目录
mini-omni2
https://arxiv.org/abs/2410.11190
https://github.com/gpt-omni/mini-omni2
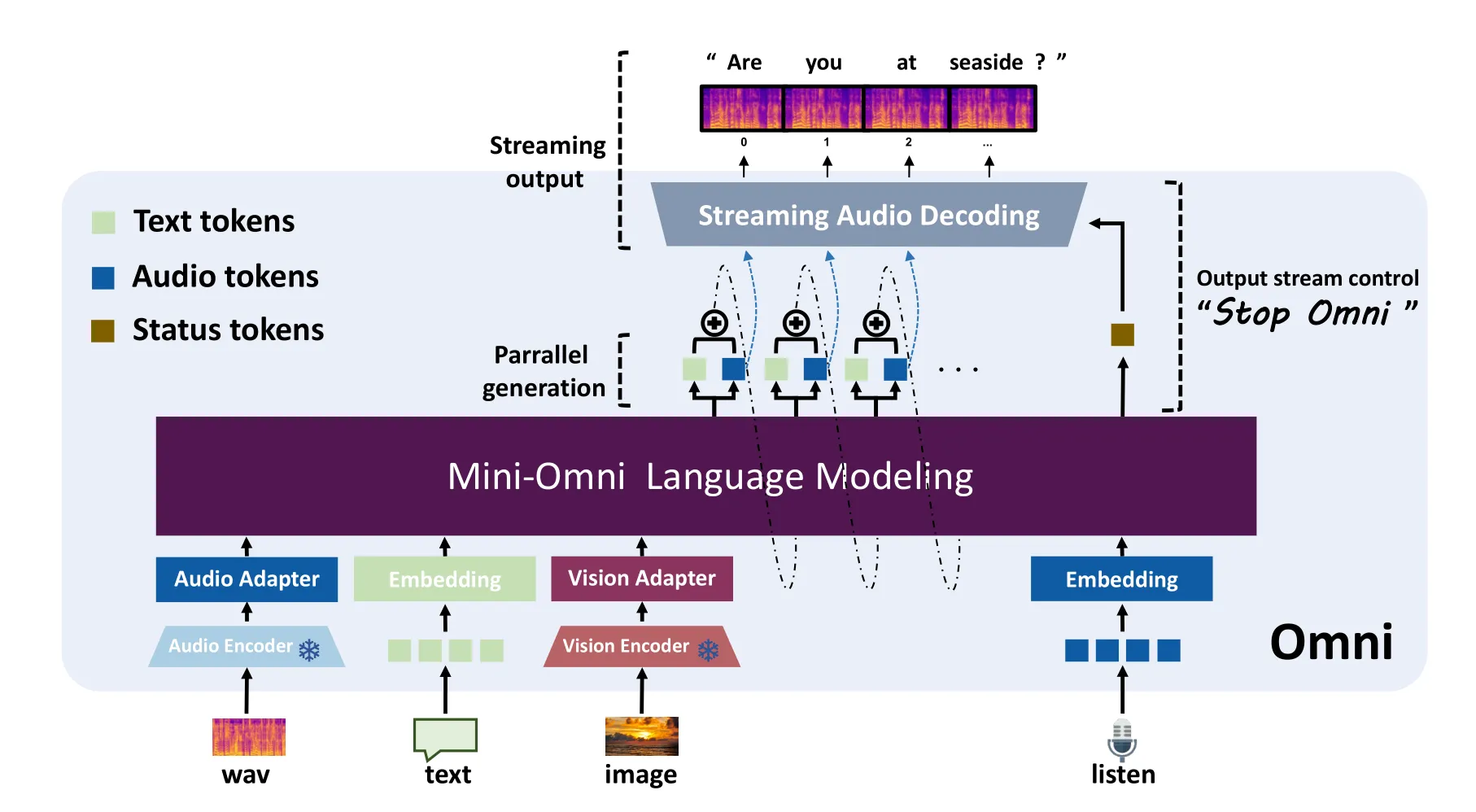
多阶段训练:我们提出一种有效的对齐训练方法,并在三阶段训练中分别进行编码器自适应、模态对齐和多模态微调。
训练策略
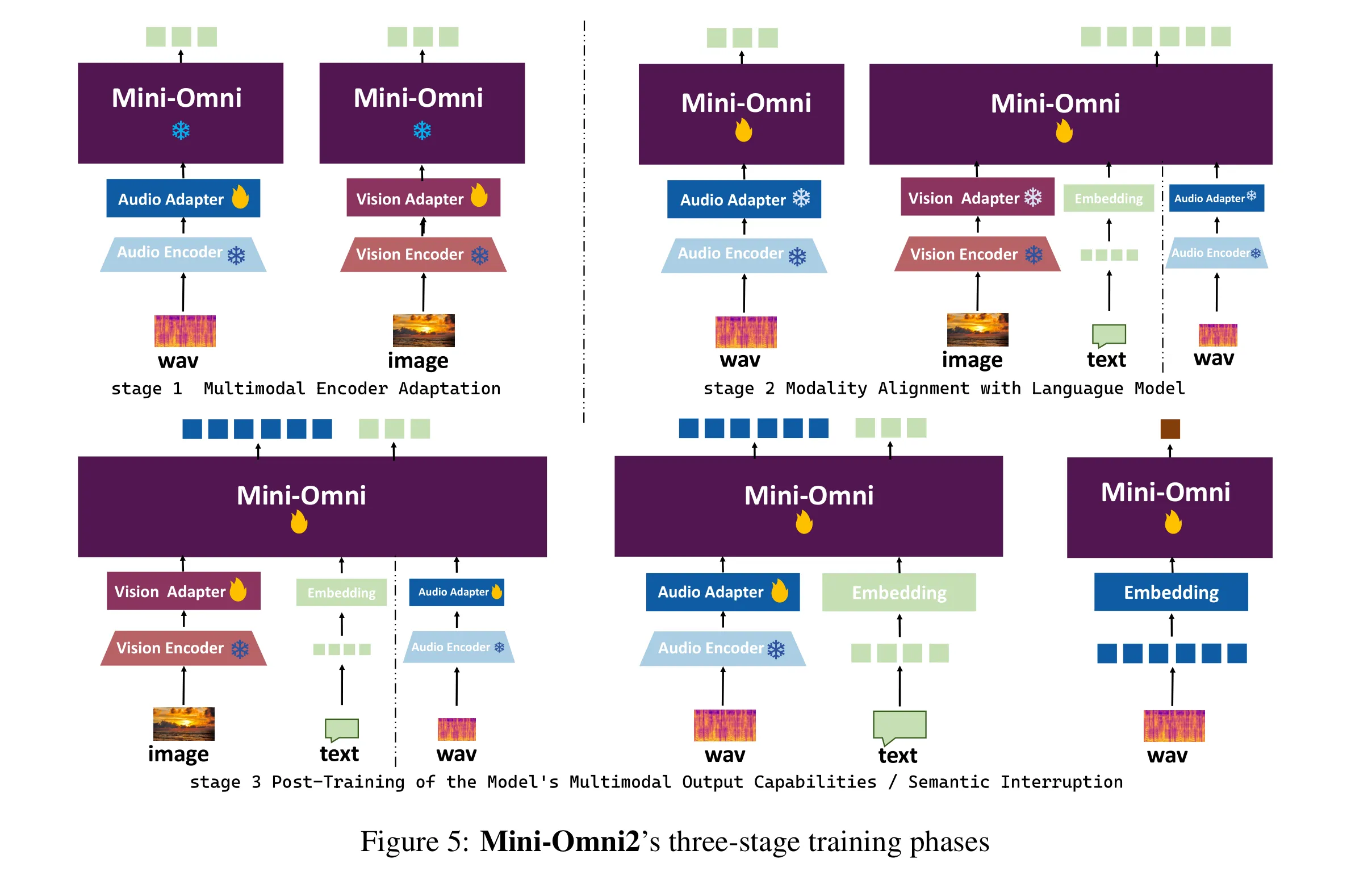
在本节中,我们将介绍 Mini-Omni2 模型的训练阶段。Mini-Omni2 的整体训练流程如图 5 所示。训练过程分为三个阶段,每个阶段均采用多任务训练。在图中,除了第 1 阶段外,还额外引入了一项基础的文本到文本任务,但未明确展示。我们将整个训练过程划分为以下三个阶段:
-
多模态编码器适配
在第 1 阶段,我们采用快速的小规模训练,仅针对连接语言模型与编码器的线性层权重进行训练。第 1 阶段的目标是确保模型接收到的多模态特征与模型嵌入层中表示的文本标记特征高度相似。我们认为这种方法有两个主要优势:- 它使模型能够在后续训练中专注于基于模态特定问题回答的逻辑推理。
- 它将语言模型核心参数的变化最小化,避免因适配其他模态而导致较大的参数调整。
-
模态对齐
在第 2 阶段,模型训练的主要任务是将基于文本输入的问题回答能力迁移到基于图像和音频的问题回答能力上。在此步骤中,第 1 阶段训练的适配器会被暂时冻结,语言模型的权重则参与训练。在这一阶段,所有任务均不涉及音频输出。对于基于图像和音频的问题回答任务,仅生成基于文本的回答,以建立模型的基础逻辑能力。语音输出仅是这种逻辑能力在不同模态上的延伸。 -
后训练
