目录
Android Instruct 数据集,该数据集包含 94.3k 条操作记录,用于细调模型。
A NDROID L AB 基准测试提出了显著的挑战,因为即使是领先的模型 GPT-4o 也只能达到 31.16% 的成功率。
ANDROID L AB 定义了一组动作空间和两种操作模式,形成了 ANDROID L AB 环境。我们采用了前人工作中的主要动作空间,并增加了一个模型返回值(完成动作)。这两种基本的操作模式是 SoM(Yang et al., 2023a)和仅 XML 模式,区别在于代理是否可以访问手机屏幕的快照。
动作空间
- 我们定义了四个基本的手机操作:点击(Tap)、滑动(Swipe)、输入(Type)、长按(Long Press)。此外,还增加了一个完成动作。
操作模式
- SoM 模式:SoM 模式允许代理通过两轮交互来完成任务。第一轮生成所需动作的详细描述,第二轮输出实际的动作。
- 仅 XML 模式:仅 XML 模式使用手机的 XML 数据来识别屏幕信息,这些信息唯一定义了任务完成情况。这种模式确保了任务完成是主要评估指标。
- ReAct 模式:基于上述两种模式,我们遵循(Yao et al., 2022b)的方法提示模型,允许模型逐步思考并输出其思维和推理过程。
- SeeAct 模式:根据(Zheng et al., 2024),我们将推理和元素定位过程分开。我们指示模型在单个操作中进行两轮交互。第一轮生成所需动作的详细描述,第二轮输出实际的动作。
指标
-
成功率:对于操作任务,我们将一个完整的任务分解为多个子目标,并确定每个子目标完成时的具体页面信息。通过检查和匹配特定的 UI 树元素,我们逐个评估每个子目标的完成情况。当所有子目标都完成后,任务被视为成功执行。此外,我们还设置了一些可以直接使用设备状态来判断是否正确完成的任务。对于查询任务,高级 LLMs 会验证模型预测结果与标准答案是否匹配,避免因直接字符串比较而产生的错误。我们在图4中提供了一个示例。
-
子目标成功率:任务被分解为子目标,并按顺序评估其完成情况。这一更细致的指标奖励那些具有更强理解和操作能力的模型。只有操作任务包含子目标成功率。
-
冗余率倒数:根据先前的工作(Xing et al., 2024),冗余通过将模型的操作路径长度与人类基准进行比较来测量。我们计算已完成任务的这一指标并取其倒数,因此较高的值表示冗余较少。我们不报告 SR < 5 的情况,因为完成的任务太少,可能会受到少量特殊值的影响。还应强调的是,由于人类操作步骤不一定是最优的,这一指标可能超过100。
