目录
https://arxiv.org/abs/2405.20797
https://github.com/AIDC-AI/Ovis
摘要
当前的多模态大语言模型(MLLMs)通常通过连接器(如MLP)将预训练的大语言模型(LLM)与视觉变换器结合,从而赋予LLM视觉能力。然而,视觉编码器生成的连续嵌入与基于嵌入查找表的结构化文本嵌入之间的不匹配,给视觉与文本信息的无缝融合带来了挑战。
为了解决这个问题,本文提出了 Ovis,一种新型的多模态大语言模型架构,旨在结构性地对齐视觉和文本嵌入。Ovis通过在视觉编码器的过程中集成一个额外的可学习视觉嵌入表,提升视觉信息的表示能力。每个图像块通过多次索引视觉嵌入表来生成最终的视觉嵌入,这种方法是对文本嵌入生成方法的结构性模仿,从而能够捕捉丰富的视觉语义信息。
实验证明,Ovis在多个多模态基准测试上表现优于同参数规模的开源多模态大语言模型,甚至在整体表现上超越了专有模型Qwen-VL-Plus。这些结果展示了Ovis在视觉表示结构化设计上的潜力,有助于推动多模态学习的发展。
下图的b就是Ovis,多了一个VET映射结构。

Ovis:基于结构化视觉嵌入的多模态大语言模型架构
随着大语言模型(LLM)的快速发展,朝着通用人工智能(AGI)迈进,视觉理解成为实现AGI的重要能力之一。因此,基于语言理解与视觉感知相结合的多模态大语言模型(MLLMs)应运而生。当前开源的多模态大语言模型主要通过预训练的LLM和视觉编码器结合,使用不同的标记化和嵌入策略进行训练。然而,这种架构中的标记化差异可能限制其性能。
Ovis架构的提出:为了解决上述问题,Ovis提出了一种新颖的MLLM架构。Ovis借鉴LLM的思路,通过结构化的视觉嵌入表来处理视觉输入,使视觉嵌入与文本嵌入策略相匹配。具体而言,Ovis引入了一个可学习的视觉嵌入查找表,将视觉编码器输出的连续视觉标记映射为概率标记,并在视觉嵌入表中进行多次索引,从而得到一个组合的视觉嵌入。该方法使得视觉嵌入的结构性与文本嵌入一致,增强了视觉-语言任务的表现。
性能提升与优化:Ovis架构通过联合文本生成损失函数进行优化,避免了传统方法中使用自动编码器或向量量化等技术的复杂性。通过这种方式,Ovis在多个多模态基准测试中表现出色,尤其是在与同一参数规模的开源MLLMs对比时,Ovis-8B和Ovis-14B在大多数基准测试中均超越了竞争者。值得注意的是,Ovis-14B在性能上也超越了高资源私有模型Qwen-VL-Plus,并在MMStar、MMBench等通用和专门的多模态基准测试中与Qwen-VL-Max模型的表现不相上下。
总结:Ovis通过采用结构化视觉嵌入和创新的训练方法,显著提升了多模态大语言模型的性能,展示了其在视觉-语言任务中的强大潜力。其成功不仅突出了Ovis架构的优势,也为未来多模态大语言模型的设计和优化提供了新的思路。
相关工作综述
-
大型语言模型(LLMs):近年来,LLM的快速发展显著推动了自然语言处理领域的进步。GPT-3的发布引发了性能的大幅提升,尤其是在少样本和零样本学习中。此后,ChatGPT、GPT-4、Gemini等模型进一步展示了LLM的潜力。开源模型如LLaMA、Mistral也迅速跟进,甚至在某些情况下超过了闭源模型。然而,LLMs本身缺乏处理多模态数据的能力,这限制了其在需要理解文本之外信息的场景中的应用。
-
多模态大型语言模型(MLLMs):MLLMs不仅能理解和生成文本,还能关联和解读视觉信息。现有的开源MLLMs主要由视觉编码器、连接器和LLM组成。连接器方法有跨注意力、查询方法和投影方法等。当前研究聚焦于高分辨率能力、小型化、多模态集成等方向。
-
视觉标记化(Visual Tokenization):视觉输入的标记化在多种视觉任务中已有探索,VQVAE和VQGAN等方法通过离散潜变量和对抗训练提高了生成效果。最近,BEIT等方法使用离散的视觉标记进行预训练,但与语言模型结合的研究相对较少。提出的方法通过优化视觉头层并引入专门的视觉嵌入表,以改进视觉标记化过程。
这些研究推动了LLM和MLLM的进展,尤其是在图像和文本的联合理解方面,为多模态应用提供了新的架构设计。
Ovis架构与训练策略
在这一部分,文章介绍了视觉与文本嵌入策略的差异,并提出了Ovis架构,旨在融合视觉与文本信息,提升多模态语言模型(MLLM)的性能。具体来说,Ovis采用了一种线性映射方法来处理概率性视觉标记,并引入了额外的视觉嵌入查找表来优化视觉信息的表示。
3.1 视觉与文本标记的差异
- 图像处理:图像输入首先被划分为若干个视觉补丁,每个补丁通过预训练的视觉变换器(ViT)处理,生成一系列的视觉表示。
- 文本处理:文本输入则由大语言模型(LLM)处理,文本和视觉标记在处理时需要转化为相同的形式。
- 由于视觉和文本标记的维度差异,传统方法使用线性投影、MLP或变换器等方法来将视觉标记转化为与文本标记相同的形式。
3.2 概率性视觉标记
- 视觉标记转化:Ovis采用了一种新的方式,将视觉标记转化为离散的概率性视觉标记。通过一个线性头部,将连续的视觉标记转换为一个概率分布,这种分布代表了视觉词汇中的不同视觉词。
- 该方法通过softmax归一化将视觉标记映射到视觉词汇中的概率空间,以此捕捉更丰富的视觉语义。
3.3 视觉嵌入查找表
- 嵌入表示:类似于文本模型中常见的文本嵌入表,Ovis引入了一个视觉嵌入查找表,每个视觉词都与一个嵌入向量相关联。通过结合多个视觉词的加权平均,Ovis能够获取一个更为丰富和语义化的视觉表示。
- 该方法通过从视觉词汇中选取多个视觉词,并利用其对应的嵌入向量的加权组合,生成最终的视觉补丁嵌入。
3.4 Ovis的训练策略
Ovis的训练分为三个阶段,每个阶段侧重不同的目标:
- 阶段一:冻结大部分模型参数,仅训练视觉编码器和视觉嵌入表。使用图像标题数据集(如COYO)进行训练,目的是为Ovis学习图像的基础视觉表示。
- 阶段二:在冻结LLM的情况下,进一步训练视觉编码器和嵌入表,使用视觉描述数据集(如ShareGPT4V-Pretrain)来增强Ovis的图像描述能力。
- 阶段三:解冻LLM模块,使用多模态指令数据集(如LLaVA-Finetune)对Ovis进行微调,使其能够更好地执行和理解多模态指令。
通过这种多阶段的训练策略,Ovis能够有效地融合视觉和文本信息,并提升其在多模态任务中的表现。
Ovis架构的实验评估与结果
4.1 实验设置
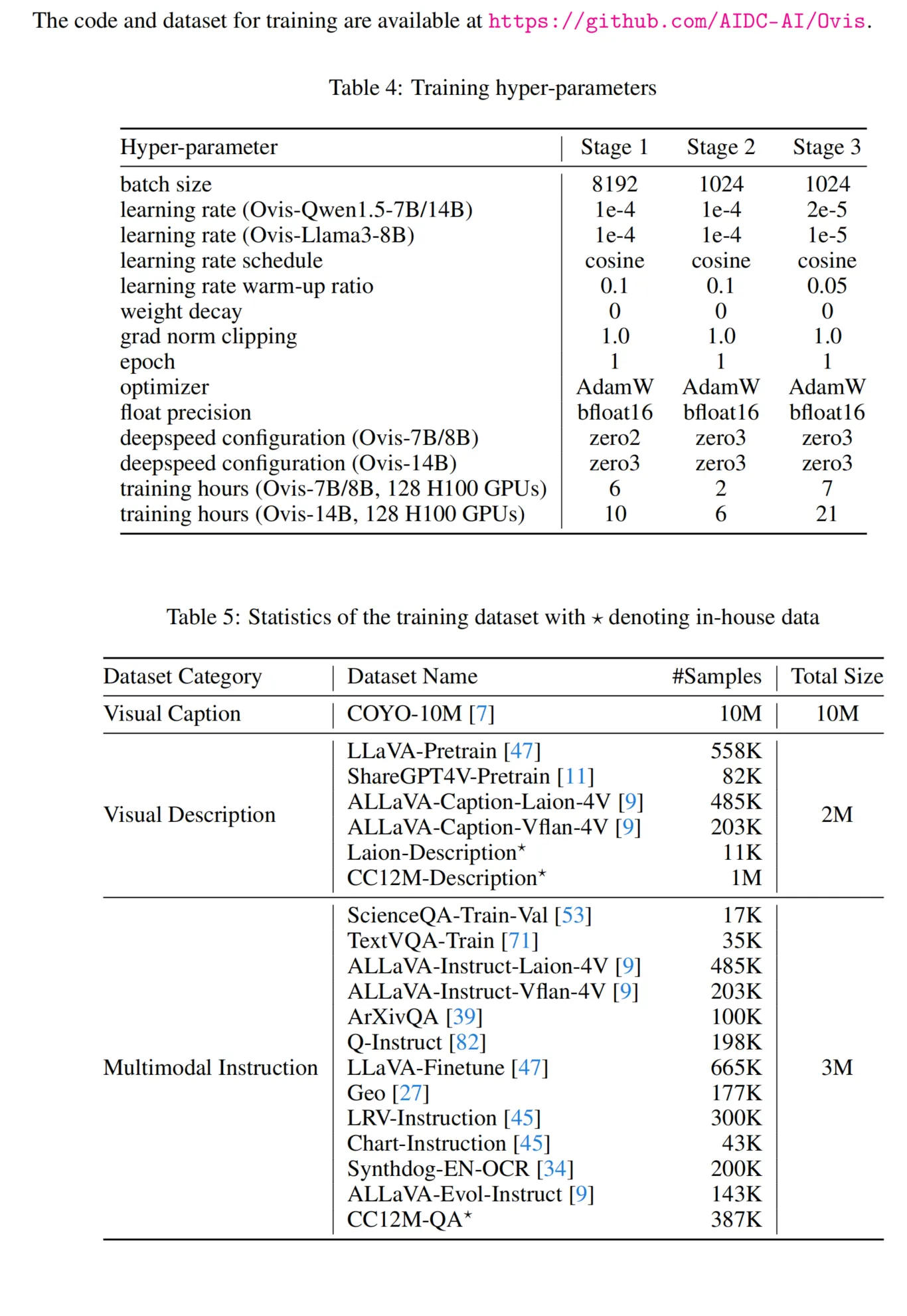
Ovis架构包括三个关键配置:LLM模块、ViT骨干网络和视觉词汇大小。使用了开源LLM(如Qwen1.5-Chat和Llama3-Instruct)以及ViT(如Clip-ViT-L/14@336px),视觉词汇大小设置为131,072。Ovis的训练代码基于流行的Transformers和DeepSpeed框架。数据集包括视觉标题、视觉描述和多模态指令,分别用于训练的不同阶段。
4.2 主要实验结果
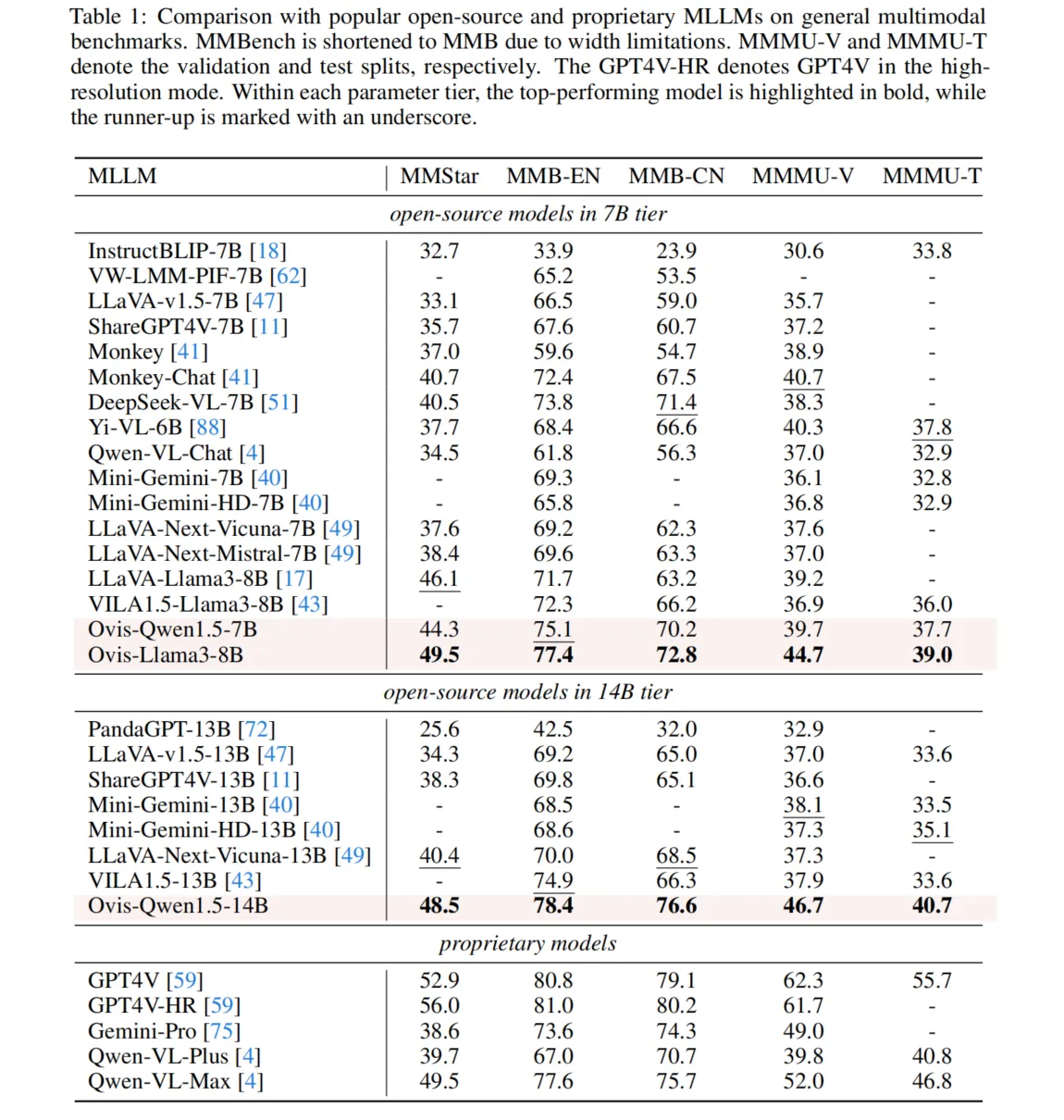
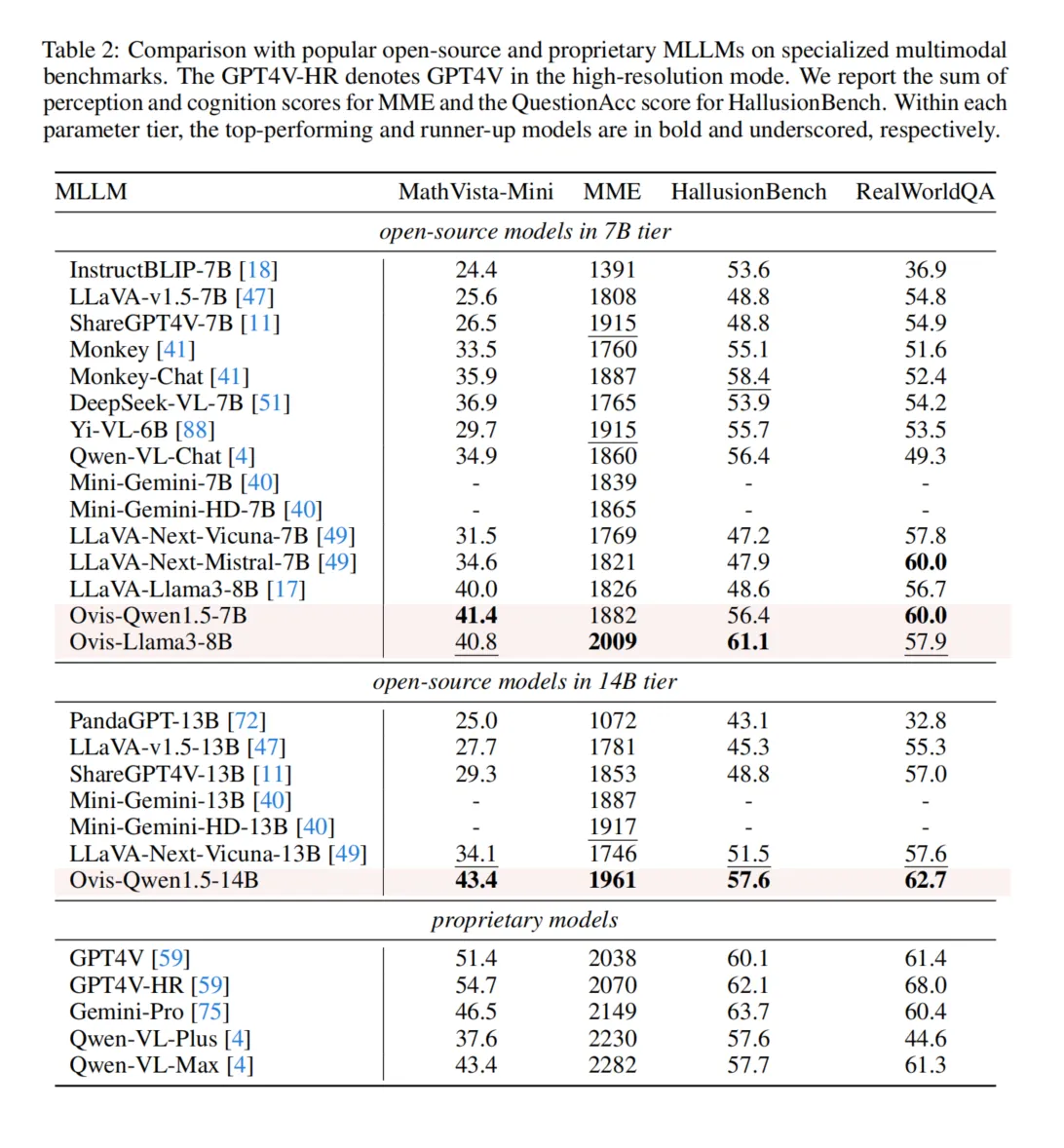
Ovis在多个标准基准上表现出色,涵盖了通用多模态能力(如MMMU、MMBench-EN、MMBench-CN等)和专业多模态任务(如MathVista-Mini、RealWorldQA等)。Ovis-8B在多数基准上超越了相同规模的开源模型,而Ovis-14B在所有基准上均表现优异,尤其在视觉信息利用上,比同类专有模型Qwen-VL-Plus更具优势。Ovis在视觉必需的多模态基准MMStar上展现出较大的优势,并在挑战性的大学级MMMU基准上表现出强大的视觉理解与推理能力。此外,Ovis-14B在MMBench-EN和MMBench-CN的表现也表明其在英语和中文两种语言的多模态能力都很突出。
在专业多模态任务中,Ovis在数学和逻辑推理方面优于开源竞争者,特别是在MathVista-Mini基准上的表现。此外,尽管Ovis使用的是较低分辨率的ViT骨干网络,但在高分辨率的RealWorldQA基准上,Ovis-14B的表现超过了领先的专有模型GPT4V,展示了其卓越的实际视觉任务处理能力。
4.3 消融实验
通过与连接器基础的MLLM进行对比实验,Ovis在所有基准上的表现均优于连接器模型,尤其在参数数量相同的情况下,Ovis表现出平均8.8%的性能提升。这进一步证明了Ovis架构设计的有效性。
结论
本文强调了在多模态大语言模型(MLLMs)中,视觉嵌入与文本嵌入结构对齐的重要性。由于视觉和文本的标记化及嵌入策略不同,我们在Ovis中引入了额外的视觉嵌入查找表。图像块被映射为概率性标记,然后索引到视觉嵌入表中,并以与文本嵌入类似的结构方式进行转换。通过在多个多模态基准测试中的实证评估,Ovis的有效性得到了验证,结果表明Ovis在性能上超越了同规模的开源MLLMs,并优于专有模型Qwen-VL-Plus。
更广泛的影响与局限性
更广泛的影响:作为一种强大的多模态大语言模型架构,Ovis能够通过增强视觉内容与文本分析之间的互动,惠及广泛的用户。然而,也需要注意Ovis可能带来的负面影响,例如生成虚假或不准确的信息(幻觉现象),从而导致误信息的传播。此外,Ovis也存在偏见和潜在的危害,这是生成模型的普遍问题。这些负面影响可以通过内容审核机制和透明的模型开发来减轻。
局限性:尽管Ovis展现了良好的性能,但在处理高分辨率图像的视觉任务时仍存在局限,主要是因为缺乏高分辨率增强技术。此外,Ovis仅使用单图像样本进行训练,面对需要跨多图像理解的场景时,表现有限。已有大量研究致力于这些问题,尤其是基于连接器的框架。未来,我们计划借鉴这些研究,提升Ovis在处理高分辨率图像和多图像输入方面的能力。
Training Details
C. 自建视觉描述数据集
本文从Laion和CC12M数据集中采样图像,涵盖自然、生活方式、人文学科、建筑、卡通和抽象艺术等多个类别。对于每张图像,使用Gemini-Pro或GPT-4V API生成描述。生成的描述要求简洁明了,尽量避免夸张和解释,如图像描述可能包括场景细节、人物服饰、环境特点等。这些描述的生成通过统一的提示词进行,确保图像信息的清晰表达和相关的OCR识别。
D. 自建视觉指令数据集
在自建视觉指令数据集中,我们为CC12M数据集中的图像生成了自问自答任务。使用Gemini-Pro和GPT-4V API,生成了多样化的问题和高质量的答案。这些问题包括对图像内容的深入分析,如人物服饰、物品设计、历史背景等,帮助模型理解并回答有关图像的复杂问题。该方法产生了具有丰富语义和推理能力的视觉指令,提升了数据集的多样性和深度。
E. Ovis视觉标记器的稀疏性
为评估Ovis视觉标记器的稀疏性,本文使用了从ImageNet-1K数据集中采样的10,000张图像进行实验。每张图像通过Ovis-Llama3-8B的视觉标记器进行标记,得到一系列视觉标记,每个标记都是一个概率分布。通过设定不同的阈值(1e-4、1e-5、1e-6),统计概率值的分布情况。实验结果表明,Ovis的视觉标记器具有高度的稀疏性,超过1e-4的概率值仅占0.22%,大部分概率值集中在较低区间。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!