一篇很好的DeepSeek R1 解读: https://zhuanlan.zhihu.com/p/20844750193
DeepSeek R1 论文: https://arxiv.org/abs/2501.12948
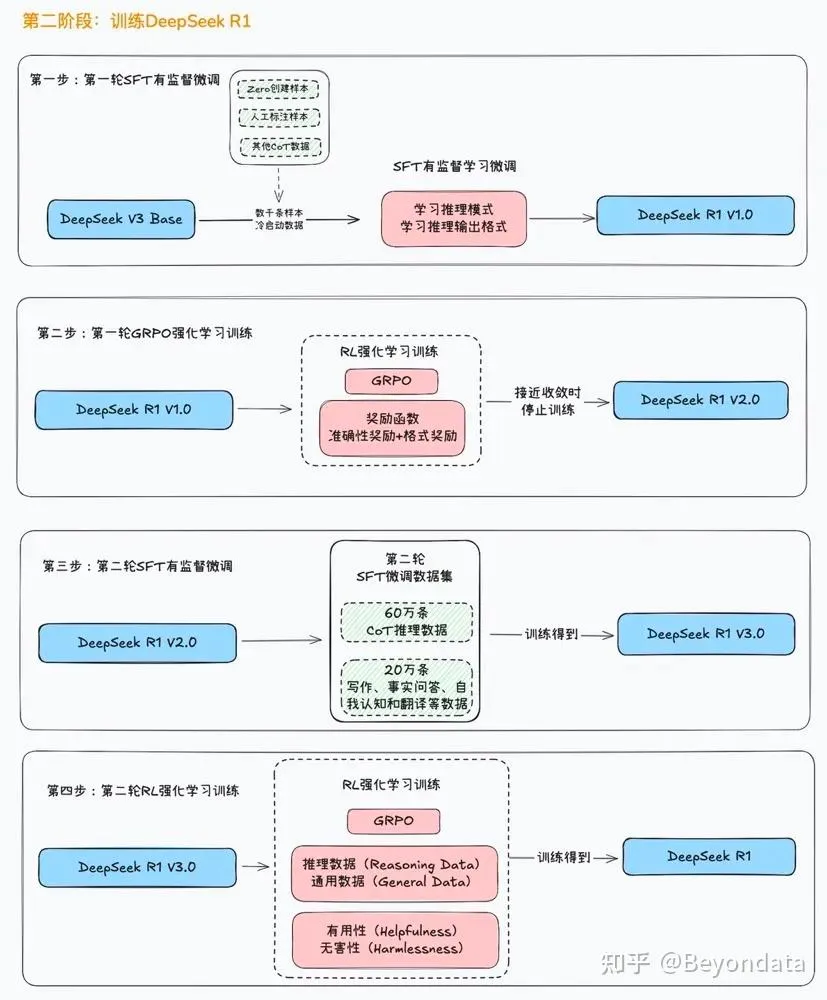
如何从DeepSeek-V3-Base得到DeepSeek-R1-Zero,可以看下面这图。编写一个指导性的提示词,让DeepSeek-V3-Base输出一组回答,用奖励模型进行奖励RL训练,这样就可以训练出DeepSeek-R1-Zero。
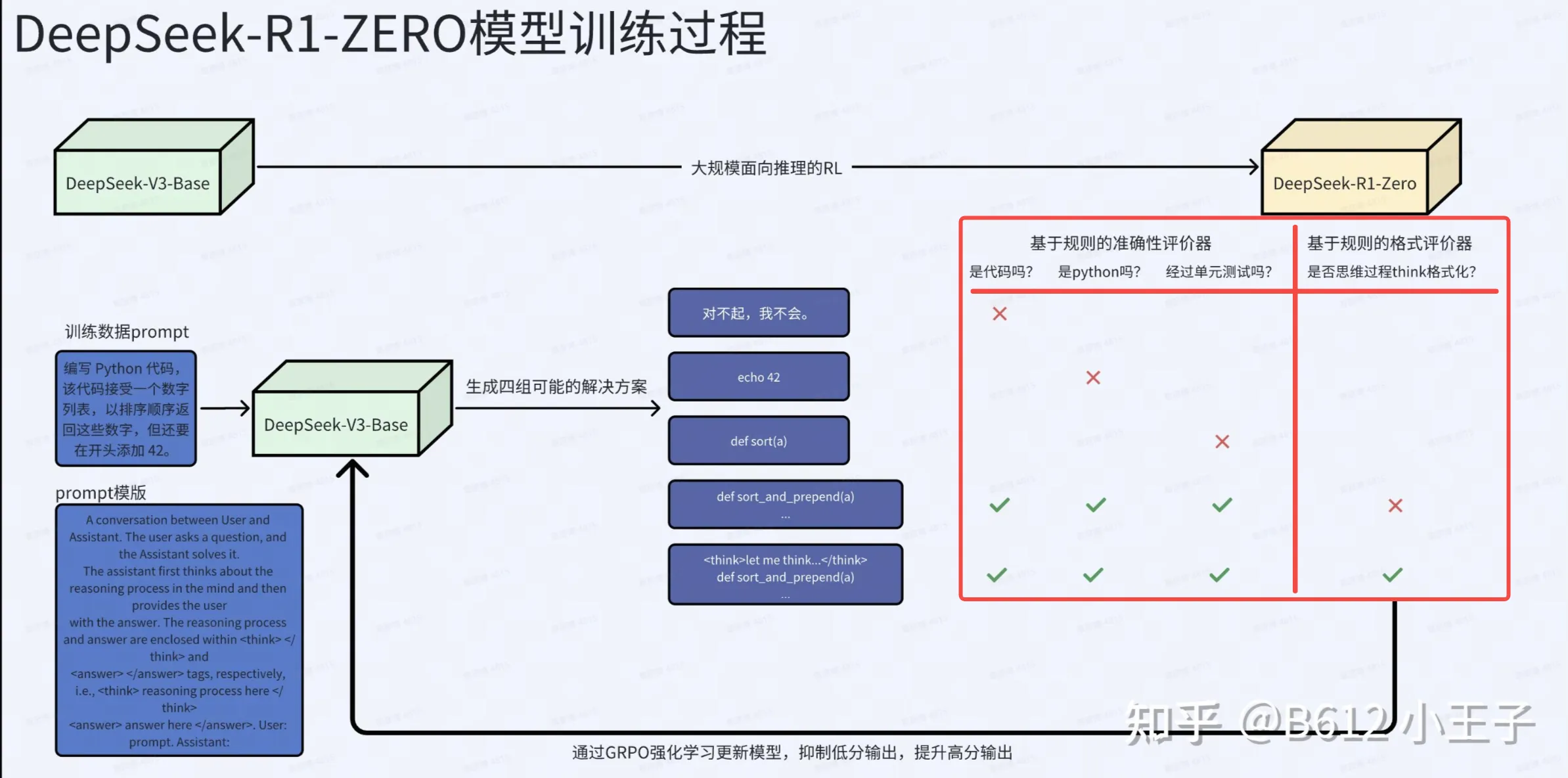
群组相对策略优化:
为了降低强化学习(RL)的训练成本,我们采用了群组相对策略优化(Group Relative Policy Optimization, GRPO)(Shao 等,2024)。GRPO 放弃了通常与策略模型规模相当的批评模型(critic model),而是通过群组得分来估计基线值。具体而言,对于每个问题 q,GRPO 从旧策略 πθold 中采样一组输出 {o1,o2,⋯,oG},然后通过最大化以下目标函数来优化策略模型 πθ:
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),
其中,DKL(πθ∣∣πref) 表示 KL 散度,定义为:
DKL(πθ∣∣πref)=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1,
ε 和 β 是超参数,Ai 是优势函数,通过一组奖励 {r1,r2,…,rG} 计算得出,这些奖励对应于每个群组内的输出:
Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG}).