-
合理操作率:这一指标评估在哪些操作后屏幕发生了变化。未发生变化的屏幕表明该操作无效,因此被视为不合理。
数据构建
数据构建的主要挑战包括生成可执行的Android指令和标注操作路径数据。我们的方法涉及三个步骤:
-
任务派生与扩展:我们使用学术数据集(Rawles et al., 2023; Coucke et al.)并手动编写指令以启动任务生成。语言模型用于创建额外的任务,这些任务经过审查后被添加到数据集中,确保指令的真实性和可执行性。
-
自探索:使用大型语言模型(LLMs)和大型多模态模型(LMMs)进行自动任务探索,完成后输出完成信号。最初,手动选择用于验证结果,但在收集500条轨迹后,后来用奖励模型替换了手动选择。
-
手动标注:此过程包括四个步骤:(1) 指令检查,注释者评估给定任务的可行性;(2) 初步熟悉,允许他们探索应用程序界面后再执行任务;(3) 任务执行,注释者执行并记录每个任务步骤;(4) 交叉验证,第二位注释者审查任务轨迹以确保其准确性。
自主和手动过程的结合产生了10.5k条轨迹和94.3k个步骤。我们使用来自ANDROID-LAB基准中包含的应用程序的726条轨迹和6208个步骤进行训练。图5提供了Android Instruct数据集的统计信息,更多详细信息见附录C。
注释
-
页面信息获取:ADB+无障碍模式,让注释者方便知道获取xml时机。
-
操作轨迹记录:我们需要主要记录三种用户动作:点击、滑动和文本输入。对于点击和滑动动作,注释者直接在手机上完成这些操作,而工具则记录下这些动作。对于文本输入,我们使用ADB命令来模拟键盘输入,以确保准确记录。为了确保每一步操作的准确性,我们设置了一个3秒的间隔,让虚拟机有足够的时间响应每个操作。
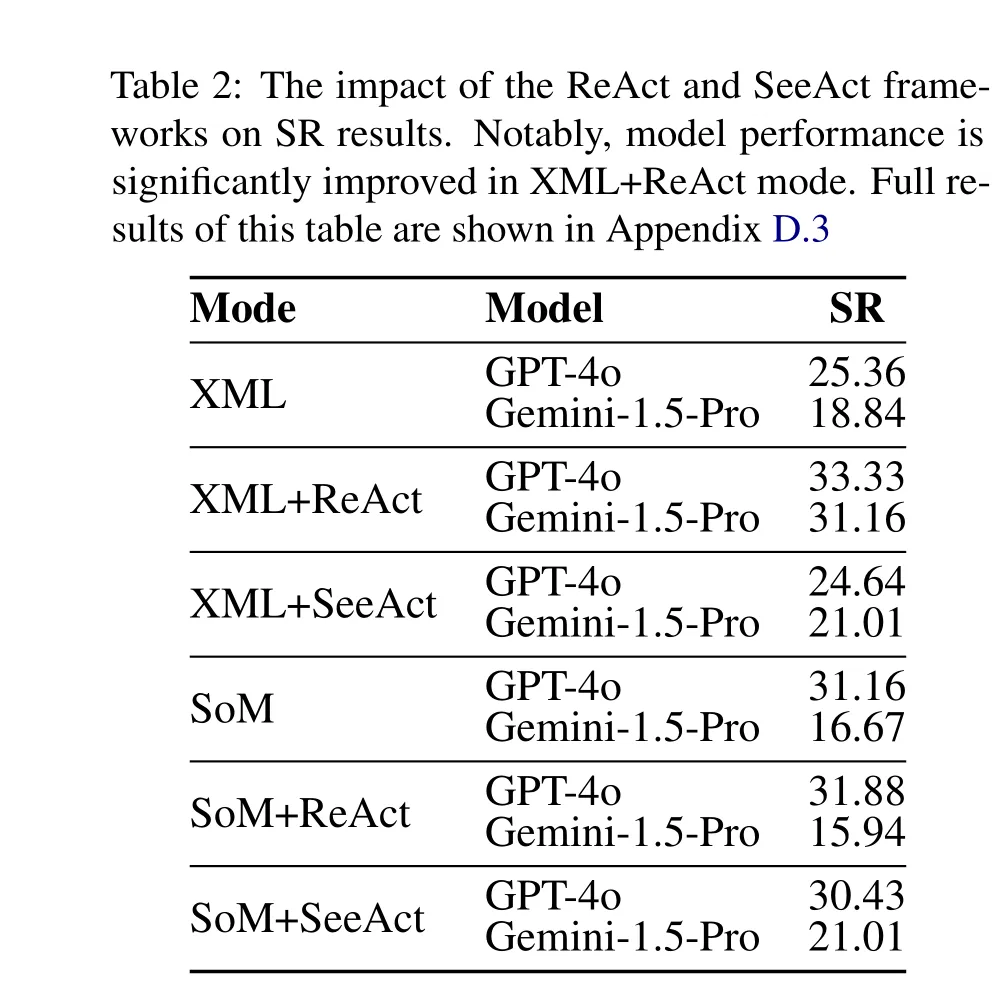
值得注意的是,在XML+ReAct模式下,模型性能显著提升。
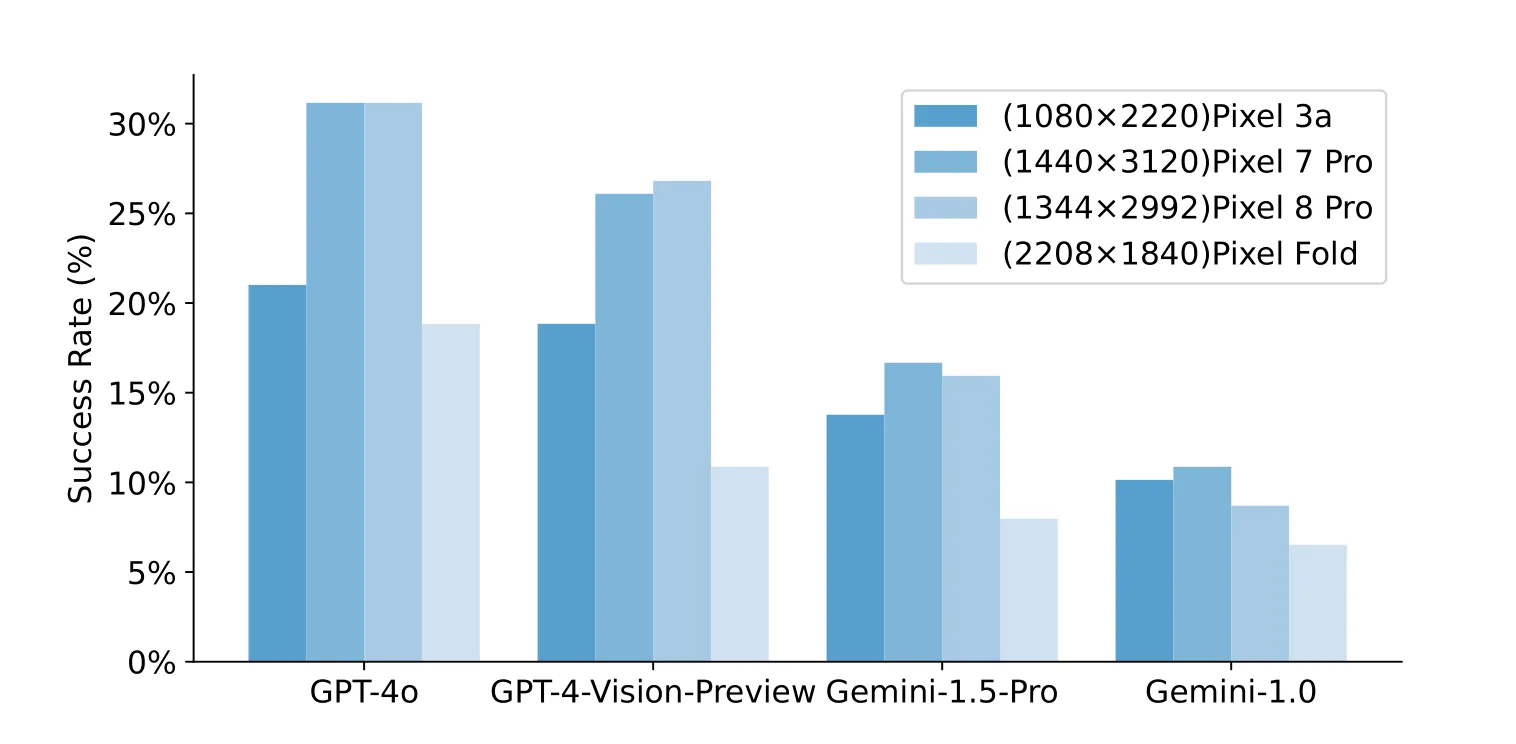
手机屏幕大小影响
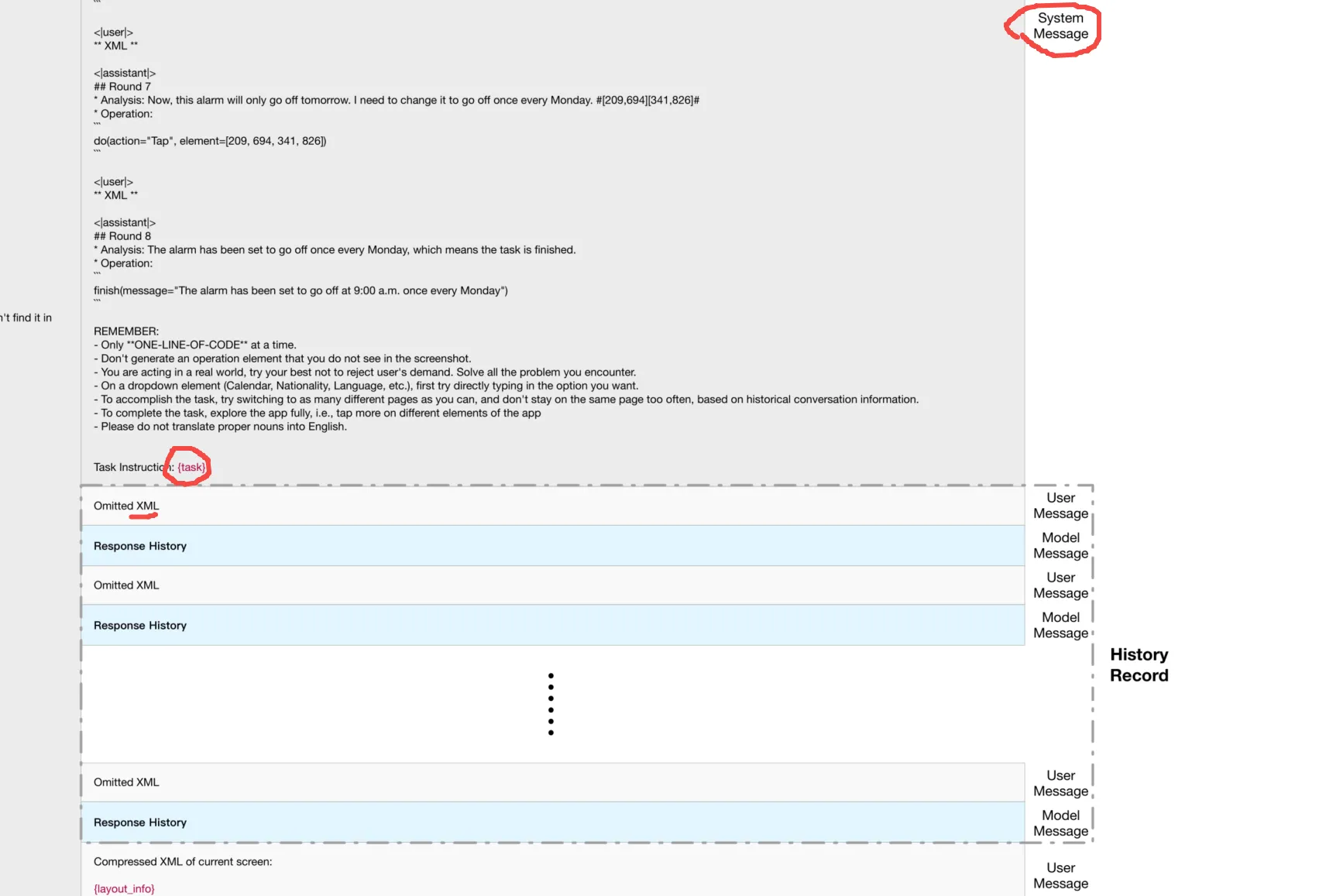
xml操作
在Android移动设备上执行单个操作。 参数:
action(str): 指定要执行的操作。有效选项包括:"Tap"(点击)、"Type"(输入文本)、"Swipe"(滑动)、"Long Press"(长按)、"Home"(返回主屏幕)、"Back"(返回上一级)、"Enter"(确认)、"Wait"(等待)。element(list, 可选): 定义操作的屏幕区域或起始点。- 对于 "Tap" 和 "Long Press",提供坐标 [x1, y1, x2, y2] 来定义从左上角 (x1, y1) 到右下角 (x2, y2) 的矩形区域。
- 对于 "Swipe",可以提供坐标 [x1, y1, x2, y2] 定义滑动路径,或者仅提供起始点 [x, y]。如果未指定,默认为屏幕中心。
关键字参数:
text(str, 可选): 要输入的文本。在 "Type" 操作中必需。direction(str, 可选): 滑动方向。有效选项包括:"up"(向上)、"down"(向下)、"left"(向左)、"right"(向右)。如果操作为 "Swipe",则必须指定此参数。dist(str, 可选): 滑动距离,可选值为 "long"(长距离)、"medium"(中等距离)、"short"(短距离)。默认值为 "medium"。如果操作为 "Swipe" 且指定了方向,则必须指定此参数。
返回:
- None。执行操作后,设备状态或前台应用程序状态将被更新。
python展开代码def finish(message=None):
"""
终止程序。在退出前可选择打印提供的消息到标准输出。
参数:
- `message` (str, 可选): 在退出前要打印的消息。默认为 None。
返回:
- None
"""
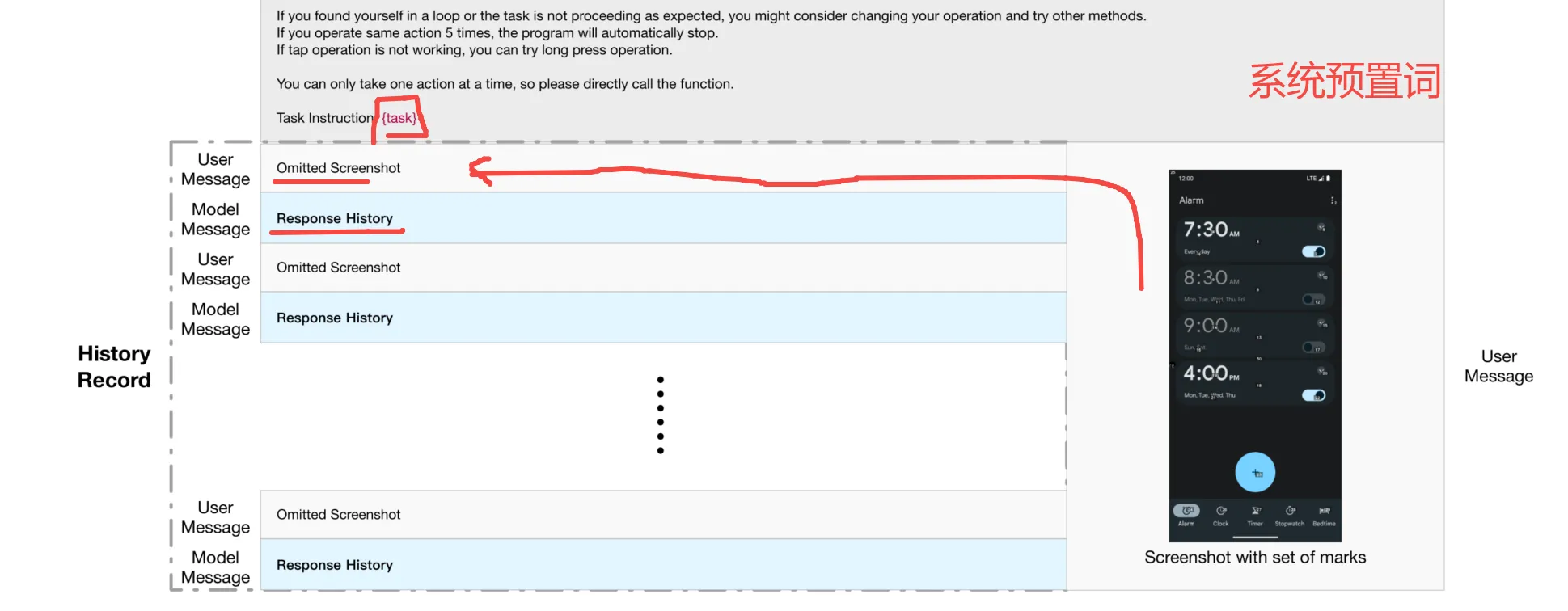
ReAct+XML
其实就是Figure 7。
ReAct+SoM
其实就是Figure 8。
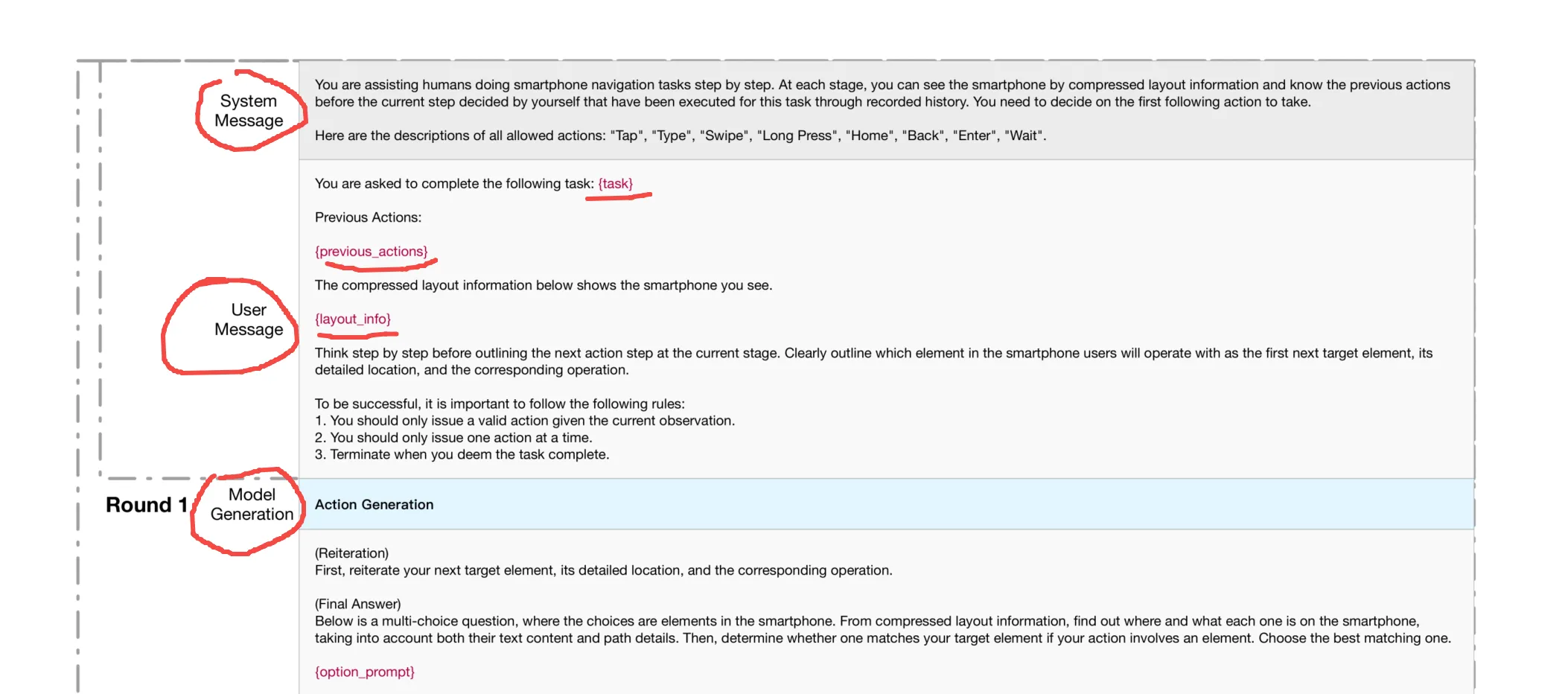
SeeAct+SoM
类似Figure 9,和ReAct类似,但是有点不一样。
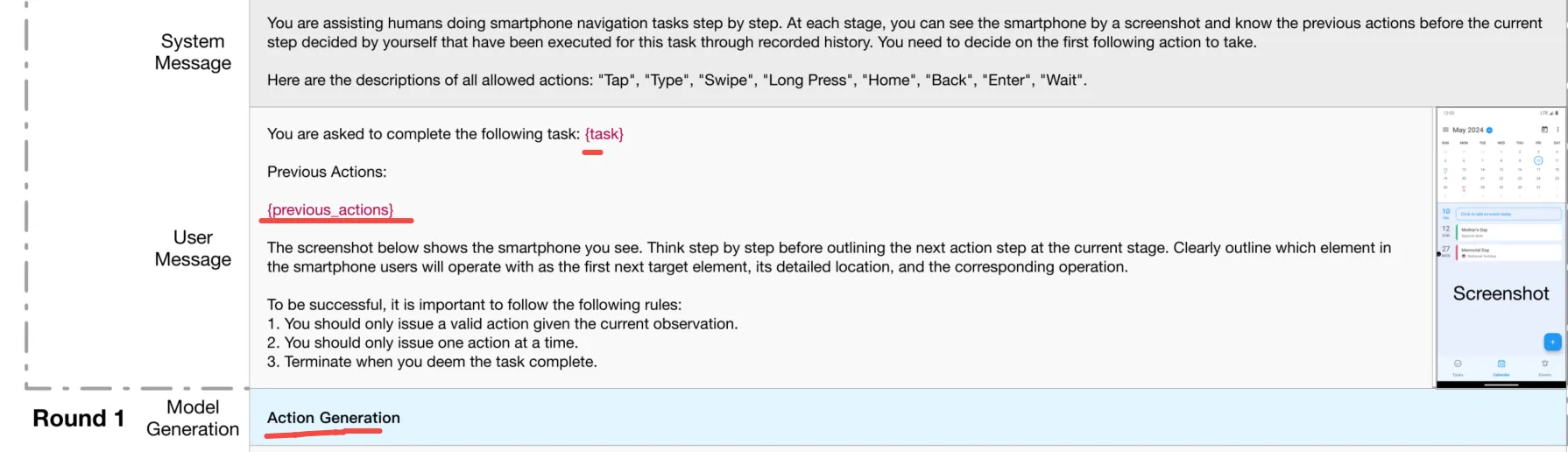
SeeAct+XML
类似Figure 10,和ReAct类似,但是有点不一样。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!