目录
https://arxiv.org/html/2410.14881v1
强大的内容审核分类器对生成式AI系统的安全至关重要。内容审核,或称为安全分类,一直以来都充满模糊性:安全与不安全输入之间的差异通常非常微妙,使得分类器(甚至是人类)在缺乏进一步上下文或解释的情况下,很难正确地区分违规样本和正常样本。此外,随着这些技术在各种应用和用户群体中不断部署,通过持续的模型微调来扩展风险发现和缓解的难度与成本也越来越大。
为应对这些挑战,我们提出了一种基于Retrieval-Augmented Generation (RAG)的分类方法,即Class-RAG。Class-RAG通过访问可动态更新的检索库,扩展了其基础大语言模型(LLM)的能力,从而实现了语义热修复(semantic hotfixing),以便灵活、即时地缓解风险。与传统的微调模型相比,Class-RAG在决策过程中表现出更大的灵活性和透明性。实证研究表明,Class-RAG在分类任务上表现更为出色,且对对抗性攻击更加鲁棒。此外,我们的研究结果表明,Class-RAG的性能随检索库规模的增长而提升,这意味着增加检索库的规模是一种可行且低成本的提升内容审核能力的方式。
1 引言
生成式AI技术的最新进展催生了新一代的产品应用,例如文本生成 (OpenAI, 2023; Anthropic, 2023; Dubey, 2024)、文本生成图像 (Ramesh et al., 2021; Dai et al., 2023; Rombach et al., 2022) 和文本生成视频 (Meta, 2024)。因此,模型开发的速度必须与安全系统的发展相匹配,以确保能够有效缓解新出现的危害,并确保系统的整体完整性。这一点至关重要,以防止生成式AI产品被恶意使用,如传播虚假信息、美化暴力、以及传播性内容 (Foundation, 2023)。
传统的模型微调方法常用于这一目的,通过对标注的内容审核文本数据进行学习,分类器可以作为这些部署系统的“护栏” (OpenAI, 2023)。然而,使用传统的模型微调方法来自动化内容审核任务面临诸多挑战。首先,内容审核是一个高度主观的任务,导致标注数据中的标注者一致性较低,因为政策指南的解释可能有多种不同的版本,尤其是在边界模糊的案例中 (Markov et al., 2023)。其次,无法实施一个通用的危害分类法,这不仅是由于任务的主观性,还因为系统需要扩展到新的区域、新的受众和新的用例,这些新场景有不同的指南和基于这些指南定义的不同危害梯度 (Shen et al., 2024)。由于内容审核任务的主观性以及结构化标注数据在捕捉这种主观性方面的局限性,训练一个鲁棒的内容审核分类器已十分具有挑战性。当分类器需要持续进行微调以适应不断变化的安全风险时,挑战进一步增加。
为了解决因规模化带来的主观性和灵活性问题,我们提出了一种基于Retrieval-Augmented Generation (RAG)的分类方法,即Class-RAG,该方法通过添加上下文信息以引发内容分类的推理。虽然RAG(Lewis et al., 2020)通常用于知识密集型任务,但我们发现它在处理模糊任务时也非常有用。我们的内容审核系统由一个嵌入模型、一个包含负面和正面示例的检索库、一个检索模块和一个经过微调的LLM分类器组成。当用户输入查询时,我们会检索最相似的负面和正面示例,并将从类似检索到的查询中提取的上下文信息丰富到原始输入中,再送入分类器进行处理。
主要贡献
我们的主要贡献如下:
-
提升分类性能
在实验中,Class-RAG相比于仅微调基于内容审核数据预训练的轻量级4层Transformer模型,或微调通用8b参数的大语言模型(LLM),展示了更优越的分类性能。 -
增强灵活性
通过具有易于更新的检索库,Class-RAG实现了低成本的定制,能够无缝适应政策变化,而不需要重新训练模型。通过实现语义(而非硬性)屏蔽,该系统可以更精确地识别和过滤敏感内容。 -
可扩展性和成本效益
