优化GRPO——腾讯提出SPO
目录
https://arxiv.org/pdf/2509.13232
Single-stream Policy Optimization 论文总结
基本信息
- 论文标题: Single-stream Policy Optimization
- 研究领域: 大语言模型(LLM)策略优化
研究背景与动机
现有方法的局限性
当前大语言模型的策略梯度优化主要采用基于组的方法(group-based methods),如GRPO(Group-based Reinforcement Policy Optimization)。这些方法虽然通过即时基线(on-the-fly baselines)来减少方差,但存在以下关键缺陷:
- 退化组问题: 频繁出现的退化组会抹除学习信号,影响模型训练效果
- 同步障碍: 同步屏障阻碍了系统的可扩展性,限制了大规模部署的效率
研究目标
本文旨在解决现有策略优化方法的根本性缺陷,提出一种更高效、更可扩展的单流策略优化方法。
核心贡献
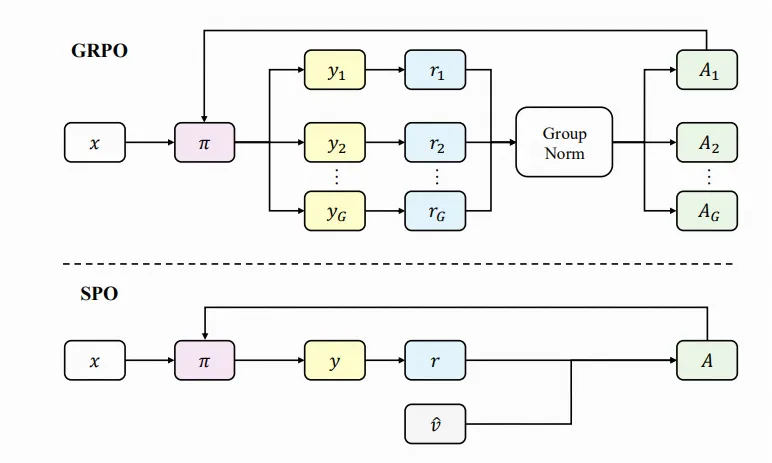
Single-stream Policy Optimization (SPO)
论文提出了Single-stream Policy Optimization(单流策略优化)方法,通过设计层面的改进彻底解决了现有方法的问题:
关键技术创新
-
持久化KL自适应值跟踪器:
- 用持久化、KL自适应的值跟踪器替代传统的每组基线(per-group baselines)
- 提供更稳定和连续的基线估计
-
全局优势标准化:
- 在整个数据流中进行全局优势标准化,而非局限于组内标准化
- 提高了优化的一致性和稳定性
-
消除同步屏障:
- 通过单流设计消除了组间同步的需求
- 显著提高了系统的可扩展性和并行处理能力
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录