目录
如何拆分Flux变换器并进行推理?
作者:Sayak Paul
扩散系统不是单一的整体模型,而是一系列相互连接的模型。例如,Stable Diffusion系列模型(及类似的模型)包含一个文本编码器、一个去噪器和一个VAE(变分自编码器)。还有一个非参数组件——噪声调度器。
现代扩散系统,如Flux,涉及多个文本编码器,一个作为去噪器的大型扩散变换器,最后是一个VAE。显然,使用这样的系统进行推理在消费者级GPU上是一个令人头疼的任务。
本文将展示如何解耦扩散系统的不同阶段(文本编码、去噪和解码),并在可用时将其计算拆分到多个(消费者级)GPU上。这里假设我们有两个16GB的GPU。
我们的测试平台是Flux.1-Dev 模型。该模型包含:
- 两个文本编码器:
- T5-xxl
- CLIP-L
- 一个扩散变换器(具有12.5B参数)
- 一个VAE
如果我们拥有两个16GB的GPU,那么我们无法直接进行推理。我们必须使用某种量化技术或其他模型拆分技巧。本文将采用后者。
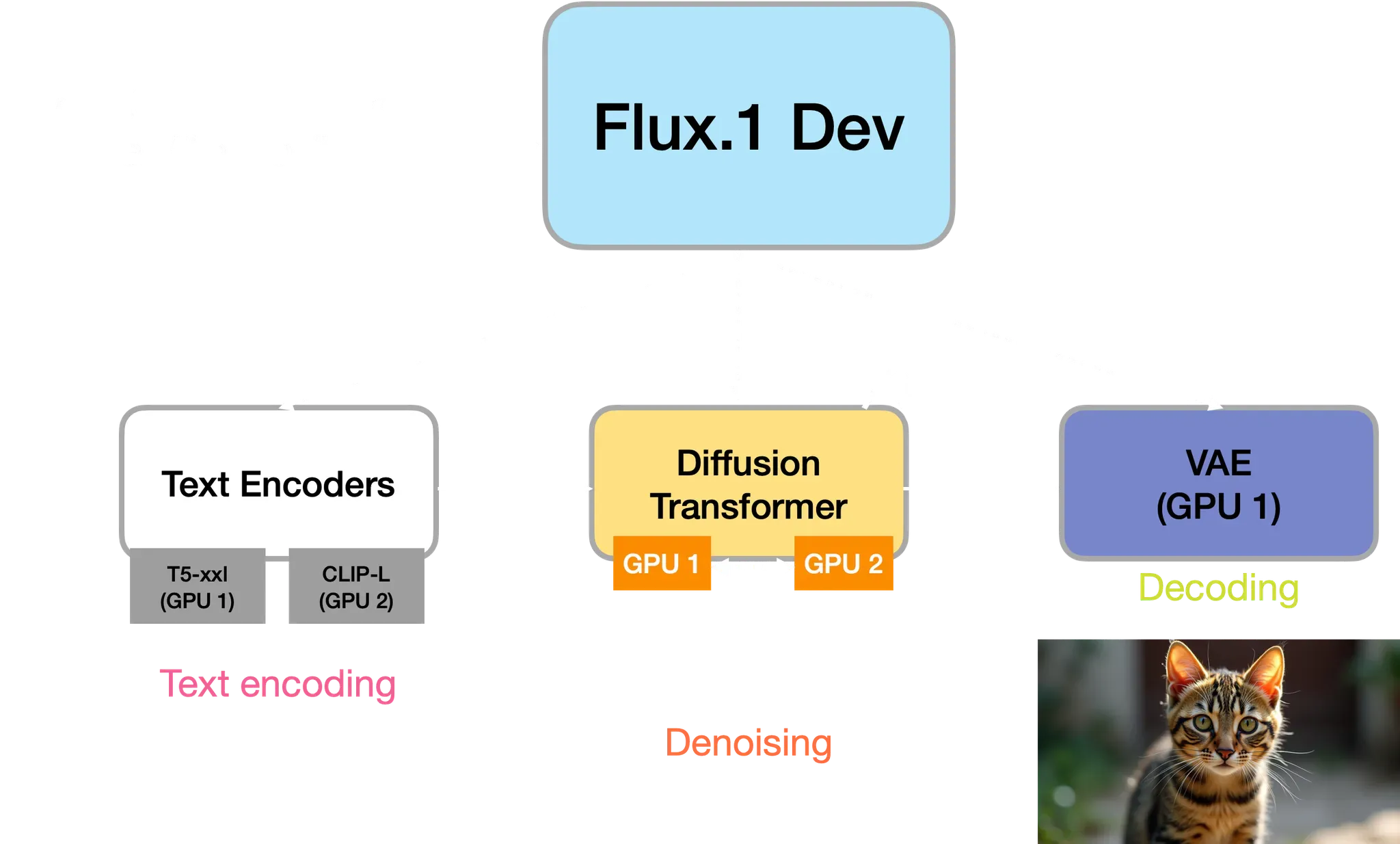
文本编码
给定输入文本提示,我们首先计算文本嵌入。为此,我们只需要两个文本编码器和它们各自的分词器。我们将这两个文本编码器分别保存在两个GPU上。以下是实现代码:
python展开代码from diffusers import FluxPipeline
import torch
ckpt_id = "black-forest-labs/FLUX.1-dev"
prompt = "a photo of a dog with cat-like look"
pipeline = FluxPipeline.from_pretrained(
ckpt_id,
transformer=None,
vae=None,
device_map="balanced",
max_memory={0: "16GB", 1: "16GB"},
torch_dtype=torch.bfloat16
)
with torch.no_grad():
print("Encoding prompts.")