解释
-
核心思想:
- GRPO 的核心是通过群组得分来估计基线值,而不是使用传统的批评模型(critic model)。这种方法可以显著减少计算开销。
- GRPO 通过对旧策略采样的一组输出进行评估,并结合优势函数 Ai 来更新策略模型。
-
目标函数:
- 目标函数由两部分组成:
- 第一部分是一个加权的优势函数,权重是新策略和旧策略的概率比值(重要性采样比率)。
- 第二部分是一个惩罚项,用于限制新策略和参考策略之间的 KL 散度,确保策略更新不会过于剧烈。
-
优势函数:
- 优势函数 Ai 衡量了某个输出 oi 的奖励相对于群组内平均奖励的表现。通过标准化(减去均值并除以标准差),优势函数能够更好地反映相对性能。
-
KL 散度:
- KL 散度用于衡量新策略 πθ 和参考策略 πref 之间的差异。通过引入惩罚项,可以避免策略更新偏离参考策略过远。
-
超参数:
- ε 控制重要性采样比率的裁剪范围,防止过大的更新步长。
- β 控制 KL 散度惩罚的强度,平衡探索与利用。
这种方法在理论上能够有效降低 RL 训练的成本,同时保持策略优化的稳定性和高效性。
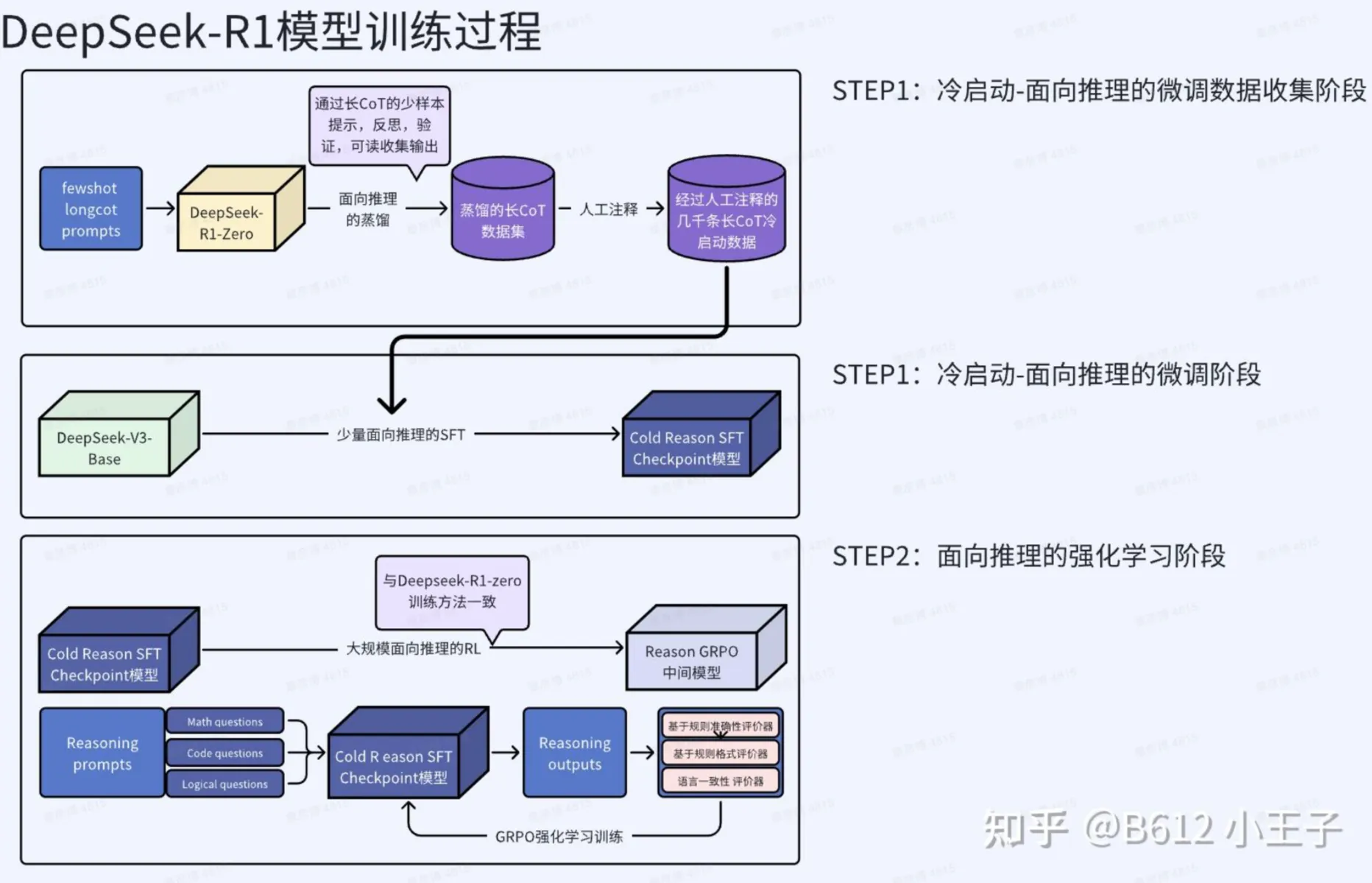
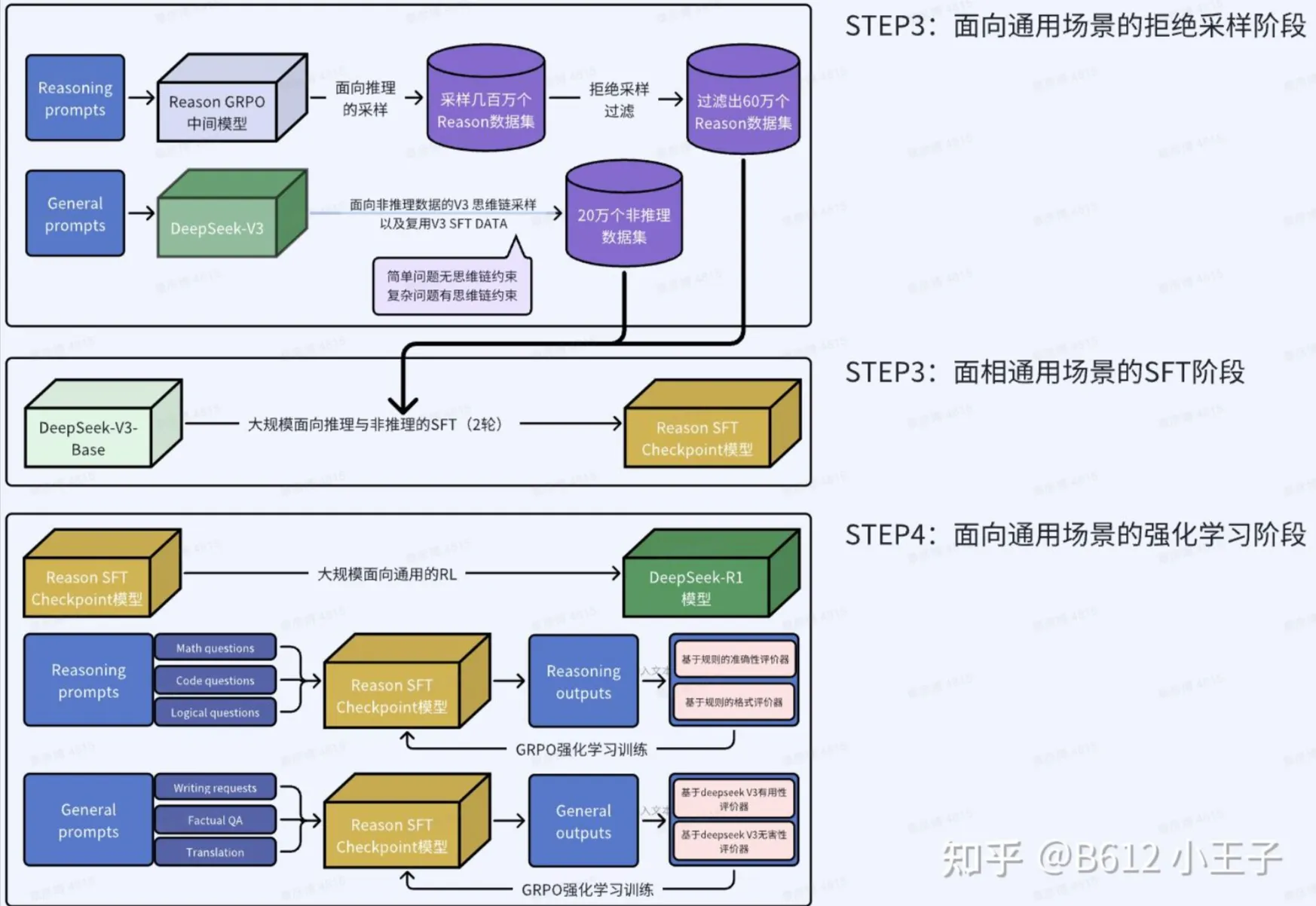
或者看这个图: