目录
https://arxiv.org/abs/2308.02223
ESRL: Efficient Sampling-based Reinforcement Learning for Sequence Generation
论文的核心贡献主要包括两方面:
两阶段采样:传统的RL训练在序列生成任务中通常需要为每个生成的候选序列存储计算图,而这会消耗大量内存。为了优化这一点,ESRL采用了两阶段采样方法:在第一阶段,模型采用自回归方式生成候选序列,但不进行反向传播,避免了计算图的存储。第二阶段是计算这些候选序列的概率,利用Transformer的并行计算能力减少了计算图存储的需求。尽管增加了计算时间,但减少了内存消耗。
动态采样:ESRL还引入了动态采样机制,通过估计模型的能力(例如使用BLEU或熵值等度量)来调整采样的大小和温度。具体来说,当模型的能力较强时,减少采样数量;而当能力较弱时,增加采样量以提高探索效果。通过这种方法,ESRL避免了过度采样,从而进一步提高了训练效率。
一切都在此图中,以往模型的采样没有技巧,花费显存和时间,ESRL让这个过程变得高效:
摘要
将强化学习(RL)应用于序列生成模型可以直接优化长期奖励(例如,BLEU 分数和人工反馈),但通常需要在一个动作序列空间中进行大规模采样。这在序列生成问题(如机器翻译)中是一个计算挑战,因为我们通常需要处理一个庞大的动作空间(如词汇表)和一个长的动作序列(如翻译)。在这项工作中,我们提出了两阶段采样和动态采样方法,以提高在通过强化学习训练序列生成模型时的采样效率。我们在传统的序列生成任务上实验了这些方法,包括机器翻译和抽象摘要。此外,我们还通过使用奖励模型训练大规模语言模型,评估了我们的方法在基于人类反馈的强化学习(RLHF)中的表现。实验结果表明,基于高效采样的强化学习方法(称为ESRL)在训练效率和内存消耗方面都优于所有基线方法。特别地,ESRL在性能上超越了强有力的REINFORCE、最小风险训练和邻近策略优化方法。
介绍
摘要
将强化学习(RL)应用于序列生成模型可以直接优化长期奖励(例如,BLEU 分数和人工反馈),但通常需要在一个动作序列空间中进行大规模采样。这在序列生成问题(如机器翻译)中是一个计算挑战,因为我们通常需要处理一个庞大的动作空间(如词汇表)和一个长的动作序列(如翻译)。在这项工作中,我们提出了两阶段采样和动态采样方法,以提高在通过强化学习训练序列生成模型时的采样效率。我们在传统的序列生成任务上实验了这些方法,包括机器翻译和抽象摘要。此外,我们还通过使用奖励模型训练大规模语言模型,评估了我们的方法在基于人类反馈的强化学习(RLHF)中的表现。实验结果表明,基于高效采样的强化学习方法(称为ESRL)在训练效率和内存消耗方面都优于所有基线方法。特别地,ESRL在性能上超越了强有力的REINFORCE、最小风险训练和邻近策略优化方法。
引言