我们的研究表明,Class-RAG的性能随着检索库规模的增长而提高,说明增加检索库规模是提升分类性能的一种可行且低成本的方法。
2 相关工作
内容审核
在过去十年中,随着通信技术的创新,大量工作致力于减少不良内容的传播。机器学习方法已被提出用于解决情感分类 (Yu et al., 2017)、骚扰检测 (Yin et al., 2009)、仇恨言论检测 (Gambäck and Sikdar, 2017)、滥用语言检测 (Nobata et al., 2016) 和有害言论检测 (Adams et al., 2017)。深度学习的总体改进也加速了内容审核领域的发展。WPIE(Whole Post Integrity Embeddings)基于BERT和XLM,在自监督学习的进展基础上构建,能够通过预训练的通用内容表示获得对帖子的整体理解 (Schroepfer, 2019)。更近期的生成式AI进展也引发了一个问题,即LLMs是否可以作为内容审核员 (Huang, 2024)。
生成式AI的安全性
生成式AI的兴起不仅带来了仇恨言论或有害内容检测外的危害类型,其缓解措施和基准测试也需要进一步的研究与探索。一个全面的AI危害分类法包括如学术不诚信、未经授权的隐私侵犯以及未经同意的裸露等危害类别 (Zeng et al., 2024)。随着生成式AI安全性缓解方法的增多,建立现有分类器有效性的基准测试也在不断增多,例如UnsafeBench (Qu et al., 2024)。类似于I2P (Schramowski et al., 2023a)的基准测试包含约4.5k个真实世界的英文文本生成图像的提示词,以及P4D (Chin et al., 2024),该基准通过红队策略自动检测不安全输出,提供了有价值的数据集,用于评估如自我伤害、非法活动、性内容和暴力内容等有害类别。
RAG及其应用
尽管大语言模型(LLMs) (OpenAI, 2023; Anthropic, 2023; Dubey, 2024) 的基础能力非常强大,但LLMs存在已知的局限性,如生成幻觉的倾向 (Huang et al., 2023),缺乏为其生成内容提供可解释解释的能力,并且受到其训练数据截止日期的限制。Retrieval-Augmented Generation (RAG) (Lewis et al., 2020) 通过使用检索机制增强大型预训练语言模型的基础能力,以提供显式的非参数记忆 (Zhao et al., 2024),从而缓解了一些问题。RAG通常用于扩展LLMs的能力,尤其是在知识密集型任务中 (Gao et al., 2024)。RAG方法的灵活性使其能够应用于不需要额外领域微调的场景,例如在计算机视觉领域中自适应检测器模型 (Jian et al., 2024)。例如,RAFT提高了模型在开放书目领域的解答能力 (Zhang et al., 2024)。
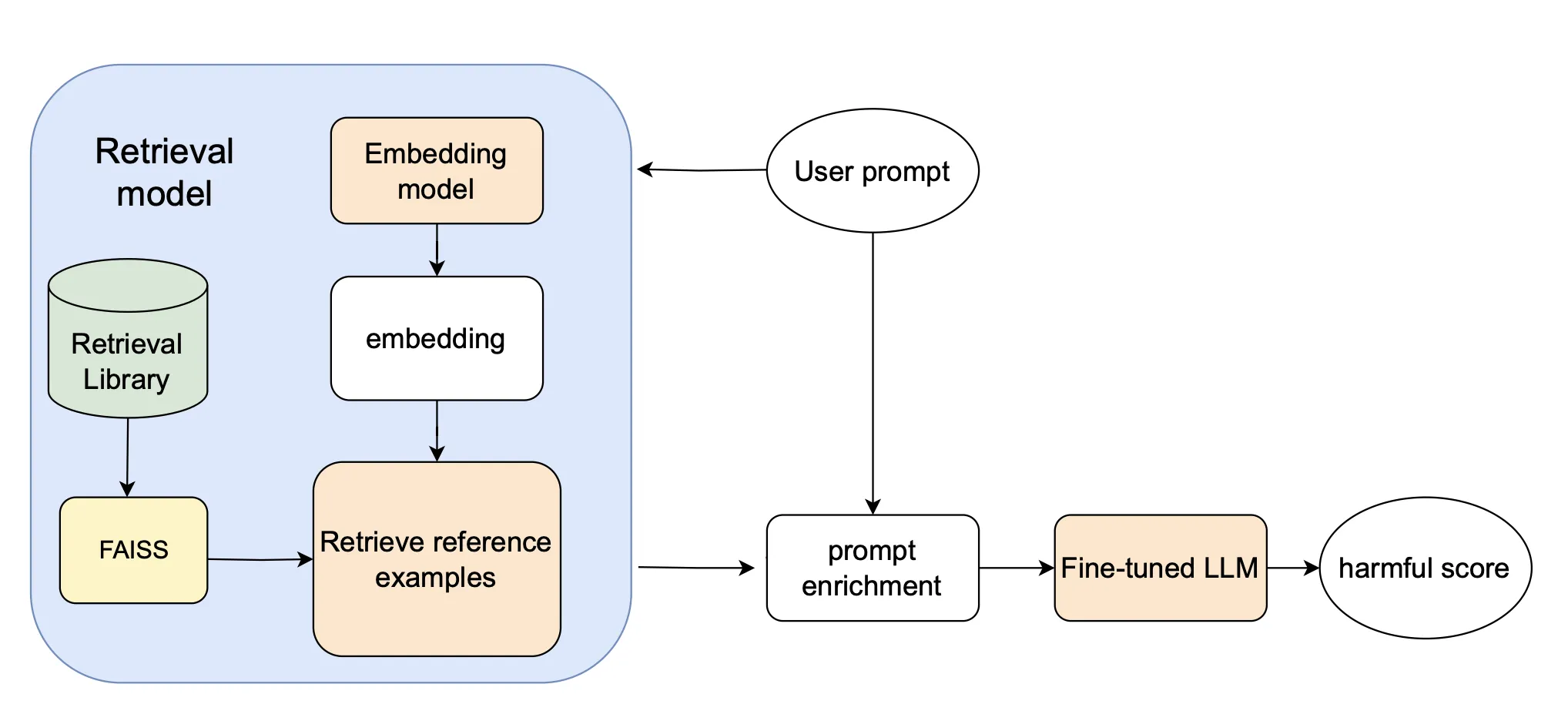
3 系统架构
Class-RAG是一个由四部分组成的系统,包含嵌入模型、检索库、检索模块和经过微调的LLM分类器。当用户输入一个提示时,系统会通过嵌入模型计算该提示的嵌入向量。用户输入的嵌入向量会与检索库中的嵌入索引进行比较,这些嵌入索引对应着检索库中的正面和负面提示示例。我们使用Faiss(一个用于高效相似性搜索的库)(Douze et al., 2024),从中检索与用户输入嵌入最相似的k个参考示例,然后将这些参考示例与输入提示一起传递给微调的LLM进行分类。我们使用CoPro数据集 (Liu et al., 2024) 来训练和评估我们的模型。
3.1 嵌入模型
我们采用了DRAGON RoBERTa (Lin et al., 2023) 作为主要的嵌入模型。DRAGON是一个双编码器密集检索模型,它利用双编码器架构将查询和文档嵌入到密集的向量表示中,从而促进相关信息的高效检索。在本研究中,我们特别使用了DRAGON模型的上下文编码器部分。为了探讨替代嵌入模型对我们方法的影响,我们还评估了WPIE (Whole Post Integrity Embedding) (Meta, 2021) 的一个变体。我们测试的WPIE模型是一个4层的XLM-R (Conneau et al., 2020) 模型,该模型已经在内容审核数据上进行预训练,并产生两个不同的输出:一个是不安全概率估计,另一个是提示的嵌入表示。
