目录
索引向量字段
本指南将引导您完成在集合中创建和管理向量字段索引的基本操作。
概述
Milvus利用存储在索引文件中的元数据,将数据组织成一种专门的结构,从而在搜索或查询时加速所请求信息的检索。
Milvus提供了多种索引类型和度量标准,用于对字段值进行排序,以实现高效的相似性搜索。下表列出了支持的索引类型和度量标准,适用于不同的向量字段类型。目前,Milvus支持多种类型的向量数据,包括浮点嵌入(通常称为浮点向量或密集向量)、二进制嵌入(也称为二进制向量)和稀疏嵌入(也称为稀疏向量)。有关详细信息,请参阅内存索引和相似性度量。

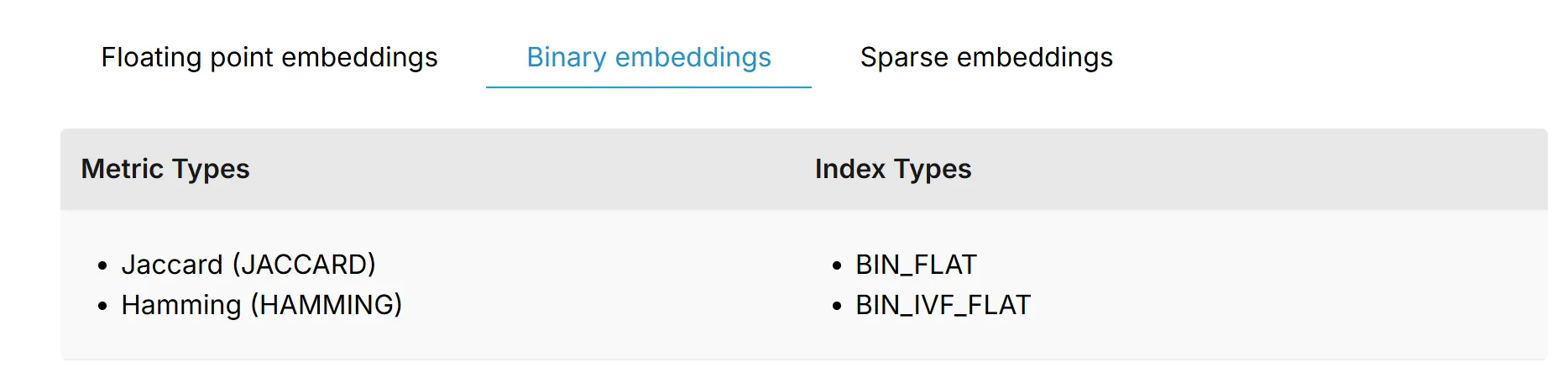
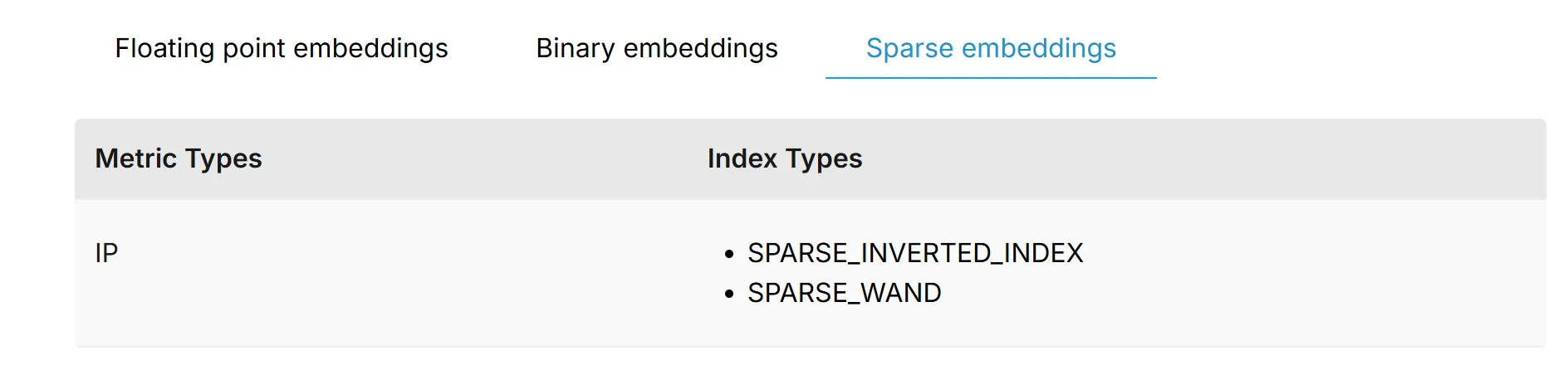
建议为频繁访问的向量字段和标量字段创建索引。
准备工作
如在“管理集合”中所述,如果在创建集合时指定以下任何条件,Milvus将自动生成索引并将其加载到内存中:
- 向量字段的维度和度量类型,或
- 模式和索引参数。
以下代码片段通过现有代码连接到Milvus实例,并创建一个集合而不指定索引参数。在这种情况下,集合没有索引,并且尚未加载。
为了准备索引,使用MilvusClient连接到Milvus服务器,并通过create_schema()、add_field()和create_collection()设置集合。
python展开代码from pymilvus import MilvusClient, DataType
# 1. 设置Milvus客户端
client = MilvusClient(
uri="http://localhost:19530"
)
# 2. 创建模式
# 2.1. 创建模式
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
# 2.2. 向模式中添加字段
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
# 3. 创建集合
client.create_collection(
collection_name="customized_setup",
schema=schema,
)
索引集合
要为集合创建索引或为集合建立索引,使用prepare_index_params()准备索引参数,并使用create_index()创建索引。
python展开代码# 4.1. 设置索引参数
index_params = MilvusClient.prepare_index_params()
# 4.2. 在向量字段上添加索引
index_params.add_index(
field_name="vector",
metric_type="COSINE",
index_type="IVF_FLAT",
index_name="vector_index",
params={ "nlist": 128 }
)
# 4.3. 创建索引文件
client.create_index(
collection_name="customized_setup",
index_params=index_params,
sync=False # 是否等待索引创建完成后再返回,默认True
)
参数说明
| 参数名 | 描述 |
|---|---|
| field_name | 要应用此对象的目标字段名称 |
| metric_type | 用于测量向量之间相似度的算法。可能的值有IP、L2、COSINE、JACCARD、HAMMING。此项仅适用于向量字段。有关详细信息,请参阅Milvus支持的索引。 |
| index_type | 用于在指定字段中排列数据的算法名称。适用的算法,请参阅内存索引和磁盘索引。 |
| index_name | 应用此对象后生成的索引文件名称 |
| params | 对指定索引类型的微调参数。有关可能的键和值范围,请参阅内存索引。 |
| collection_name | 已存在的集合名称 |
| index_params | 包含多个IndexParam对象的IndexParams对象 |
| sync | 控制索引的构建方式。有效值:True(默认值):客户端等待索引构建完成后才返回。这意味着您在处理完成之前不会得到响应。False:客户端在接收到请求后立即返回,并在后台构建索引。要查看索引是否已完成构建,请使用describe_index()方法。 |
注意
目前,每个集合中的每个字段只能创建一个索引文件。
检查索引详情