近年来,强化学习(RL)在训练序列生成模型中的应用引起了广泛关注。这主要是因为序列生成本质上是一个长期决策问题,而强化学习特别适合优化长期奖励,例如序列级别的分数(Wieting 等,2019;Donato 等,2022)和人工反馈(Nguyen, Daumé III, 和 Boyd-Graber,2017;Stiennon 等,2020;Ouyang 等,2022;OpenAI,2022)。此外,通过利用自回归生成模式,强化学习训练可以显著缓解暴露偏差问题(Ranzato 等,2016;Wang 和 Sennrich,2020)。
强化学习训练过程通常包括两个步骤:
- 使用预训练模型从输入中采样一批候选序列(称为探索),
- 使用强化学习方法,如REINFORCE(Williams 1992)和邻近策略优化(PPO)(Schulman 等,2017),通过给定采样序列来优化模型,从而获得长期奖励(称为优化)。
这种范式在多个序列生成任务上取得了有希望的结果,如机器翻译(Wieting 等,2019;Yehudai 等,2022;Donato 等,2022)、抽象摘要(Celikyilmaz 等,2018;Stiennon 等,2020)和对话生成(Hsueh 和 Ma,2020)。此外,它已被证明在引导大型语言模型(LLM)通过人类反馈进行学习方面具有良好的潜力(Ouyang 等,2022;OpenAI,2022)。
尽管如此,将强化学习应用于自然语言处理(NLP)并不是一件轻松的事。在序列生成的实际应用中,我们常常需要处理一个庞大的动作空间(如词汇表)和一个长的动作序列(如翻译)。这给探索过程带来了严重的计算挑战(Keneshloo 等,2019),也是设计复杂采样方法的重要原因。
为了解决这一问题,我们研究了在将强化学习应用于序列生成模型时,减少探索计算负担的策略。在这项工作中,我们提出了一种基于高效采样的强化学习(ESRL)方法,通过以下两种方法实现更高效的探索。一方面,我们使用了一个两阶段采样框架来实现探索。这可以充分利用Transformer的并行计算优势,从而消除过多计算图存储的需求。另一方面,我们提出了一种动态采样方法,通过考虑模型的能力来减少冗余采样。其动机是,过度采样并非必要,因为预训练的生成模型已经具备了一定的生成能力。
我们在基于Transformer(Vaswani 等,2017)的机器翻译和摘要任务上实验了提出的ESRL。实验结果表明,ESRL在生成质量、训练时间和内存消耗方面都超过了REINFORCE(Williams 1992;Kiegeland 和 Kreutzer,2021)和最小风险训练(Shen 等,2016)。值得注意的是,与REINFORCE相比,ESRL在机器翻译任务中能够减少47%的内存消耗和39%的训练时间。此外,我们的ESRL在IWSLT’14 De-En和WMT’14 En-De测试集上,超越了原始Transformer 1.04 BLEU分数以上的表现。
它在抽象摘要任务上显著超越了所有基线方法。此外,我们在RLHF(基于人类反馈的强化学习,Christiano 等,2017)中评估了我们的ESRL,并与LLaMA-7B-LoRA(Hu 等,2021b;Touvron 等,2023)进行对比。结果表明,在RLHF中,ESRL在内存效率和速度方面仍然显著更优,同时在GPT-4(Chiang 等,2023)评估下,比鲁棒的PPO(Schulman 等,2017)提高了+30.00分。
相关工作
尽管强化学习(RL)在机器人学和其他领域已经得到了广泛的应用,但最近它作为一种有前景的方法,在序列生成模型的提升方面表现出色(Ranzato 等,2016;Celikyilmaz 等,2018;Yehudai 等,2022;Donato 等,2022)。例如,Edunov 等(2018)比较了在序列生成模型中常用的目标函数。Choshen 等(2020)和Kiegeland与Kreutzer(2021)探讨了强化学习在神经机器翻译中的局限性。此外,Kiegeland和Kreutzer(2021)在领域内和跨领域适配设置中进行了实验,强调了强化学习训练过程中探索的重要性。近年来,使用强化学习训练符合人类偏好的大型语言模型也成为一种上升趋势(Nguyen、Daumé III 和 Boyd-Graber,2017;Stiennon 等,2020;Ouyang 等,2022;OpenAI,2022)。
作为另一项研究方向,研究人员集中在探索更好的奖励函数,以增强生成模型的学习,例如使用语义相似性(Li 等,2016;Wieting 等,2019;Yasui、Tsuruoka 和 Nagata,2019)以及设计学习型奖励函数(Shi 等,2018;Böhm 等,2019;Shu、Yoo 和 Ha,2021)。近期的工作还致力于解决序列生成模型中大规模动作空间的挑战(Hashimoto 和 Tsuruoka,2019;Yehudai 等,2022)。
尽管以往的工作在序列生成任务中提升了强化学习的性能,但往往受到低效探索问题的阻碍。研究人员已经意识到这一点(Keneshloo 等,2019),但关于这个问题的研究仍然较为罕见。
我们的方法
在本节中,我们首先回顾使用强化学习(RL)进行序列生成模型训练的基础知识。然后,我们将介绍我们高效的基于采样的强化学习方法。最后,我们介绍我们的优化算法。
基础知识
序列生成模型
给定一个输入,例如文本,序列生成模型生成一个包含个标记的序列,其中每个标记从一个词汇表中抽取。在训练阶段,模型学习概率:
在这个公式中, 是前缀 ,而 是一组模型参数。在这个过程中,标准的训练目标是最大化目标序列所有标记的似然,即最大似然估计(MLE)(Myung 2003)。在推理阶段,我们根据概率 顺序生成标记。在本文中,我们考虑神经机器翻译和抽象摘要任务,并将它们用作上述模型的实例。
长期奖励优化
