目录
mobile-agent : autonomous multi-modal mobile device agent with visual perception
这是v1版本
https://arxiv.org/abs/2401.16158
摘要
基于多模态大语言模型(Multimodal Large Language Models, MLLM)的移动设备代理正在成为一种流行的应用。在本文中,我们介绍了一种自主多模态移动设备代理——Mobile-Agent。Mobile-Agent 首先利用视觉感知工具精确识别并定位应用前端界面中的视觉和文本元素。基于视觉上下文的感知,Mobile-Agent 然后自主规划并分解复杂的操作任务,逐步引导完成移动应用中的操作。不同于依赖应用 XML 文件或移动系统元数据的早期解决方案,Mobile-Agent 采用以视觉为核心的方法,能够在不同的移动操作环境中更具适应性,从而无需特定系统的定制化支持。为了评估 Mobile-Agent 的性能,我们引入了 Mobile-Eval,一个用于评估移动设备操作的基准。基于 Mobile-Eval,我们对 Mobile-Agent 进行了全面的评估。实验结果表明,Mobile-Agent 在操作准确性和完成率方面表现显著,即使面对多应用操作等复杂指令,Mobile-Agent 依然能够完成要求。代码和模型已开源于 https://github.com/X-PLUG/MobileAgent。
1 引言
基于大语言模型(LLM)的代理(如 Li 等 [2023],Liu 等 [2023a,b,c],Shen 等 [2023],Wu 等 [2023],Yang 等 [2023a],Shen 等 [2024],Yang 等 [2023b],Hong 等 [2023],Yang 等 [2023c])利用各种工具,展现出强大的任务规划和推理能力。随着多模态大语言模型(Multimodal Large Language Models, MLLM)Liu 等 [2023d],Zhu 等 [2023],Ye 等 [2023a],Dai 等 [2023],Liu 等 [2023e],Chen 等 [2023],Ye 等 [2023b],Bai 等 [2023],Lin 等 [2023] 的快速发展以及其出色的视觉理解能力的提升,基于 MLLM 的代理的实现成为可能,并激发了多种创新应用的潜力。
近期,移动设备代理成为 MLLM 代理的一种新颖且流行的应用形式。该代理需要基于屏幕内容和用户指令来操作移动设备。这要求代理具备视觉感知和语义理解能力。然而,现有的 MLLM,包括先进的 GPT-4V,仍然缺乏足够的视觉感知能力,无法作为有效的代理。Zheng 等 [2024] 指出,尽管 GPT-4V 可以生成有效的操作指令,但它难以精确定位这些操作在屏幕上的位置。这一局限阻碍了仅通过先进的 MLLM 实现移动设备操作的可能性。
为了解决这一问题,现有研究尝试通过用户界面布局文件来辅助 GPT-4V 实现定位。例如,Yang 等 [2023d] 通过访问 Android 应用的 XML 文件提取屏幕上的可操作位置;Zheng 等 [2024] 利用网页应用的 HTML 代码来辅助定位。然而,这些方法依赖于底层文件的可访问性,但在许多场景中,可能无法获得访问这些文件的权限,导致这些方法无效。
为了解决现有定位方法对底层文件的依赖,本文提出了 Mobile-Agent,这是一种具备视觉感知能力的自主移动设备代理。Mobile-Agent 通过视觉感知模块,仅利用移动设备的截图来精确定位操作位置。视觉感知模块包含检测模型和 OCR 模型,分别负责描述局部屏幕区域的内容并识别屏幕中的文本。通过精心设计的提示词,我们促进了代理与工具之间的有效交互,从而实现移动设备操作的自动化。利用 GPT-4V 强大的上下文理解能力,Mobile-Agent 实现了基于截图、用户指令和操作历史的自主任务规划能力。为了增强代理识别错误操作和不完整指令的能力,我们引入了一种自我反思方法。在提示词的引导下,代理能够持续反思无效或错误的操作,并在指令完成后自动停止操作。
为了全面评估 Mobile-Agent 的能力,我们引入了 Mobile-Eval,一个围绕当前主流移动应用的基准。Mobile-Eval 包含了不同难度等级的指令。我们基于 Mobile-Eval 对 Mobile-Agent 进行了分析,展示并分析了其中的一些案例。实验结果表明,Mobile-Agent 在指令完成率和操作准确性方面表现出色,即使在复杂的多应用操作指令下,Mobile-Agent 也能够成功完成任务。
总结如下:
- 我们提出了 Mobile-Agent,一种自主移动设备代理。Mobile-Agent 利用视觉感知工具进行操作定位,能够自主规划每一步并完成自我反思。Mobile-Agent 仅依赖设备截图,不需要任何系统代码,是一种纯视觉的解决方案。
- 我们引入了 Mobile-Eval,一个用于评估移动设备代理的基准。该基准包括 10 个常用应用,提供了三种不同难度等级的指令。
- 我们基于 Mobile-Eval 对 Mobile-Agent 进行了全面分析,展示了典型的案例以分析其能力。
2 移动代理(Mobile-Agent)
本节介绍我们的移动代理框架(Mobile-Agent)。该框架包括最先进的多模态大模型(MLLM)GPT-4V、用于文本定位的文本检测模块以及用于图标定位的图标检测模块。我们将首先解释如何使用视觉工具将GPT-4V生成的指令定位到移动设备上的具体位置。随后,我们将描述Mobile-Agent的工作流程。
2.1 视觉感知(Visual Perception)
GPT-4V的定位能力不足
尽管GPT-4V可以对指令和截图提供正确的操作,然而,已有研究(Zheng et al. [2024])表明,GPT-4V无法有效输出操作发生的位置。因此,我们需要借助外部工具来帮助GPT-4V进行操作定位,以便将操作结果输出到移动设备屏幕上。
文本定位(Text Localization)
当代理需要点击屏幕上的特定文本时,我们使用OCR工具来检测该文本在屏幕上的位置。我们将讨论以下三种场景:
-
场景1: 当OCR检测结果中不包含指定文本时,代理将被指示重新选择文本进行点击,或选择替代操作。这种情况通常出现在复杂场景中,GPT-4V可能会产生少量幻觉(hallucinations)。
-
场景2: 当OCR检测结果中仅包含一个实例的指定文本时,我们直接生成一个操作,以点击该文本框的中心坐标。
-
场景3: 当OCR检测结果中包含多个实例的指定文本时,我们评估结果的数量。如果实例数量较多,这表明当前屏幕上存在太多相似内容,代理难以做出选择。在这种情况下,我们要求代理重新选择要点击的文本。如果实例数量较少,我们会将这些区域裁剪出来并在其上绘制检测框。然后,我们使用这些裁剪区域让代理选择点击哪个实例。在裁剪时,我们会将文本检测框向外扩展一定范围,并在这些裁剪后的图像上绘制检测框,以保留更多信息并便于代理决策。该流程如图2的左上部分所示。
图标定位(Icon Localization)
当代理需要点击图标时,我们使用图标检测工具和CLIP(Radford et al. [2021])来定位其位置。具体而言,我们首先要求代理提供要点击的图标的属性,包括颜色和形状。随后,我们使用Grounding DINO(Liu et al. [2023f])并带有“icon”的提示词来识别截图上的所有图标。最后,通过CLIP,我们计算所有检测到的图标与点击区域描述的相似度,选择相似度最高的区域进行点击。该流程如图2的右上部分所示。
2.2 指令执行(Instruction Execution)
操作定义(Operation)
为了更好地将代理输出的动作转换为屏幕上的操作,我们为Mobile-Agent定义了8种操作:
- Open App (App):打开桌面页面上的特定App。
- Click the text (Text):点击屏幕上“Text”文本所在的区域。
- Click the icon (Icon, Position):点击“Position”中的“Icon”描述的区域。“Icon”提供点击位置的描述,包括颜色、图标形状等属性。“Position”需从顶部、底部、左侧、右侧或中心中选择一个或两个选项,以减少错误的可能性。
- Type (Text):将“Text”输入到当前的输入框中。
- Page up & down:用于在当前页面上滚动上下移动。
- Back:返回上一页面。
- Exit:从当前页面直接返回到桌面。
- Stop:在指令完成后,结束整个流程。
自我规划(Self-Planning)
Mobile-Agent通过迭代方式逐步完成每一步操作。在迭代开始前,用户需要输入指令。我们根据指令生成整个流程的系统提示。在每次迭代开始时,我们截取当前手机屏幕的截图并提供给代理。代理在观察系统提示、操作历史和当前屏幕截图的基础上,输出下一步的操作。如果代理的输出是结束流程,则迭代停止;否则,进入新一轮的迭代。Mobile-Agent利用操作历史来了解当前任务的进展,并基于系统提示,在当前截图上生成操作,从而实现一个迭代的自我规划过程。该过程如图2底部所示。
自我反思(Self-Reflection)
在迭代过程中,代理可能会遇到错误,导致无法完成指令。为了提高指令完成的成功率,我们引入了自我反思方法。该方法在以下两种情况下生效:
- 情况1:当代理生成错误或无效的操作,导致流程卡住时。如果代理注意到在执行某个操作后截图没有变化,或者截图显示错误页面,我们会指示代理尝试其他操作或修改当前操作的参数。
- 情况2:当代理可能忽略复杂指令中的某些要求时。在代理通过自我规划完成所有操作后,我们会指示代理分析操作、历史记录、当前截图和用户指令,以确定是否已完成指令。如果未完成,代理需要通过自我规划继续生成操作。该过程如图2底部所示。
提示格式(Prompt Format)
为了更好地实现上述功能,我们借鉴了ReAct的提示格式,要求代理输出三个组件:Observation、Thought和Action。
- Observation:代理对当前截图和操作历史的描述。这有助于代理注意到截图中的更新,并基于历史记录快速识别错误。
- Thought:代理基于Observation和指令对下一步操作的考虑。代理需要在Thought中描述即将执行的操作。
- Action:代理根据Thought选择八种操作中的一种并确定相应参数。
这种格式使得代理能够更清晰地执行指令,提高操作的准确性和成功率。
3 实验
在本节中,我们将对Mobile-Agent进行全面的评估。由于Android操作系统具有便捷的操作调用接口,我们选择在Android上进行实验。我们将在未来的研究中探索其他操作系统。
我们的实验主要分为两部分:定量实验和定性实验。在定量实验中,我们将使用我们提出的Mobile-Eval基准对Mobile-Agent进行评估。在定性实验中,我们将分析具体案例。
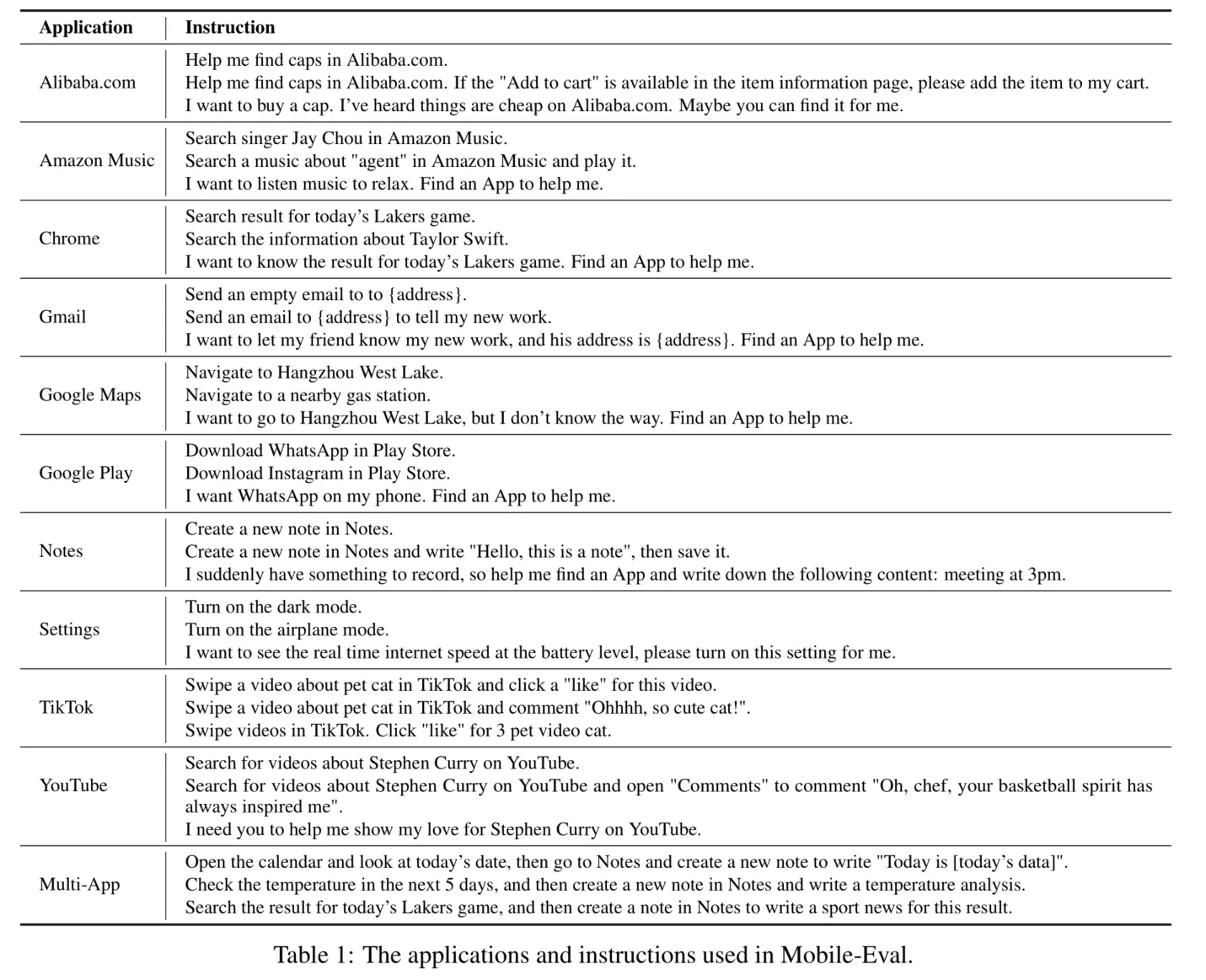
3.1 设置
Mobile-Eval
为了全面评估 Mobile-Agent 的能力,我们引入了 Mobile-Eval,这是一个基于当前主流应用程序的基准测试。Mobile-Eval 包含了移动设备上常用的 10 个应用程序。为了评估代理的多应用使用能力,我们还设计了需要同时使用两个应用程序的指令。每个应用程序我们设计了三条指令。第一条指令相对简单,仅要求完成基本的应用操作。第二条指令在第一条的基础上增加了一些额外要求,使其更具挑战性。第三条指令是抽象的用户指令,用户没有明确指定使用哪个应用或执行什么操作,而是让代理自主判断。表 1 展示了 Mobile-Eval 中使用的应用程序和指令。
评估指标
我们设计了四个指标来从不同角度评估 Mobile-Agent 的表现:
- Success (Su):如果 Mobile-Agent 完成了指令,则被认为成功。
- Process Score (PS):该指标衡量每个指令执行步骤的准确性,具体来说,是正确步骤的数量除以总步骤数。即便代理在某些指令中未能最终成功,每个正确步骤仍为 Planning Score 做出贡献。
- Relative Efficiency (RE):我们手动执行了每条指令,并记录了人类完成所需的步骤数,作为最优解。我们将 Mobile-Agent 所执行的步骤数与人类的步骤数进行比较,以展示 Mobile-Agent 是否能更高效地使用移动设备。
- Completion Rate (CR):计算 Mobile-Agent 能够完成的人类操作步骤数除以人类执行的总步骤数,以展示 Mobile-Agent 对某一指令的完成率。如果指令完成,则该指标等于 1。
3.2 定量结果
我们在表 2 中展示了实验结果。首先,对于三种指令,Mobile-Agent 的完成率分别达到了 91%、82% 和 82%。尽管有些指令未能成功执行,但三种类型指令的完成率均超过了 90%。其次,从 PS 指标可以看出,Mobile-Agent 在三种指令中具有较高的正确操作概率,约为 80%。最后,RE 指标显示,Mobile-Agent 能够实现达到人类最优操作的 80% 的能力。以上结果共同表明了 Mobile-Agent 作为移动设备助手的有效性。
值得注意的是,一些指令的 PS 值未达到 1,这表明 Mobile-Agent 可能会执行一些无效或错误操作。然而在这些情况下,大多数指令仍然最终完成。这表明 Mobile-Agent 具备良好的自我反思能力,即便存在无效或错误操作,它能够基于截图进行反思,最终纠正其错误。这对于移动设备代理至关重要,因为和人类一样,它们无法保证所有操作都是正确的,代理必须具备纠错能力。
3.3 案例分析
在图 3 中,我们展示了 Mobile-Agent 理解用户指令并自主规划操作的能力。尽管指令中可能没有包含具体的操作,Mobile-Agent 成功理解了用户的需求,并将其转化为具体的可执行操作。随后,代理通过一系列规划步骤完成了指令。
在图 4 中,我们展示了 Mobile-Agent 面对无效或错误指令时的反思能力。在这个案例中,Mobile-Agent 初始使用了无效操作,导致截图没有变化。在反思后,Mobile-Agent 纠正了错误,继续操作,最终完成了指令。图 5 展示了另一个案例。在连续两次无效或错误操作的情况下,Mobile-Agent 能够迅速纠正操作,确保整个流程的顺利执行。
在图 6 和图 7 中,我们展示了 Mobile-Agent 在涉及跨多个应用程序操作场景中的能力。这要求代理具备一定的记忆能力,以便在两个应用程序之间实现信息传递。从案例中可以看出,Mobile-Agent 能够准确地将第一个打开的应用程序中的信息传递到第二个应用程序,并生成再处理后的内容。
在图 8 中,我们展示了 Mobile-Agent 的多语言能力。尽管 GPT-4V 在处理中文方面可能存在一些限制,但其强大的视觉感知能力使其能够有效应对简单的中文场景。通过观察用户视频演示和使用用户文档,代理经过一定程度的探索后,能够对可操作区域形成足够的理解,从而能够根据指令执行正确的操作。
5 结论
在本研究中,我们介绍了 Mobile-Agent,这是一种自主的多模态代理,能够通过统一的视觉感知框架操作广泛的移动应用程序。Mobile-Agent 使用视觉感知工具,能够准确识别并定位应用程序界面中的视觉和文本元素。借助感知到的视觉上下文,Mobile-Agent 能够自主规划、分解复杂任务,并逐步导航移动应用程序。与依赖 XML 移动系统元数据的先前解决方案不同,Mobile-Agent 以视觉为中心的方式提供了更强的跨各种移动操作环境的适应性,避免了系统特定的定制需求。通过实验,我们展示了 Mobile-Agent 在各个维度上的有效性和效率,这表明它作为一个多功能且适应性强的解决方案,具备以语言无关的方式与移动应用程序交互的潜力。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!