创建索引后,您可以检查其详细信息。
要检查索引详情,使用list_indexes()列出索引名称,使用describe_index()获取索引详细信息。
python展开代码# 5. 描述索引
res = client.list_indexes(
collection_name="customized_setup"
)
print(res)
# 输出
# [
# "vector_index",
# ]
res = client.describe_index(
collection_name="customized_setup",
index_name="vector_index"
)
print(res)
# 输出
# {
# "index_type": ,
# "metric_type": "COSINE",
# "field_name": "vector",
# "index_name": "vector_index"
# }
您可以检查特定字段上创建的索引文件,并收集使用该索引文件的索引行数统计信息。
删除索引
如果不再需要某个索引,您可以将其删除。
在删除索引之前,确保已释放该索引。
要删除索引,使用drop_index()。
python展开代码# 6. 删除索引
client.drop_index(
collection_name="customized_setup",
index_name="vector_index"
)
标量字段索引
在Milvus中,标量索引用于通过特定的非向量字段值加速元过滤,类似于传统数据库的索引。本文将引导您创建和配置用于整数、字符串等字段的标量索引。
标量索引类型
-
自动索引:Milvus会根据标量字段的数据类型自动决定索引类型。当您不需要控制具体的索引类型时,可以使用自动索引。
-
自定义索引:您可以指定具体的索引类型,如倒排索引或位图索引。这为索引类型选择提供了更多的控制。
自动索引
要使用自动索引,在add_index()中省略index_type参数,Milvus会根据标量字段的类型推断出索引类型。
有关标量数据类型和默认索引算法之间的映射,请参阅标量字段索引算法。
python展开代码# 自动索引
client = MilvusClient(
uri="http://localhost:19530"
)
index_params = MilvusClient.prepare_index_params() # 准备一个空的 IndexParams 对象,无需指定任何索引参数
index_params.add_index(
field_name="scalar_1", # 要索引的标量字段名称
index_type="", # 索引类型,自动索引时留空或省略该参数
index_name="default_index" # 要创建的索引名称
)
client.create_index(
collection_name="test_scalar_index", # 指定集合名称
index_params=index_params
)
自定义索引
要使用自定义索引,通过add_index()中的index_type参数指定特定的索引类型。
下面的示例创建了一个倒排索引,适用于标量字段scalar_2。
python展开代码index_params = MilvusClient.prepare_index_params() # 准备一个 IndexParams 对象
index_params.add_index(
field_name="scalar_2", # 要索引的标量字段名称
index_type="INVERTED", # 要创建的索引类型
index_name="inverted_index" # 要创建的索引名称
)
client.create_index(
collection_name="test_scalar_index", # 指定集合名称
index_params=index_params
)
方法和参数
prepare_index_params()
准备一个IndexParams对象。
add_index()
将索引配置添加到IndexParams对象中。
field_name(字符串):要索引的标量字段名称。index_type(字符串):要创建的标量索引类型。对于隐式索引,留空或省略此参数。
对于自定义索引,index_type的有效值包括:
-
INVERTED:(推荐)倒排索引由包含所有已分词单词的术语字典组成,单词按字母顺序排序。详细信息请参阅标量索引。
-