prompt_embeds, pooled_prompt_embeds, text_ids = pipeline.encode_prompt(
prompt=prompt, prompt_2=None, max_sequence_length=512
)
去噪
一旦文本嵌入计算完成,我们可以释放文本编码器并释放GPU内存来加载扩散变换器。如前所述,扩散变换器有12.5B参数,是目前可用的最大的开放扩散变换器。即使使用如BFloat16这样降低精度的方法,我们也无法将其完全加载到16GB的显存中。因此,我们将把它拆分到两个16GB的GPU上。
首先,我们使用device_map="auto"加载变换器,让accelerate自动决定如何最佳地将模型拆分到GPU、CPU和磁盘上。尽管如此,我们仍希望尽量减少CPU和磁盘之间的数据移动。
python展开代码from diffusers import FluxTransformer2DModel
import torch
transformer = FluxTransformer2DModel.from_pretrained(
ckpt_id,
subfolder="transformer",
device_map="auto",
max_memory={0: "16GB", 1: "16GB"},
torch_dtype=torch.bfloat16
)
如果我们从上面的代码中打印 transformer.hf_device_map,它将显示 transformer 每个模块在设备上的拆分情况。
接下来,我们可以将 transformer 集成到去噪过程中。我们加载 FluxPipeline 并传入我们之前加载的 transformer,但是将其他模型级组件(如文本编码器和VAE)设置为 None。
python展开代码pipeline = FluxPipeline.from_pretrained(
ckpt_id,
text_encoder=None,
text_encoder_2=None,
tokenizer=None,
tokenizer_2=None,
vae=None,
transformer=transformer,
torch_dtype=torch.bfloat16
)
print("Running denoising.")
height, width = 768, 1360
# No need to wrap it up under `torch.no_grad()` as pipeline call method
# is already wrapped under that.
latents = pipeline(
prompt_embeds=prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
num_inference_steps=50,
guidance_scale=3.5,
height=height,
width=width,
output_type="latent",
).images
解码并获取最终图像
这是图像生成过程的最后阶段,我们需要解码从前一阶段计算得到的潜在变量(latents)。由于VAE(变分自编码器)通常比较小,因此我们可以将其加载到单个16GB的GPU上进行处理。
python展开代码from diffusers import AutoencoderKL
from diffusers.image_processor import VaeImageProcessor
import torch
vae = AutoencoderKL.from_pretrained(ckpt_id, subfolder="vae", torch_dtype=torch.bfloat16).to("cuda")
vae_scale_factor = 2 ** (len(vae.config.block_out_channels))
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)
with torch.no_grad():
print("Running decoding.")
latents = FluxPipeline._unpack_latents(latents, height, width, vae_scale_factor)
latents = (latents / vae.config.scaling_factor) + vae.config.shift_factor
image = vae.decode(latents, return_dict=False)[0]
image = image_processor.postprocess(image, output_type="pil")
image[0].save("split_transformer.png")
完整代码片段
python展开代码from diffusers import FluxPipeline, AutoencoderKL, FluxTransformer2DModel
from diffusers.image_processor import VaeImageProcessor
import torch
import gc
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_max_memory_allocated()
torch.cuda.reset_peak_memory_stats()
ckpt_id = "black-forest-labs/FLUX.1-dev"
prompt = "a photo of a dog with cat-like look"
pipeline = FluxPipeline.from_pretrained(
ckpt_id,
transformer=None,
vae=None,
device_map="balanced",
max_memory={0: "16GB", 1: "16GB"},
torch_dtype=torch.bfloat16
)
print(pipeline.hf_device_map)
with torch.no_grad():
print("Encoding prompts.")
prompt_embeds, pooled_prompt_embeds, text_ids = pipeline.encode_prompt(
prompt=prompt, prompt_2=None, max_sequence_length=512
)
print(prompt_embeds.shape)
del pipeline.text_encoder
del pipeline.text_encoder_2
del pipeline.tokenizer
del pipeline.tokenizer_2
del pipeline
flush()
transformer = FluxTransformer2DModel.from_pretrained(
ckpt_id,
subfolder="transformer",
device_map="auto",
max_memory={0: "16GB", 1: "16GB"},
torch_dtype=torch.bfloat16
)
print(transformer.hf_device_map)
pipeline = FluxPipeline.from_pretrained(
ckpt_id,
text_encoder=None,
text_encoder_2=None,
tokenizer=None,
tokenizer_2=None,
vae=None,
transformer=transformer,
torch_dtype=torch.bfloat16
)
print("Running denoising.")
height, width = 768, 1360
# No need to wrap it up under `torch.no_grad()` as pipeline call method
# is already wrapped under that.
latents = pipeline(
prompt_embeds=prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
num_inference_steps=50,
guidance_scale=3.5,
height=height,
width=width,
output_type="latent",
).images
print(latents.shape)
del pipeline.transformer
del pipeline
flush()
vae = AutoencoderKL.from_pretrained(ckpt_id, subfolder="vae", torch_dtype=torch.bfloat16).to("cuda")
vae_scale_factor = 2 ** (len(vae.config.block_out_channels))
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)
with torch.no_grad():
print("Running decoding.")
latents = FluxPipeline._unpack_latents(latents, height, width, vae_scale_factor)
latents = (latents / vae.config.scaling_factor) + vae.config.shift_factor
image = vae.decode(latents, return_dict=False)[0]
image = image_processor.postprocess(image, output_type="pil")
image[0].save("split_transformer.png")


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!