给定一个预训练的序列生成模型,我们可以使用RL来训练这个模型。RL寻求最大化长期奖励,写作 ,其中 是一个训练实例, 是生成的序列, 是计算的长期奖励的奖励函数。 通常被定义为一个标准度量函数,如BLEU(Papineni et al. 2002)和ROUGE(Lin 2004)。这个训练实例的相应RL损失如下所示:
其中 是输出空间,包括输入的所有可能候选目标序列。
表示 通过优化模型参数 (\theta),使得给定输入 (x) 时,模型生成的序列 (\hat{y}) 的平均奖励最大化。
探索
然而,计算公式(2)是不可行的,因为 的大小随着词汇量和目标序列的长度呈指数增长。为了应对这一挑战,RL通常执行探索以近似。解决公式(2)的常用方法是Monte Carlo方法(Williams 1992)。对于每个训练实例,从由带温度因子的Softmax层定义的多项式分布中采样一些序列(Choshen et al. 2020)。在这里,采样大小和采样温度都可以用来控制我们探索空间的程度。例如,较大的规模意味着采样中涉及更多的候选者,较高的温度意味着采样序列的多样性更大(Kiegeland and Kreutzer 2021)。
策略梯度
为了用采样序列的长期奖励优化模型,常用的方法是策略梯度方法,如REINFORCE(Williams 1992)和最小风险训练(MRT)(Shen et al. 2016)。具体来说,REINFORCE使用对数导数来定义损失函数:
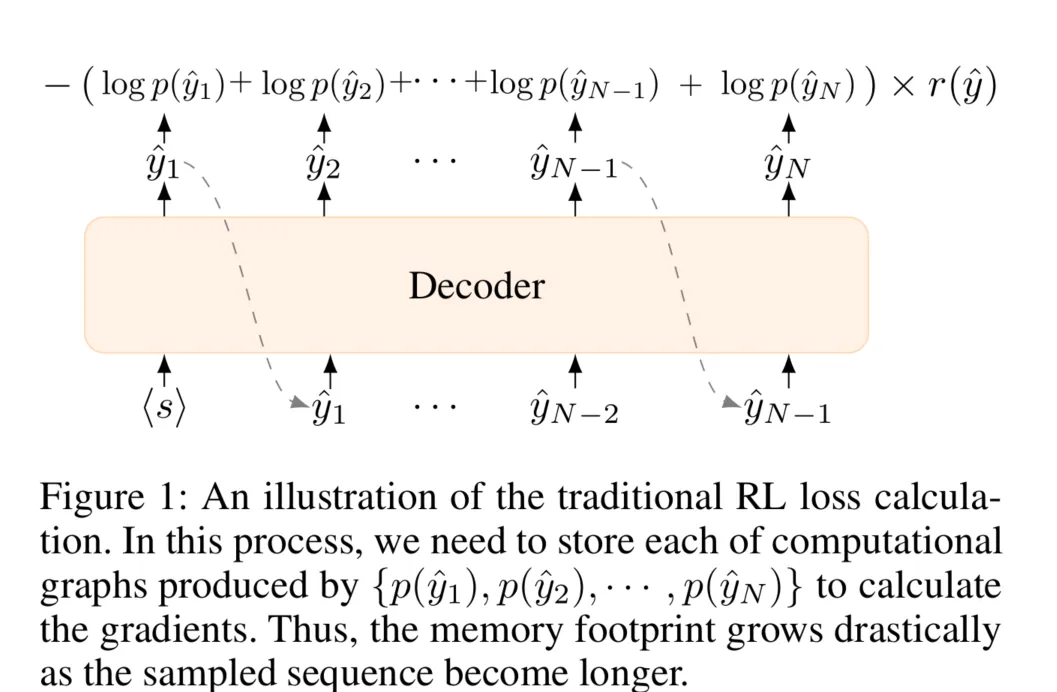
其中 是一个近似空间,由这些采样的序列组成。计算过程也在图1中进行了说明。由于每个序列都是通过自回归模式采样的,RL训练需要为每个训练实例存储比MLE更多的计算图(大约N次)。
与REINFORCE不同,MRT方法使用这些采样的序列通过重新归一化来近似后验分布:
其中 是平滑参数, 是定义在近似空间上的分布。基于分布,MRT给出了一个新的损失函数:
在某些情况下,与REINFORCE相比,MRT可以实现更好的性能(Kiegeland and Kreutzer 2021)。但MRT的探索过程需要大量内存来存储用于重新归一化的计算图。
高效采样基础的RL(ESRL)
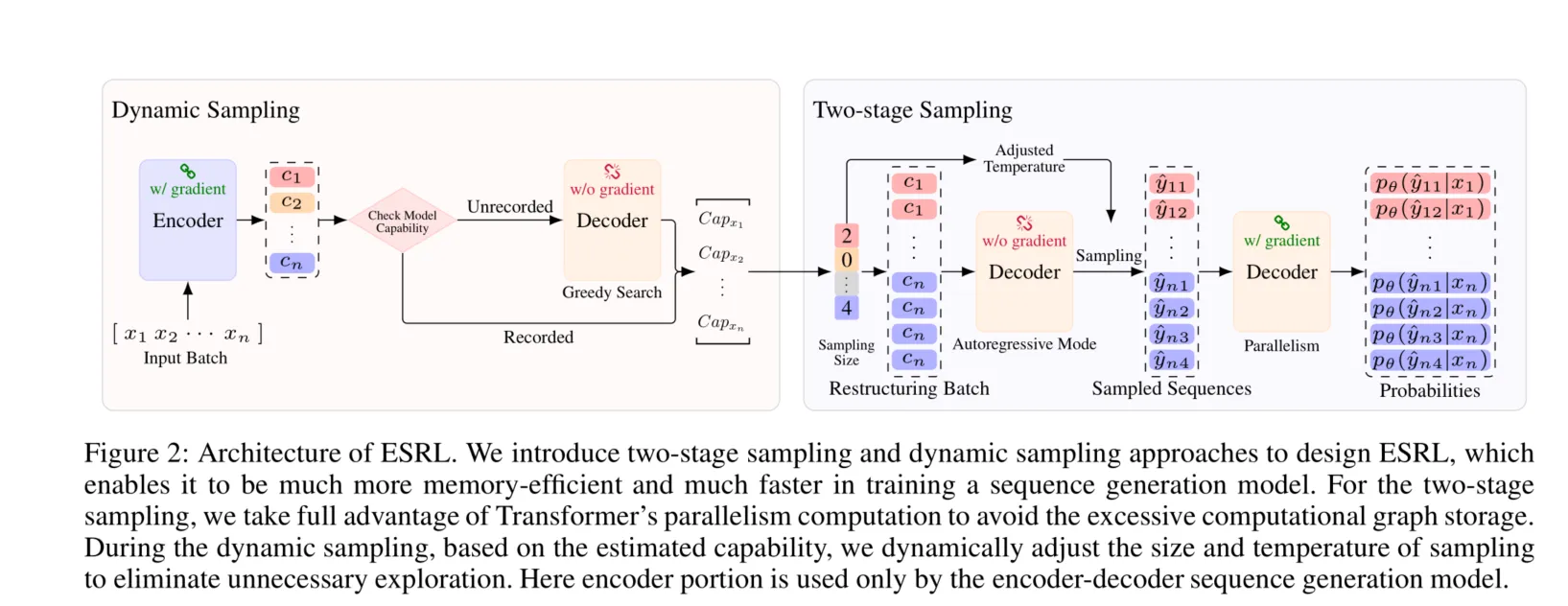
在这项工作中,我们的目标是减少将RL应用于序列生成模型的计算成本。我们提出ESRL来实现这一目标。ESRL的概述如图2所示。正如图中所示,我们提出的两阶段采样和动态采样在ESRL中实现了我们的目标。在接下来的子部分中,我们将详细描述它们。
图2:ESRL的架构。我们在设计ESRL时引入了两阶段采样和动态采样方法,这使得在训练序列生成模型时,其内存使用更加高效且速度更快。对于两阶段采样,我们充分利用了Transformer的并行计算能力,以避免过多的计算图存储。在动态采样过程中,根据估计的能力,我们动态调整采样的大小和温度,以消除不必要的探索。这里编码器部分仅用于编码器-解码器序列生成模型。
