目录
一篇很好的解读: https://zhuanlan.zhihu.com/p/20844750193
GRPO:基于群组相对优化的强化学习算法
1. GRPO概述
GRPO (Group Relative Policy Optimization) 是一种用于大型语言模型(LLM)和视觉语言模型(VLM)训练的强化学习算法。它是一种相对优势计算方法,通过对同一输入生成多个输出回答,然后计算相对优势进行优化。
相比于传统的PPO等算法,GRPO的主要特点是:
- 不需要价值网络(Value Network),简化了训练过程
- 通过相对评估减少了回报的高方差问题
- 特别适合处理离散奖励信号,如问答场景中的正确/错误奖励
- 对同样的问题采样多次,通过组内相对比较学习更好的策略
2. GRPO的核心组件
GRPO算法的核心组件包括:
2.1 Actor模型
Actor模型(其实就是策略模型,就是要训练的那个模型)负责执行策略(Policy),即基于给定输入生成输出。在EasyR1框架中,这通常是一个预训练的大型语言模型或视觉语言模型,如Qwen2.5-VL。
2.2 Rollout引擎
Rollout引擎负责生成多个候选回答。在GRPO中,rollout.n > 1是必须的,因为算法依赖于对同一个问题生成多个不同的回答来计算相对优势。
2.3 奖励函数
奖励函数评估生成回答的质量,返回一个标量奖励值。在EasyR1中,奖励函数可以由多个组件构成,例如:
- 格式奖励:评估回答格式是否正确
- 思考质量:评估模型思考过程质量
- 回答格式:评估回答结构是否合适
- 准确性:评估回答是否正确
2.4 优势计算器
优势计算器计算每个动作(token)的优势值,这是GRPO的核心所在。
3. GRPO的数学原理与公式
3.1 基本公式
GRPO的核心在于如何计算优势函数(Advantage)。在标准的强化学习中,优势函数定义为:
其中,是状态-动作值函数,是状态值函数。
但GRPO不使用价值网络,而是利用群组相对比较计算优势。具体公式如下:
3.2 GRPO优势计算公式
对于同一输入问题的多个生成回答,GRPO计算优势的方法是:
其中:
- 是当前回答的累积奖励
- 是同一问题所有回答的平均奖励
- 是同一问题所有回答奖励的标准差
- 是一个小常数,防止除零错误
这个优势计算本质上是对奖励进行了标准化,使得同一问题的不同回答可以相互比较。
代码实现:
python展开代码scores = token_level_rewards.sum(dim=-1) # 计算每个回答的总分
id2score = defaultdict(list)
id2mean, id2std = {}, {}
# 收集同一问题的所有回答分数
bsz = scores.shape[0]
for i in range(bsz):
id2score[index[i]].append(scores[i])
# 计算每个问题的平均分和标准差
for idx in id2score:
assert len(id2score[idx]) > 1, "GRPO needs rollout.n > 1."