3.2 检索库
我们的检索库由两个不同的子库组成:一个安全库和一个不安全库。检索库中的每个条目由四个属性组成,包括:(1) 提示,(2) 标签,(3) 嵌入,(4) 解释。检索库的构建将在数据准备部分中详细描述。
3.2.1 检索模块
给定选择的嵌入,我们利用Faiss库 (Douze et al., 2024) 进行相似性搜索,从检索库中高效检索出最相近的两个安全示例和两个不安全示例。具体来说,我们使用L2距离度量来计算输入嵌入与检索库中存储的嵌入之间的相似性,从而识别出最相关的示例。
3.3 LLM 分类器
受LlamaGuard (Inan et al., 2023) 启发,分类器是在OSS Llama-3-8b (Dubey, 2024) 检查点的基础上进行微调的。
4 数据准备
4.1 数据集详情
我们使用CoPro数据集 (Liu et al., 2024) 来训练和评估我们的模型。CoPro数据集由一个分布内测试集(ID)和一个分布外测试集(OOD)组成,这两个测试集都是由一个大语言模型生成的。OOD测试集是基于未见过的种子输入生成的,提供了一个更具挑战性的评估场景。除了CoPro数据集,我们还使用Unsafe Diffusion (UD) (Qu et al., 2023) 和I2P++ (Liu et al., 2024) 数据集来评估模型的泛化能力。I2P (Schramowski et al., 2023b) 仅包含不安全的提示,我们将其与COCO 2017验证集 (Lin et al., 2015) 中的字幕结合(假设所有字幕都是安全的),以创建I2P++数据集。我们将I2P++和UD数据集按30/70的比例拆分为验证集和测试集。源数据集的大小总结见表1。
表 1: 源数据集大小总结
| 数据集 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| CoPro (ID) | 61,128 | - | 16,344 |
| CoPro (OOD) | - | - | 19,652 |
| I2P++ | - | 8,838 | 20,879 |
| UD | - | 426 | 1,008 |
4.2 鲁棒性测试集构建
为了评估模型对抗对抗性攻击的鲁棒性,我们使用Augly库 (Papakipos and Bitton, 2022) 对所有测试集进行了增强,应用了8种常见的混淆技术。这些技术包括:
- change_case: 将
Hello world转换为HELLO WORLD - insert_punctuation_chars: 将
Hello world转换为He’ll’o ’wo’rl’d - insert_text: 将
Hello world转换为PK Hello world - insert_whitespace_chars: 将
Hello world转换为Hello worl d - merge_words: 将
Hello world转换为Helloworld - replace_similar_chars: 将
Hello world转换为Hell[] world - simulate_typos: 将
Hello world转换为Hello worls - split_words: 将
Hello world转换为Hello worl d
4.3 检索库构建
分布内库构建