两阶段采样
为了应对采样过程中产生的过多计算图存储需求,我们使用了一种有效缓解该问题的两阶段框架。第一阶段是以自回归模式采样候选序列。注意,这个阶段不涉及反向传播。因此不需要存储计算图。第二阶段是计算采样候选序列的概率,即公式3和4中的。在这一阶段,由于存在完整的输出序列,我们可以使用Transformer的并行计算而不是自回归模式。这允许这一计算只需一次前向传递即可完成。相比于传统的采样方法,两阶段采样方法由于额外的前向传递而增加了时间成本。然而,借助两阶段采样,它可以有效减少内存占用。一般来说,RL训练的传统采样需要存储N次前向传递的计算图,而两阶段采样只存储一次前向传递的计算图。
动态采样
我们提出了一种动态采样方法来进一步提高RL训练的效率。在我们的动态采样方法中,我们首先估计模型能力,然后根据这一估计的能力调整采样大小和温度,以便能够以适当且高效的方式进行采样。
对于模型能力的估计,我们重复使用在上一个epoch中采样的旧序列。具体而言,给定一个输入,在采样候选序列后,我们使用这些采样的序列来估计模型对该输入的生成能力。然后,将估计的模型能力记录下来,并在后续的epoch中用于调整同一输入的采样大小。以机器翻译任务为例,我们使用熵(Settles 2009)和BLEU(Papineni et al. 2002)来估计模型能力。当使用BLEU来估计模型能力时,能力得分由以下公式给出:
其中是输入的采样大小,是sacreBLEU(Post 2018)。当考虑熵作为模型能力的另一种估计时,表示为:
对于特定任务,我们也有其他选择来定义。例如,在抽象摘要任务中,可以用ROUGE(Lin 2004)替代BLEU。注意,当尚未记录给定输入的模型能力时,即尚未对输入执行采样操作时,我们采用贪婪搜索算法快速生成一个最优序列。然后我们用这个生成的序列来估计模型能力。
对于采样大小的调整,我们的主要目标是消除不必要的探索。具体而言,当较高时,我们认为模型有能力获得很好的长期回报,因此减少采样大小。相反,当较低时,我们增加采样大小以进行更大规模的探索。这使得模型能够从每个输入的足够数量的可能生成序列中学习,提高其自身的能力。为达到此目的,我们使用以下函数:
其中和分别表示调整后的采样大小和最大采样大小。是相对于样本总数在[0, 1)范围内的消除样本比例。我们采用批次级别的消除策略,减少当前批次分布中能力得分较高的输入的采样大小。因此,表示当前批次中所有输入组成的输入集,表示输入数目。
考虑到采样温度也会影响探索,我们采用简单策略通过调整温度来控制探索:当能力得分较低时,使用较高的温度以鼓励探索。我们基于调整后的采样大小在区间内动态调整温度,以进一步控制探索。温度调整规则为:
其中是输入的调整后温度。
在调整采样大小和温度后,我们为每个输入采样个候选序列。按照Kiegeland和Kreutzer(2021)的工作,我们使用批次重构技巧,通过重复编码器表示来重构新批次,以作为解码器的输入(见图2),以利用并行计算。
