):在机器学习领域,这是一种研究模型内部工作机制的技术。具体方法是“切除”或“禁用”模型的某个部分(例如,某个神经元、注意力头或一层网络),然后观察模型性能的变化,从而理解该部分的功能。
- Obliteration( obliteration):意为“彻底毁灭”、“完全抹去”。
因此,“abliteration” 可以定义为:一种通过彻底抹除(obliterate)模型中与特定不良行为(如拒绝回答)相关的内部特征或方向,来实现对该行为进行外科手术式切除(ablate)的技术。
简单来说,它的目标不是削弱,而是彻底根除某个特定特征。
对比 : Abliteration vs. Fine-tuning(微调)
这是最重要的区分。两者都是改变模型行为的方法,但原理截然不同。
| 特征 | Abliteration(正交化方法) | Fine-tuning(微调) |
|---|---|---|
| 原理 | 外科手术式:直接在模型权重上做精确的数学操作(如正交化),以隔离和移除一个特定的、已知的“特征方向”。 | 教育和训练式:使用新的数据集,通过梯度下降来更新模型的大部分或全部权重,让模型“学习”新的行为模式。 |
| 数据量 | 需要很少的数据(仅用于识别不良特征)。 | 通常需要大量的高质量数据。 |
| 精确度 | 目标高精度,只改变特定行为,力求保持原始模型的所有其他知识和能力不变。 | 影响广泛,可能会带来灾难性遗忘,即模型在学习新行为时忘记旧知识。 |
| 比喻 | 像用精准的激光手术刀切除一个肿瘤,不影响周围健康组织。 | 像让学生通过大量刷题来改变解题习惯,可能因此忘记一些不常考的基础知识。 |
对比 : Abliteration vs. “Uncensored” Fine-tunes(通常的“去审查”微调)
很多所谓的“去审查”模型是通过在大量“越狱”提示和期望回答的数据集上微调得到的。
- Abliteration:基于一个科学假设(“拒绝行为由单一方向介导”),直接从根源上移除“审查机制”。
- Uncensored Fine-tune:是训练模型学会一种新的行为——即用不拒绝的回答方式,来覆盖它原本的拒绝倾向。模型底层可能仍然“知道”要拒绝,但被训练成“不这么说”。
abliteration模型
abliterated-v3 收集的一些模型;https://huggingface.co/collections/failspy/abliterated-v3-664a8ad0db255eefa7d0012b
实际测试
下载模型:
bash展开代码pip install modelscope modelscope download --model Qwen/Qwen3-4B-Instruct-2507
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录