目录
1. 梯度消失如何缓解?
(1)梯度消失是深度神经网络训练过程中出现的一种现象,指的是在反向传播时,靠近输入层的梯度变得非常小,几乎趋近于零。这通常发生在使用如 Sigmoid 或 Tanh 等饱和激活函数的深层网络中,由于链式法则导致多个小于1的数连乘,使得梯度指数级衰减。
(2)梯度消失的现象主要表现为模型训练缓慢甚至停滞,靠近输入层的参数几乎不更新,导致网络无法有效学习特征。这会直接影响模型的收敛速度和最终性能,尤其在层数较多的情况下更为明显。
(3)缓解梯度消失的方法包括:使用如 ReLU 及其变体等非饱和激活函数;采用合适的参数初始化方法如 He 初始化 或 Xavier 初始化,保证信号传播的稳定性;引入 Batch Normalization 层来标准化每层输出;利用 残差连接(Residual Connection) 使梯度更容易回传;以及在必要时使用 梯度裁剪(Gradient Clipping) 防止梯度过小或过大带来的训练不稳定问题。
2. 梯度爆炸如何缓解?
梯度爆炸(Gradient Explosion) 是深度神经网络训练过程中与梯度消失相对的问题,指的是在反向传播过程中,梯度值变得非常大,导致参数更新幅度过大,模型无法收敛。这种现象通常出现在深层网络或循环神经网络(RNN)中,由于权重矩阵的连乘使得梯度呈指数级增长。
梯度爆炸的现象主要表现为训练过程中损失函数剧烈震荡、不收敛甚至出现 NaN 值,参数更新不稳定,模型性能差。尤其在 RNN 中,长期依赖问题容易导致梯度在时间步上不断累积放大,从而引发梯度爆炸。
缓解梯度爆炸的方法包括:使用梯度裁剪(Gradient Clipping),即设定一个阈值对梯度进行裁剪,防止其过大;采用合适的参数初始化方法如 Xavier 初始化 或 He 初始化,避免初始权重过大;引入 Batch Normalization 来标准化每层输出,稳定训练过程;在 RNN 中可使用其变体如 LSTM 或 GRU 来控制信息流动,减轻梯度不稳定的问题。
3. 过拟合如何缓解?
过拟合(Overfitting) 是机器学习中常见的问题,指的是模型在训练数据上表现非常好,但在未见过的测试数据上表现显著下降。这是因为模型过于“记住”了训练数据中的噪声、细节或非普遍特征,而失去了对新数据的泛化能力。过拟合通常发生在模型复杂度过高、训练数据不足或噪声较多的情况下。
过拟合的现象包括:训练集损失持续下降且趋于零,而验证集损失在下降一段时间后开始上升;模型在训练数据上准确率很高,但在测试数据上表现差;模型对输入的小扰动敏感,泛化能力弱。
缓解过拟合的方法包括:增加训练数据量或使用数据增强(Data Augmentation)来扩展数据集;使用正则化方法如 L1/L2 正则化 来限制模型复杂度;引入 Dropout 层随机丢弃部分神经元,提升泛化能力;采用早停法(Early Stopping),在验证集性能不再提升时提前终止训练;减少模型复杂度(如减少网络层数或神经元数量),使其更匹配任务难度。
4. 什么是 ROC 曲线和 AUC 值?AUC 越高是否一定代表模型更好?
ROC 曲线(Receiver Operating Characteristic Curve)是一种用于评估二分类模型性能的图形工具。它通过绘制不同分类阈值下的真正例率(TPR,也称为召回率)与假正例率(FPR)之间的关系曲线,来展示模型在不同阈值下的整体表现。ROC 曲线的横轴是 FPR,表示错误地将负类样本预测为正类的比例;纵轴是 TPR,表示正确识别出的正类样本比例。通过改变分类阈值,可以得到 ROC 曲线上的一系列点,从而描绘出模型的判别能力。
AUC 值(Area Under the Curve)是指 ROC 曲线下方的面积,用来量化模型的整体性能。AUC 的取值范围在 0.5 到 1 之间。AUC 越高,通常意味着模型的区分能力越强。当 AUC 为 1 时,表示模型完美地区分了正负类;当 AUC 为 0.5 时,表示模型的预测等同于随机猜测;而 AUC 小于 0.5 则说明模型的表现比随机还差。
虽然 AUC 是一个非常有用的综合评价指标,但AUC 越高并不一定代表模型在所有情况下都更好 。
首先,AUC 反映的是模型整体排序能力,并不关注特定阈值下的表现。在某些实际应用中,我们可能更关心模型在某一特定区域的表现,例如在医学诊断中希望尽可能多地找出真正的阳性病例(即高召回率),即使这意味着会有更多的假阳性。在这种情况下,仅看 AUC 可能无法准确反映模型是否满足实际需求。
其次,AUC 没有考虑误分类带来的不同代价。比如在金融风控中,误判一个正常用户为欺诈用户(FP)和漏掉一个真正的欺诈用户(FN)所带来的损失是不同的,而 AUC 对这两者一视同仁。
此外,AUC 对数据分布变化较为敏感。如果测试集的类别分布与训练集存在显著差异,AUC 的表现可能会失真,不能真实反映模型的泛化能力。
因此,在使用 AUC 作为模型评估指标时,应结合具体任务目标和其他评价指标(如精确率、召回率、F1 分数、准确率等)进行综合判断,才能更全面地评估模型的实际效果。