STL_SORT:使用标准模板库排序算法对标量字段进行排序。仅支持数字字段(例如INT8、INT16、INT32、INT64、FLOAT、DOUBLE)。
-
Trie:用于快速前缀搜索和检索的树形数据结构。支持VARCHAR字段。
-
index_name(字符串):要创建的标量索引的名称。每个标量字段支持一个索引。
create_index()
在指定的集合中创建索引。
collection_name(字符串):要创建索引的集合名称。index_params:包含索引配置的IndexParams对象。
验证结果
使用list_indexes()方法验证标量索引的创建:
python展开代码client.list_indexes(
collection_name="test_scalar_index" # 指定集合名称
)
# 输出:
# ['default_index', 'inverted_index']
限制
目前,标量索引支持以下数据类型:INT8、INT16、INT32、INT64、FLOAT、DOUBLE、BOOL、VARCHAR和ARRAY,但不支持JSON数据类型。
位图索引
位图索引是一种高效的索引技术,旨在提高低基数标量字段查询的性能。基数指的是字段中不同值的数量,基数较小的字段被认为是低基数字段。
这种索引类型通过将字段值表示为紧凑的二进制格式,并对其执行高效的按位操作,从而帮助减少标量查询的检索时间。与其他类型的索引相比,位图索引在处理低基数字段时通常具有更高的空间效率和更快的查询速度。
概述
“位图”一词结合了“Bit”和“Map”两个词。Bit是计算机中最小的数据单位,它只能存储0或1的值。Map在此上下文中指的是根据应该分配给0和1的值来转换和组织数据的过程。
位图索引由两个主要组成部分构成:位图和键。键表示索引字段中的唯一值。对于每个唯一值,都有一个对应的位图。这些位图的长度等于集合中的记录数。位图中的每一位都对应集合中的一条记录。如果记录中索引字段的值与某个键匹配,则对应的位设为1;否则,设为0。
例如,考虑一个包含“Category”和“Public”字段的文档集合。我们希望检索属于“Tech”类别并且公开的文档。在这种情况下,位图索引的键是“Tech”和“Public”。
位图索引
如图所示,Category和Public的位图索引如下:
- Tech: [1, 0, 1, 0, 0],表示只有第1个和第3个文档属于Tech类别。
- Public: [1, 0, 0, 1, 0],表示只有第1个和第4个文档对公众开放。
为了找到同时满足这两个条件的文档,我们对这两个位图执行按位与(AND)操作:
- Tech AND Public: [1, 0, 0, 0, 0]
结果的位图 [1, 0, 0, 0, 0] 表明只有第一个文档(ID为1)同时满足这两个条件。通过使用位图索引和高效的按位操作,我们可以快速缩小搜索范围,从而避免扫描整个数据集。
创建位图索引
要在Milvus中创建位图索引,可以使用create_index()方法,并将index_type参数设置为"BITMAP"。
python展开代码from pymilvus import MilvusClient
index_params = client.create_index_params() # 准备一个空的 IndexParams 对象,无需指定任何索引参数
index_params.add_index(
field_name="category", # 要索引的标量字段名称
index_type="BITMAP", # 要创建的索引类型
index_name="category_bitmap_index" # 要创建的索引名称
)
client.create_index(
collection_name="my_collection", # 指定集合名称
index_params=index_params
)
在这个示例中,我们为my_collection集合中的category字段创建了一个位图索引。add_index()方法用于指定字段名称、索引类型和索引名称。
一旦位图索引创建完成,您可以在查询操作中使用filter参数,基于索引字段执行标量过滤。这使得您可以通过位图索引高效地缩小搜索结果的范围。有关更多信息,请参阅元数据过滤。
限制
位图索引仅支持非主键的标量字段。
字段的数据类型必须是以下之一:
- BOOL、INT8、INT16、INT32、INT64、VARCHAR
- ARRAY(元素类型必须是:BOOL、INT8、INT16、INT32、INT64、VARCHAR)
位图索引不支持以下数据类型:
- FLOAT、DOUBLE:浮动类型与位图索引的二进制特性不兼容。
- JSON:JSON数据类型具有复杂结构,不能有效地使用位图索引表示。
位图索引不适用于高基数字段(即具有大量不同值的字段)。
一般而言,位图索引在字段的基数小于500时最为有效。当基数超过此阈值时,位图索引的性能优势会降低,存储开销也会显著增加。
对于高基数字段,考虑使用其他索引技术(如倒排索引),具体选择应根据您的使用场景和查询要求。
使用GPU构建索引
本指南概述了如何在Milvus中构建支持GPU的索引,这可以显著提高在高吞吐量和高召回场景中的搜索性能。有关Milvus支持的GPU索引类型的详细信息,请参见GPU索引。
配置Milvus设置以控制GPU内存
Milvus使用一个全局的图形内存池来分配GPU内存。
Milvus配置文件中支持两个参数:initMemSize 和 maxMemSize。内存池的大小初始设置为initMemSize,并且在超过此限制后,会自动扩展到maxMemSize。
默认情况下,initMemSize是Milvus启动时可用GPU内存的一半,maxMemSize等于所有可用GPU内存。
直到Milvus 2.4.1版本(包括2.4.1),Milvus使用统一的GPU内存池。对于2.4.1之前的版本(包括2.4.1),建议将这两个值都设置为0。
yaml展开代码gpu:
initMemSize: 0 # 设置初始内存池大小
maxMemSize: 0 # maxMemSize设置最大内存使用限制。当内存使用超过initMemSize时,Milvus将尝试扩展内存池。
从Milvus 2.4.1版本开始,GPU内存池仅用于搜索过程中临时GPU数据。因此,建议将其设置为2048和4096。
yaml展开代码gpu:
initMemSize: 2048 # 设置初始内存池大小
maxMemSize: 4096 # maxMemSize设置最大内存使用限制。当内存使用超过initMemSize时,Milvus将尝试扩展内存池。
构建索引
以下示例演示了如何构建不同类型的GPU索引。
准备索引参数
在设置GPU索引参数时,需要定义index_type、metric_type和params:
index_type(字符串):用于加速向量搜索的索引类型。有效选项包括GPU_CAGRA、GPU_IVF_FLAT、GPU_IVF_PQ和GPU_BRUTE_FORCE。metric_type(字符串):用于衡量向量相似性的度量类型。有效选项包括IP和L2。params(字典):特定索引的构建参数。此参数的有效选项取决于索引类型。
以下是不同索引类型的配置示例:
GPU_CAGRA索引
python展开代码index_params = {
"metric_type": "L2",
"index_type": "GPU_CAGRA",
"params": {
'intermediate_graph_degree': 64,
'graph_degree': 32
}
}
params的可能选项包括:
intermediate_graph_degree(整数):通过确定修剪前图的度来影响召回率和构建时间。推荐值为32或64。graph_degree(整数):通过设置修剪后图的度来影响搜索性能和召回率。通常,它是intermediate_graph_degree的一半。两者之间的差异越大,构建时间越长。其值必须小于intermediate_graph_degree的值。build_algo(字符串):选择修剪前图的生成算法。可能的选项:IVF_PQ:提供较高的质量,但构建时间较长。NN_DESCENT:提供更快的构建,但召回率可能较低。
cache_dataset_on_device(字符串,“true” | “false”):决定是否将原始数据集缓存到GPU内存中。设置为“true”可以通过优化搜索结果提高召回率,而设置为“false”则节省GPU内存。
GPU_IVF_FLAT 或 GPU_IVF_PQ索引
python展开代码index_params = {
"metric_type": "L2",
"index_type": "GPU_IVF_FLAT", # 或 GPU_IVF_PQ
"params": {
"nlist": 1024
}
}
params的选项与IVF_FLAT和IVF_PQ中的选项相同。
GPU_BRUTE_FORCE索引
python展开代码index_params = {
'index_type': 'GPU_BRUTE_FORCE',
'metric_type': 'L2',
'params': {}
}
不需要额外的params配置。
构建索引
配置好index_params中的索引参数后,调用create_index()方法来构建索引。
python展开代码# 获取现有集合
collection = Collection("YOUR_COLLECTION_NAME")
collection.create_index(
field_name="vector", # 用于构建索引的向量字段名称
index_params=index_params
)
搜索
一旦构建了GPU索引,下一步是准备搜索参数,然后执行搜索。
准备搜索参数
以下是不同索引类型的搜索参数配置示例:
GPU_BRUTE_FORCE索引
python展开代码search_params = {
"metric_type": "L2",
"params": {}
}
不需要额外的params配置。
GPU_CAGRA索引
python展开代码search_params = {
"metric_type": "L2",
"params": {
"itopk_size": 128,
"search_width": 4,
"min_iterations": 0,
"max_iterations": 0,
"team_size": 0
}
}
关键搜索参数包括:
itopk_size:确定搜索过程中保留的中间结果的大小。较大的值可能提高召回率,但会影响搜索性能。它应该至少等于最终的top-k(限制)值,通常是2的幂(例如16、32、64、128)。search_width:指定搜索时进入CAGRA图的入口点数量。增加此值可以提高召回率,但可能影响搜索性能。min_iterations/max_iterations:这些参数控制搜索迭代过程。默认情况下,它们设置为0,CAGRA会自动根据itopk_size和search_width确定迭代次数。手动调整这些值可以帮助平衡性能和准确性。team_size:指定用于计算GPU上度量距离的CUDA线程数。常见的值是2的幂,最大为32(例如2、4、8、16、32)。它对搜索性能的影响较小。默认值为0,Milvus会根据向量维度自动选择team_size。
GPU_IVF_FLAT 或 GPU_IVF_PQ索引
python展开代码search_params = {
"metric_type": "L2",
"params": {"nprobe": 10}
}
这两种索引类型的搜索参数与IVF_FLAT和IVF_PQ中使用的参数类似。有关更多信息,请参阅执行向量相似性搜索。
执行搜索
使用search()方法在GPU索引上执行向量相似性搜索。
python展开代码# 将数据加载到内存
collection.load()
collection.search(
data=[[query_vector]], # 查询向量
anns_field="vector", # 向量字段名称
param=search_params,
limit=100 # 返回的结果数量
)
限制
使用GPU索引时,需要注意以下限制:
- 对于GPU_IVF_FLAT,
limit的最大值为256。 - 对于GPU_IVF_PQ和GPU_CAGRA,
limit的最大值为1024。 - 对于GPU_BRUTE_FORCE,
limit的最大值没有固定限制,但建议不超过4096,以避免可能的性能问题。 - 当前,GPU索引不支持余弦距离。如果需要余弦距离,数据应先进行归一化,然后可以使用内积(IP)距离作为替代。
- GPU索引对内存不足保护(OOM)支持不完全,过多数据可能导致QueryNode崩溃。
- GPU索引不支持范围搜索和分组搜索等功能。
常见问题
何时使用GPU索引?
GPU索引特别适用于需要高吞吐量或高召回率的场景。例如,在处理大批量数据时,GPU索引的吞吐量可以比CPU索引高出100倍以上。在较小批量的场景中,GPU索引的性能仍然显著优于CPU索引。此外,如果需要快速的数据插入,加入GPU可以显著加速索引的构建过程。
GPU索引(如CAGRA、GPU_IVF_PQ、GPU_IVF_FLAT和GPU_BRUTE_FORCE)适用于哪些场景?
- CAGRA索引适用于需要高性能的场景,但会消耗更多内存。
- GPU_IVF_PQ索引适用于内存受限的环境,尽管精度会有所降低,但可以减少存储需求。
- GPU_IVF_FLAT索引是一种平衡选项,提供了性能和


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!