id2mean[idx] = torch.mean(torch.tensor(id2score[idx]))
id2std[idx] = torch.std(torch.tensor(id2score[idx]))
# 计算每个回答的标准化分数(优势)
for i in range(bsz):
scores[i] = (scores[i] - id2mean[index[i]]) / (id2std[index[i]] + eps)
3.3 策略优化目标
有了优势函数后,GRPO的策略优化目标是最大化:
这个公式与PPO的目标函数相似,但使用了GRPO计算的优势函数。
在实现中,EasyR1使用了更复杂的双侧裁剪技术(Dual-clip PPO),进一步提高了训练稳定性:
python展开代码negative_approx_kl = log_probs - old_log_probs
ratio = torch.exp(negative_approx_kl)
clipped_ratio = torch.exp(
torch.clamp(negative_approx_kl, np.log(1.0 - clip_ratio_low), np.log(1.0 + clip_ratio_high))
)
pg_loss = -advantages * ratio
pg_loss2 = -advantages * clipped_ratio
pg_loss3 = -advantages * clip_ratio_dual
clipped_pg_loss_higher = torch.max(pg_loss, pg_loss2) # 上方裁剪
pg_clipfrac_higher = (pg_loss < pg_loss2).float()
clipped_pg_loss_lower = torch.min(clipped_pg_loss_higher, pg_loss3) # 下方裁剪
final_pg_loss = torch.where(advantages < 0, clipped_pg_loss_lower, clipped_pg_loss_higher)
4. GRPO的工作流程
GRPO算法的工作流程如下:
-
经验收集:
- 对每个输入问题,使用当前策略生成n个不同的回答
- 计算每个回答的奖励
-
优势计算:
- 对于每个问题,计算所有回答的平均奖励和标准差
- 使用标准化公式计算每个回答的优势
-
策略优化:
- 使用计算的优势,应用PPO风格的裁剪策略梯度更新策略模型
- 通过KL散度正则化控制策略更新幅度,防止过度更新
-
重复迭代:
- 重复以上步骤多个epoch,直到模型性能收敛
5. GRPO在EasyR1中的配置
在EasyR1框架中,GRPO可以通过以下配置启用:
yaml展开代码algorithm:
adv_estimator: grpo # 使用GRPO优势估计器
kl_penalty: low_var_kl # KL散度惩罚类型
kl_coef: 1.0e-2 # KL散度系数
worker:
rollout:
n: 5 # 每个问题生成5个候选回答
重要配置参数解释:
adv_estimator: 设置为"grpo"启用GRPO算法rollout.n: 必须大于1,表示每个问题生成的候选回答数量kl_coef: 控制策略更新幅度的KL散度系数