5. SGD、Adam、RMSprop 等优化器之间有什么区别?各自适用于哪些场景?
SGD(随机梯度下降)是最基础的优化算法,它每次根据一个样本或小批量数据计算梯度并更新参数。虽然简单,但收敛速度较慢,尤其在复杂或非凸问题中容易震荡。不过,通过加入动量项可以显著提升其表现,因此SGD with Momentum仍然被广泛用于需要精细控制训练过程的场景,例如追求模型泛化能力的图像任务。
RMSprop 是一种自适应学习率优化器,它通过维护每个参数的历史梯度平方的移动平均来自动调整学习率,从而缓解学习过程中梯度变化剧烈的问题。这种机制使其特别适合处理如RNN这类梯度稀疏或波动大的任务,在NLP领域有较好表现。
Adam 结合了动量法和RMSprop的优点,不仅维护了一阶矩(梯度均值),还维护了二阶矩(梯度平方的均值),并通过偏差校正提高初期稳定性。它通常具有更快的收敛速度和良好的鲁棒性,适用于大多数深度学习任务,是当前最常用的默认优化器之一。对于图像识别、Transformer模型、GAN等任务,Adam通常是首选。
总体来说,如果希望快速上手并获得稳定效果,推荐使用 Adam;若更关注模型最终性能,尤其是在图像分类任务中,可以尝试 SGD + 学习率调度策略;而对于RNN、语言模型等梯度不稳定的情况,RMSprop 和 Adam 都是不错的选择。
SGD、Adam 和 RMSprop 是深度学习中常用的优化器,它们在参数更新方式、收敛速度、适应性等方面有显著区别。以下是它们的核心差异以及各自适用的场景:
SGD(Stochastic Gradient Descent)随机梯度下降
-
原理:每次使用一个样本(或小批量数据)计算梯度并更新参数。
-
公式:
其中, 是学习率, 是当前批次的梯度。
-
改进版本:SGD with Momentum(动量法),引入动量项加速收敛方向:
RMSprop(Root Mean Square Propagation)
-
提出者:Geoff Hinton 提出。
-
原理:对每个参数使用不同的自适应学习率,根据历史梯度平方的移动平均来调整学习率。
-
公式:
其中 是衰减系数(通常设为0.9), 防止除以零。
Adam(Adaptive Moment Estimation)
-
结合了 Momentum 和 RMSprop 的优点。
-
原理:维护一阶矩估计(均值)和二阶矩估计(未中心化的方差),进行偏差修正后用于参数更新。
-
公式:
-
默认超参数:
6. 语义分割模型的输出 shape
语义分割模型的输出 shape 通常是
(N, C, H, W),其中C是类别数,后续通过 softmax 或 argmax 得到每个像素的预测类别。
7. 语义分割任务中有哪些损失函数?
https://www.dong-blog.fun/post/2103
8. RNN LSTM
循环神经网络(Recurrent Neural Network, RNN)是一种专门处理序列数据(如时间序列、文本、语音等)的神经网络。
每个时间步的计算公式为:
其中:
- :当前时刻的隐藏状态(记忆)
- :当前时刻的输入
- :当前时刻的输出
- :可学习参数
- :激活函数(如 tanh 或 ReLU)
- 共享参数:所有时间步共享相同的权重矩阵 ,减少了参数数量。
- 序列建模:通过隐藏状态传递信息,能够捕捉序列中的长期依赖(理论上)。
- 变长输入/输出:支持不同长度的序列输入和输出。
LSTM(Long Short-Term Memory)
- 引入门控机制(Gating Mechanism)控制信息流动:
- 遗忘门:决定丢弃哪些历史信息。
- 输入门:决定当前输入的信息如何更新记忆。
- 输出门:决定当前时刻的输出。
- 核心公式:
GRU(Gated Recurrent Unit)
-
简化 LSTM 的结构,合并遗忘门和输入门为更新门(Update Gate),并引入重置门(Reset Gate)。
-
计算更高效,效果接近 LSTM。
-
核心公式:
其中:
- : 更新门(Update Gate)
- : 重置门(Reset Gate)
- : 候选隐藏状态(Candidate Hidden State)
- : 最终隐藏状态(Final Hidden State)
- : Sigmoid 激活函数
- : 逐元素乘法(Hadamard Product)
双向 RNN(Bidirectional RNN)
- 同时建模过去和未来的信息,适用于需要上下文理解的任务(如机器翻译)。
深度 RNN(Deep RNN)
- 堆叠多层 RNN,增强模型表达能力。
决策树知识点
https://www.dong-blog.fun/post/482
三种类型决策树。
ID3决策树,可以做分类任务,靠信息增益进行构建树。
C4.5决策树,改进了ID3决策树,也可以做分类任务,靠信息增益率进行构建树(除了要考虑特征有多能分,还要考虑特征的贡献占比)。
CART (Classification and Regression Trees),可以做分类和回归,分类用基尼指数,回归用均方误差(MSE)。
SVM知识点
https://www.dong-blog.fun/post/2110
超平面方程、约束条件、软间隔、核技巧、对偶问题(Dual Problem)与拉格朗日乘子
贝叶斯分类器知识点
https://www.dong-blog.fun/post/1450
https://www.dong-blog.fun/post/1453
执果索因。
Transformer 的组成
https://www.dong-blog.fun/post/478
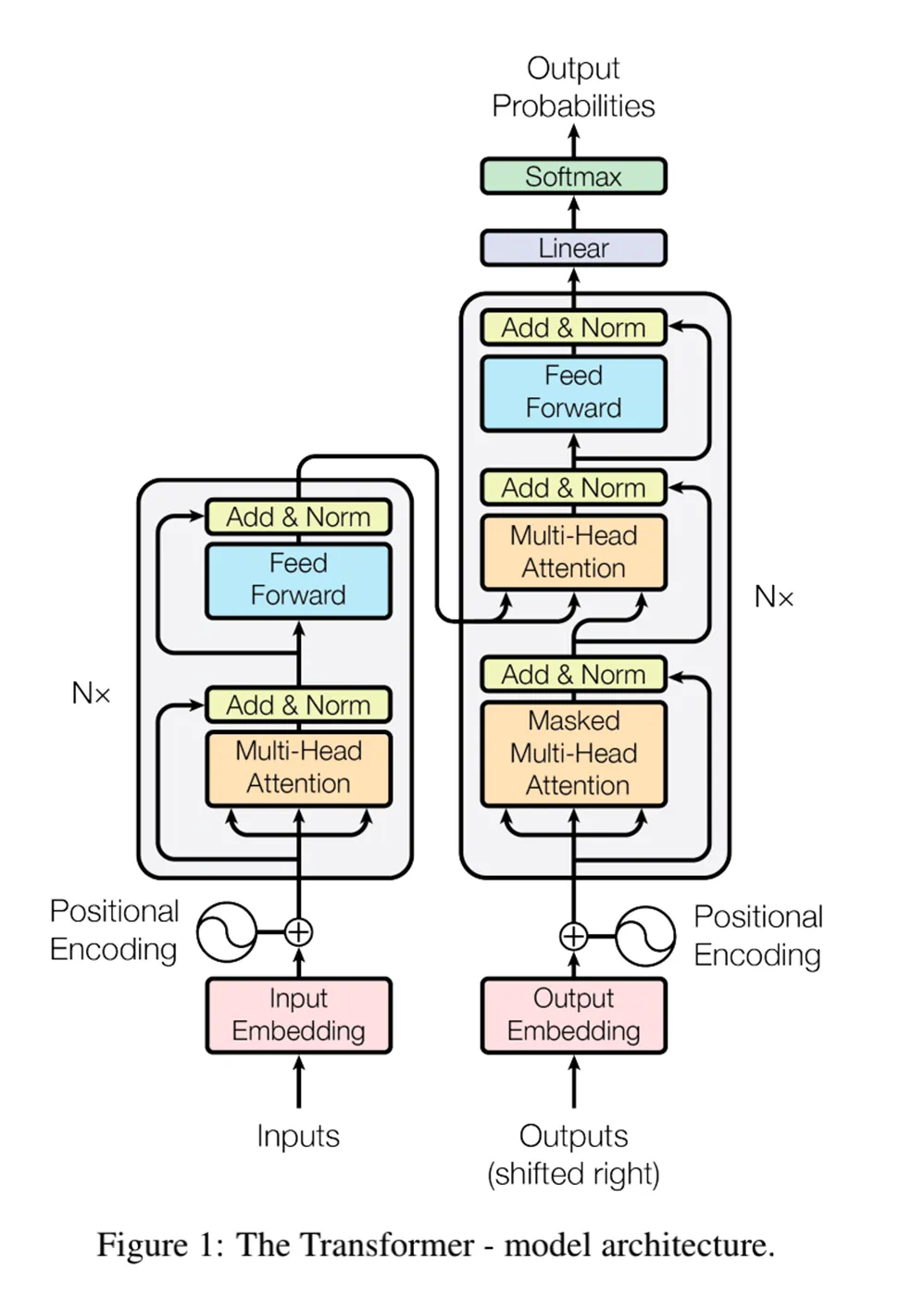
输入嵌入和位置编码
注意力机制
残差连接和层归一化
前馈神经网络(FFN)
残差连接和层归一化
什么是自编码器?什么是变分自编码器?