优化
我们用MRT和REINFORCE的融合替代标准策略方法来计算损失。具体而言,当时,我们使用作为损失。当时,由于重新标准化不可行,我们改用作为损失。此设计结合了MRT和REINFORCE的优点,充分利用采样的序列来优化模型。
基于FIFO的基线奖励
基线奖励技术(Sutton and Barto 2018)已被证明可以有效提高序列生成模型的泛化能力(Kreutzer, Sokolov, and Riezler 2017)。理想的基线值是所有可能候选序列的长期回报的平均值。然而,这在序列生成任务中难以实现,因为候选序列数量呈指数级增长。尽管一些工作尝试估计这一理想基线值(Hashimoto and Tsuruoka 2019),但它们涉及复杂的训练。受Wang et al.(2021)工作中使用队列代理全局的想法启发,我们提出了一种基于FIFO的基线奖励方法,该方法使用先进先出(FIFO)全局奖励队列来计算基线值。我们用表示奖励队列的大小。在每个训练步骤中,我们将所有采样序列的奖励推入并弹出“最旧”的奖励。然后计算中奖励的平均值作为基线值。通过使用这个基线奖励,我们用替换公式3和4中的奖励函数。
全局队列大小对性能的影响
我们还分析了全局队列大小对我们ESRL性能的影响。图4(右)展示了不同全局队列大小的实验结果。可以看到,过小或过大的队列大小都会影响BLEU分数。这可以归因于以下事实:较小的队列大小无法准确近似全局级奖励的平均值,而较大的全局队列可能包含过多过时的奖励。
与Off-policy RL方法的比较
表5展示了在IWSLT数据集上off-policy RL方法的性能。我们可以观察到,在各种指标的评估下,ESRL仍然优于强GOLD(Pang and He 2020)。此外,我们的ESRL与off-policy RL方法是正交的。在这里,我们以GOLD-s为例。具体来说,我们首先使用ESRL训练一个翻译模型,然后使用训练好的模型执行GOLD-s过程。实验结果表明,结合的方法可以实现更优的性能。
探索与利用的平衡
在规划问题中,平衡探索与利用已被证明可以改善RL(Tokic 2010; Sutton and Barto 2018; Jiang and Lu 2020)。在此,我们试图从有效实现探索与利用平衡的角度说明我们的ESRL可以比所有基准获得更好性能的观察。当模型具有强大的能力并获得高确定性奖励时,我们的ESRL尽可能利用并减少探索,即减少采样的大小和温度。这使得模型能够充分利用当前学习到的知识进行决策和优化。相反,当模型能力较弱时,ESRL增加采样的大小和温度以增强探索,从而收集更多可能生成的序列来优化模型。因此,与基准相比,使用动态采样方法使得ESRL能够很好地平衡探索和利用,并获得更好的性能。更多分析详见附录B。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!