在第 3 阶段,模型的任务是扩展输出模态以包含音频响应生成。如图 5 所示,模型将在第 1 阶段和第 2 阶段的所有任务上进行训练,但所有问题回答任务的输出均为音频标记。此外,模型还将学习中断机制,这是一种将在下一节介绍的算法。
双向交互
实时对话模型需要具备双向交互能力,以便实现更灵活的互动。然而,这种中断机制不应仅仅是一个基于 VAD(语音活动检测)的简单系统,而应是一个能够判断用户是否有意打断模型的系统。此外,模型的能力需要具备高度的鲁棒性,能够应对各种外部情况(例如噪声、其他对话和无关声音)。我们通过基于命令的任务来探索这一功能,在该任务中,当用户说“停止 Omni”时,模型将立即停止讲话。此外,这种方法可以自然地扩展,融入更复杂的语义中断机制,通过开发更具上下文适应性的中断数据集来实现。
背景噪声选择:
- 我们随机选用了来自 Libri-tts 数据集的多种语音识别样本作为原始的人类噪声数据样本。
- 我们使用了来自 MUSAN[Snyder et al., 2015] 数据集的样本,其中包括音乐、人类语音、白噪声和城市噪声。
语义中断构建:
我们合成了带有随机语音音色的“停止 Omni”短语,并将其与噪声混合。具体的数据构建方法将在下一节中介绍。
结合上述数据,模型将接收到包含“停止 Omni”短语的长序列数据,数据中穿插着各种噪声。模型将在实时生成过程中生成两种类型的状态标记:irq 和 n-irq,分别表示用户有意中断和无意中断。当推理时,若模型输出 irq 标记,它将停止生成过程并开始聆听新的问题。对于此任务,我们使用标记作为输入,以增强模型的实时处理能力。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!