https://www.dong-blog.fun/post/575
可以用于数据压缩。输入信息被编码器压缩为特征,然后被解码器解码为原数据。
损失函数一般是两个部分:重构损失(Reconstruction Loss)、KL散度(Kullback-Leibler Divergence):确保编码器生成的潜在变量分布接近标准正态分布。
很有意思的一点假设:假设潜在变量 z 服从先验分布(通常为标准正态分布 N(0,I))。编码器输出的分布需接近该先验,以保证潜在空间的连续性和可解释性。
"变分"一词来源于变分法,这是一种用于找到函数极值的方法。
变分自编码器和自编码器什么区别?
-
编码方式 自编码器的编码器输出是一个固定数值的潜在编码 (如向量或张量),而变分自编码器的编码器输出是潜在变量的概率分布参数 (如均值和方差)。VAE通过引入随机性,将编码过程视为从概率分布中采样的过程,从而生成更具泛化能力的潜在表示
-
潜在空间特性 传统自编码器学习的是离散的潜在空间模型 ,而变分自编码器通过概率建模学习连续的潜在变量分布 。这种连续性使得VAE能够更灵活地生成新样本,并支持在潜在空间中进行插值等操作
-
目标与数学表述 自编码器的目标是通过重构损失(如均方误差)尽可能还原输入数据,而VAE的目标是最大化数据的对数似然下界(ELBO),其损失函数包含两部分:重构损失和KL散度(用于约束潜在变量的分布接近先验分布,如标准正态分布)
-
应用差异 自编码器主要用于特征提取、降维或数据压缩 ,而变分自编码器作为生成模型,能够生成与训练数据分布相似的新样本 ,例如生成图像或文本
GAN的相关问题
组成
生成器(Generator) :负责生成与真实数据分布相似的样本(如图像、文本等),目标是让生成的数据尽可能逼真以“欺骗”判别器。
判别器(Discriminator) :充当“裁判”角色,判断输入数据是来自真实数据集还是生成器生成的假数据。
GAN的常用的损失函数有哪些?
https://www.dong-blog.fun/post/2111
Pix2Pix PatchGAN 判别器
https://www.dong-blog.fun/post/1923
**CycleGAN 循环一致性损失
https://www.dong-blog.fun/post/1926
YOLOv5 的相关问题
https://www.dong-blog.fun/post/297
https://www.dong-blog.fun/post/274
YOLOv5的损失函数由三部分组成:定位损失(采用CIoU Loss,综合中心点距离、长宽比和IoU的优化)、置信度损失(二元交叉熵,区分目标和背景)以及分类损失(带标签平滑的多类别交叉熵)。三者通过自适应权重平衡(如分类损失默认权重0.5)。输入图像通过自适应缩放(保持长宽比填充至640×640等可选尺寸)而非简单拉伸,并归一化到0-1范围,数据增强策略包括Mosaic(四图拼接)和Albumentations库的随机变换。
输出处理上,YOLOv5采用多尺度预测(P3-P5或P3-P7特征图),每个网格预设锚框通过k-means聚类数据集生成。边界框坐标通过sigmoid约束到网格内(避免偏移溢出),宽高基于锚框的指数变换实现相对预测。后处理时,加权NMS(如合并重叠框的置信度加权平均)替代传统NMS,输出格式为(x, y, w, h, confidence, class),其中坐标已转换回原图尺度。此外,YOLOv5通过自动混合精度训练和跨阶段局部网络(CSPNet)进一步提升效率,实现较YOLOv4更快的推理速度。
Faster-RCNN
https://www.dong-blog.fun/post/242
ROI Pooling 和 ROI Align
https://www.dong-blog.fun/post/260
Mask R-CNN
https://www.dong-blog.fun/post/2121
U-Net/HRNet 区别


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!