Distill CLIP (DCLIP)
目录
https://arxiv.org/abs/2505.21549
论文总结:Distill CLIP (DCLIP):通过跨模态Transformer蒸馏增强图像-文本检索
研究背景与动机
CLIP模型在零样本分类方面表现优异,但在需要细粒度跨模态理解的检索任务中存在局限性,主要因为其依赖固定图像分辨率和有限上下文。DCLIP旨在解决这一问题,既要提升多模态图像-文本检索性能,又要保持原始CLIP模型强大的零样本分类能力。
核心方法
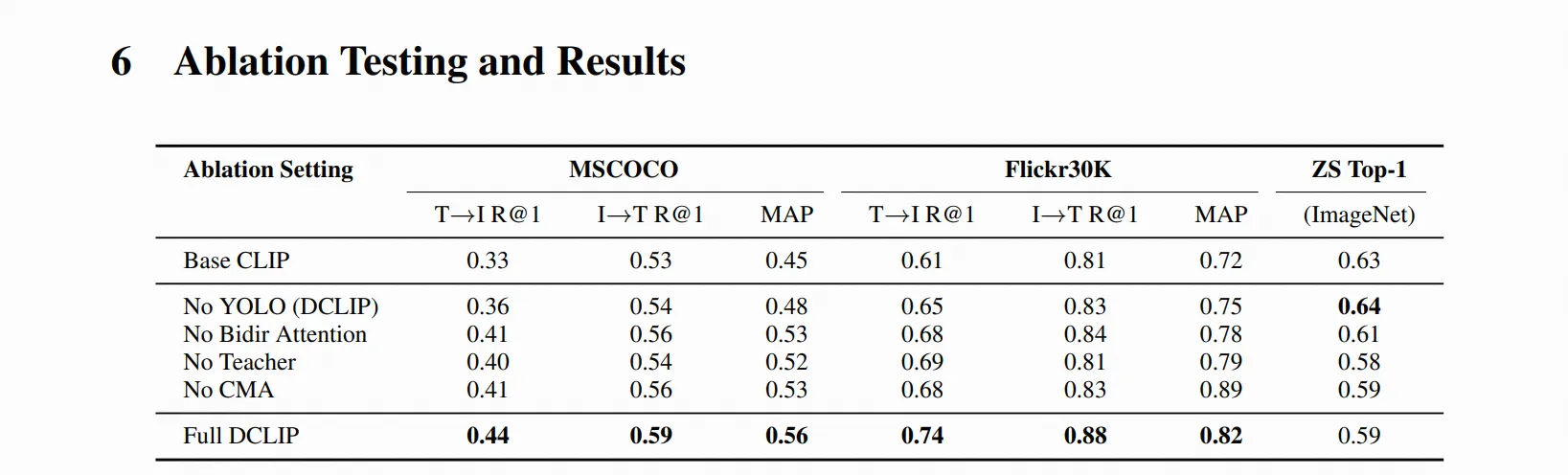
DCLIP采用元教师-学生蒸馏框架:
-
元教师设计:
- 使用YOLOv8x提取图像区域特征
- 通过双向跨模态注意力机制融合YOLO提取的图像区域和相应文本片段
- 生成语义和空间对齐的全局表示
-
学生模型:
- 采用轻量级设计,仅对CLIP的图像编码器进行微调
- 文本编码器保持冻结,维持与原始CLIP语义空间的对齐
- 通过混合损失函数学习(对比学习+余弦相似度目标)
-
非对称架构:
- 只适应图像编码器,文本编码器保持不变
- 这种设计防止模型通过平凡对齐走捷径,并将学习的图像特征锚定到CLIP的潜在空间
实验设置与数据
- 训练数据:仅使用约67,500个样本(来自MSCOCO、Flickr30k和Conceptual Captions)
- 模型规模:支持ViT-B/32、ViT-B/16、ViT-L/14等不同backbone
- 评估指标:Recall@K、MAP(检索);Top-1/Top-5准确率(零样本分类)
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录