6. GRPO与其他强化学习算法的比较
EasyR1框架支持多种强化学习算法:
| 算法 | 特点 | 适用场景 |
|---|---|---|
| GRPO | 无需价值网络,使用群组相对计算优势 | 离散奖励信号,如问答准确性 |
| Reinforce++ | 基于返回轨迹的优势计算 | 需要考虑时序奖励的场景 |
| ReMax | 使用预定义基线计算优势 | 有明确基线的场景 |
| RLOO | 留一法计算基线 | 样本量较小的场景 |
GRPO的主要优势是计算简单,不需要价值网络,特别适合处理离散的奖励信号,如问答场景中的正确/错误判断。
7. 示意图
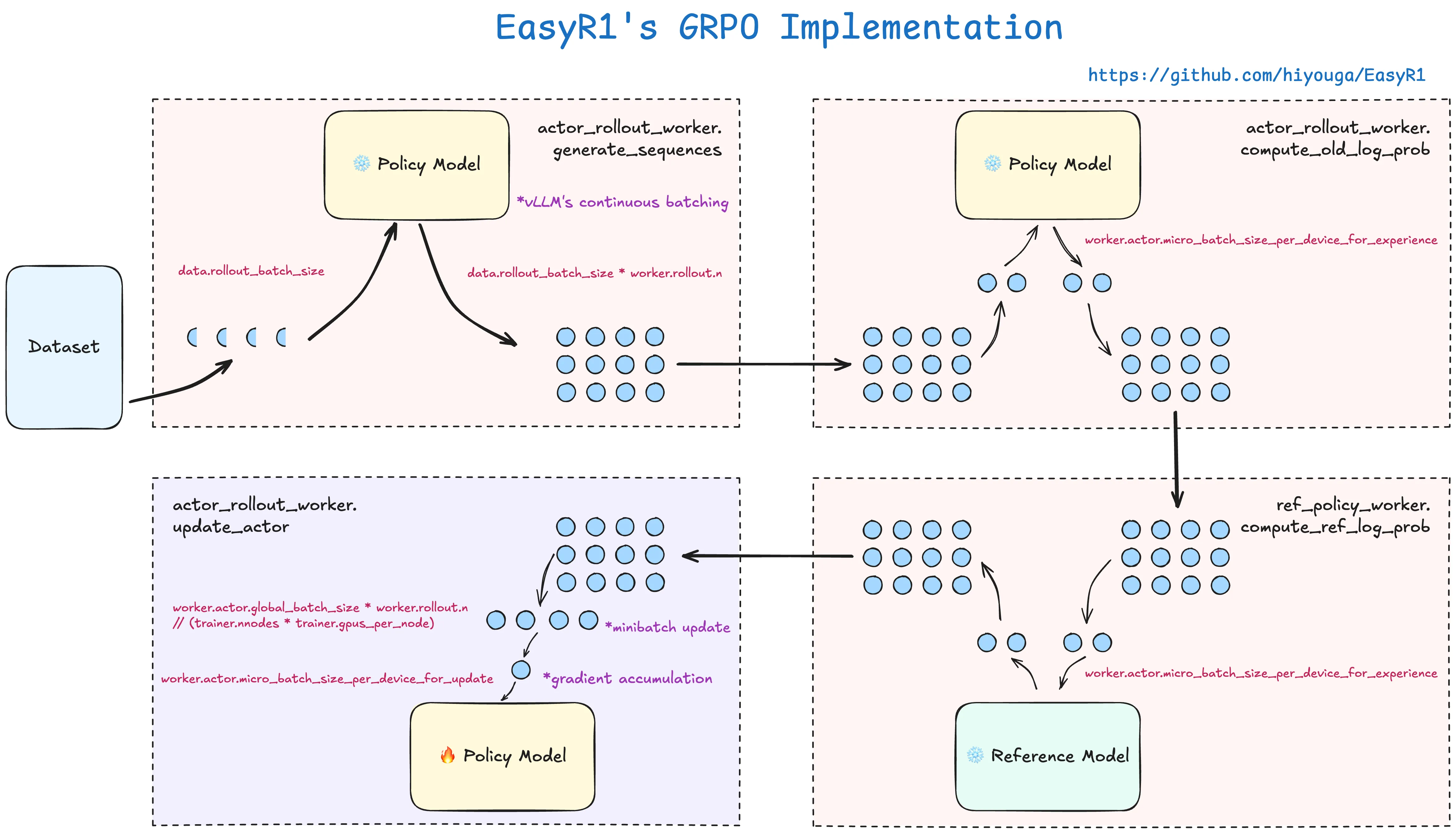
(1)Dataset(左侧) : 提供训练数据(如 rollout_batch_size 表示每次从环境中采样的数据量)。
◦ worker.rollout.n:每个工作节点(worker)的采样次数。
◦ global_batch_size = rollout_batch_size * worker.rollout.n:全局批次大小。 这个在config配置里是很重要的参数。
(2)左上侧 Policy Model :处理原始数据,生成动作(actor_arrow)和计算旧策略的对数概率(old_log_prob)。
◦ 通过 worker 和 actor 协作生成数据。
◦ 输出传递给右侧 Policy Model。
◦ 使用了 vLLM's continuous batching 技术,优化了连续批次处理。参数是冻结的。
(3)右上侧 Policy Model :进一步计算策略更新所需的参数(如梯度)。
◦ 这里的参数是 worker.actor.micro_batch_size_per_device_for_experience 。
(4)Reference Model : 计算参考策略的对数概率(ref_log_prob),用于评估策略更新的安全性(如避免过大的策略变化)。
◦ 这里的参数也是 worker.actor.micro_batch_size_per_device_for_experience 。
(5)左下侧 Policy Model :更新梯度。
◦ 注意参数 minibatch update ,是以这个数字进行批量更新。同时也要注意 gradient accumulation 这个梯度累计参数,累积完了才更新。
展开代码worker.actor.global_batch_size * worker.rollout.n // (trainer.nnodes * trainer.gpus_per_node)
8. 总结
GRPO是一种高效的强化学习算法,通过群组相对比较计算优势,不需要额外的价值网络,简化了大型语言模型和视觉语言模型的训练过程。在EasyR1框架中,GRPO已被证明在各种视觉-语言任务上表现优异,如几何问题解答、数学推理等。
其核心思想是通过比较同一问题下不同回答的相对表现来学习,而不是与固定的基线比较,这使得训练更加稳定和高效。GRPO算法的相对优势计算公式是其最关键的创新点,通过这种方式,模型能够学会更好地区分高质量和低质量的回答。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!