大模型量化方法解析:WO、AWQ、GPTQ 与 SQ 的对比
目录
WO、AWQ、GPTQ 与 SQ 的对比
随着深度学习模型规模的不断扩大,模型的部署和推理变得更加昂贵。量化技术通过降低模型的计算精度(如从浮点数到整数)显著减少模型的存储需求和计算复杂度,是优化大模型的重要手段。目前有多种量化方法被提出,它们各自有针对性的特点和适用场景。本文将介绍以下四种主流量化技术及其差异:
- WO:仅权重量化(Weight Only Quantization)
- AWQ:激活感知权重量化(Activation-aware Weight Quantization)
- GPTQ:生成预训练 Transformer 量化(Generative Pretrained Transformer Quantization)
- SQ:平滑量化(Smooth Quantization)
对比总结
| 特性 | WO | AWQ | GPTQ | SQ |
|---|---|---|---|---|
| 量化范围 | 权重 | 权重 + 激活感知 | 权重 | 权重 + 激活 |
| 低位宽支持 | INT8 / INT4 | INT4 | INT8/INT4 | INT8 |
| 激活值处理 | 不处理 | 激活分布优化 | 无 | 平滑处理 |
| 误差补偿机制 | 无 | 无 | 有 | 有 |
| 精度保持 | 一般 | 优秀 | 优秀 | 良好 |
| 实现复杂度 | 低 | 高 | 较高 | 高 |
| 适用场景 | 存储优化,硬件友好 | 精度敏感的低位量化 | 生成式任务的部署 | 全面量化和加速需求 |
如何选择?
- 资源受限、实现简单:选择 WO。
- 对精度要求高的低位宽量化(如INT4):选择 AWQ。
- 生成式任务(如大语言模型)的优化部署:选择 GPTQ。
- 全面优化权重和激活值量化,追求计算效率:选择 SQ。
不同量化方法适合的场景和目标各有侧重,开发者应根据模型的应用场景、硬件限制和性能需求选择合适的量化技术,以达到存储、计算效率和精度的最佳平衡。
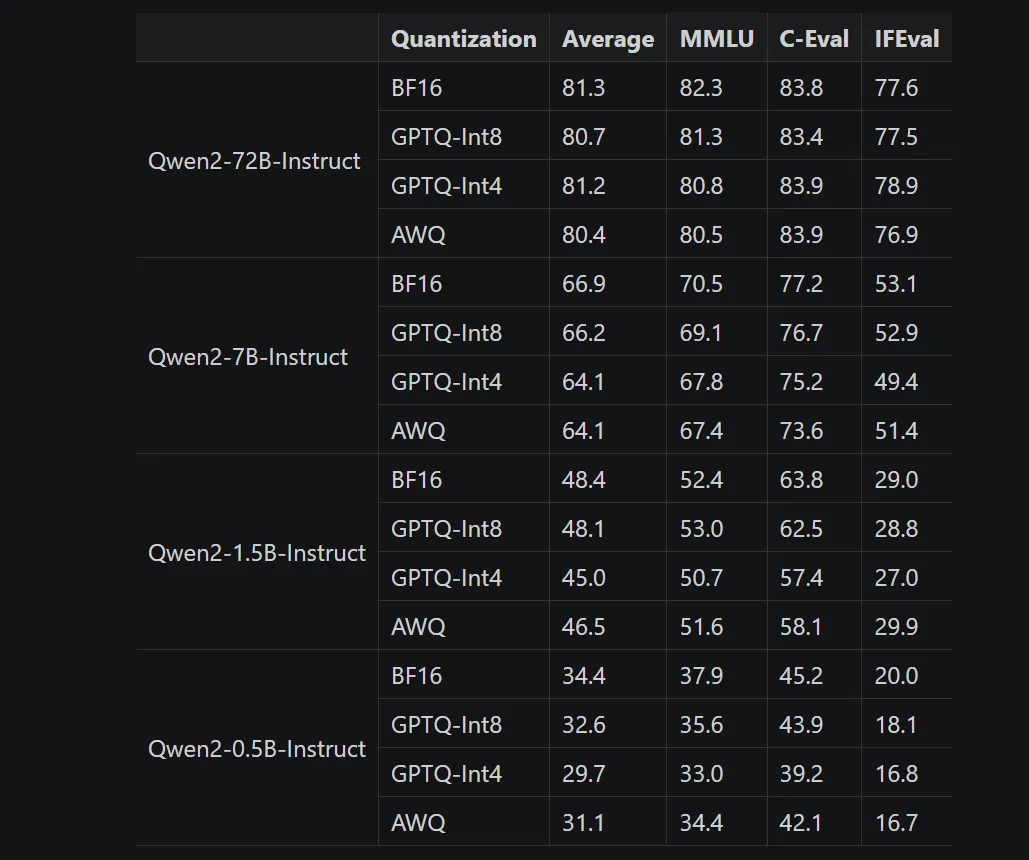
量化必然带来准确率不行,详细看这个对比表体会:
如果对你有用的话,可以打赏哦
打赏


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!
目录