我们利用CoPro训练集构建了分布内(ID)库,其中每个提示都与特定概念相关联。ID库由两个子库组成:一个用于安全示例,另一个用于不安全示例。为了构建安全库,我们使用K-Means聚类对每个概念的安全示例进行聚类,每个概念生成7个簇,并从每个簇中选择质心示例加入安全子库。我们使用相同的聚类方法来收集不安全示例。这个过程共生成了3,484个安全示例和3,566个不安全示例,组成了分布内检索库。为了进一步增强库在模型推理中的实用性,我们利用Llama3-70b模型 (Dubey, 2024) 为每个示例生成解释文本(如图2所示)。检索库中的每个条目由四个属性组成:提示、标签、解释和嵌入,当从库中选择参考示例时,这些属性将被一起检索。
外部库构建
为了评估模型对外部数据集的适应性,我们使用I2P++和UD数据集构建了一个外部库。我们对这些数据集中的安全和不安全示例应用了K-Means聚类,从I2P++和UD验证集中分别收集了991个安全示例和700个不安全示例。
外部库下采样
为了研究库大小对模型性能的影响,我们通过下采样初始外部库,生成了一系列较小的外部库。具体来说,我们生成了三个较小的库,其大小分别为原库的1/8、1/4和1/2(见表2)。我们通过使用K-Means进一步将全尺寸外部库聚类为更小的组,并选择每个组的质心示例来实现这一下采样。
| 检索库 | 大小 | 安全子库 | 不安全子库 |
|---|---|---|---|
| ID | 7,050 | 3,484 | 3,566 |
| EX | 1,691 | 991 | 700 |
| EX (1/8) | 212 | 125 | 87 |
| EX (1/4) | 425 | 250 | 175 |
| EX (1/2) | 850 | 500 | 350 |
4.4 训练数据构建
我们的训练数据构建过程包含三个关键步骤,这些步骤应用于CoPro训练集中的每个输入提示。首先,我们使用Faiss索引 (Douze et al., 2024) 从分布内检索库中检索参考示例。具体来说,我们为每个输入提示检索4个参考示例,包括2个最近的安全参考示例和2个最近的不安全参考示例。接下来,我们使用Llama-3-70b模型 (Dubey, 2024) 为每个输入提示生成推理过程。此过程考虑输入提示、标签和4个参考示例(2个安全和2个不安全),旨在为模型提供清晰的推理过程供其学习(如图3所示)。最后,我们通过添加特定格式的指令(包括检索到的参考示例和生成的推理过程)来丰富输入文本。这个丰富的提示将用作模型训练的输入(如图4所示)。
我们按照Llama Guard论文 (Inan et al., 2023) 中描述的方法,构建了LLAMA3和Llama-3-8b基线模型的训练数据。本文重点说明了Class-RAG训练和评估数据的构建过程。
4.5 评估数据构建
我们使用与训练数据相同的方法构建评估数据,但有两个关键例外。首先,用于评估的检索库可能与训练中使用的库不同。其次,响应和推理内容不包含在评估数据中(如图5所示)。这使我们能够在更现实的场景下评估模型的性能,同时评估其对新数据的泛化能力。
5 实验
我们进行了全面的实验评估,以评估所提出模型的性能。为了提供全面的比较,我们选择了两个基线模型:WPIE(一个4层XLM-R模型)和LLAMA3(Llama-3-8b),后者根据Llama Guard (Inan et al., 2023) 的设置进行配置。我们的实验评估包括七个不同的部分,具体细节将在后续章节中说明。
实验设置见第5.1节。然后,我们展示了评估结果,重点考察了模型性能的六个关键方面:(1)分类性能及对抗对抗性攻击的鲁棒性(第5.2节);(2)对外部数据源的适应性(第5.3节);(3)执行指令的能力(第5.4节);(4)检索库大小对性能的可扩展性(第5.5节);(5)参考示例数量对性能的影响(第5.6节);以及(6)不同嵌入模型对性能的影响(第5.7节)。
5.1 实验设置
为了进行训练和评估,我们通过向输入文本添加系统指令和参考提示来丰富训练和评估数据。对于训练数据,我们还包括了推理过程,以便模型能够从上下文和提供的解释中学习。
训练配置
我们在Llama-3-8b模型 (Dubey, 2024) 上开发了LLAMA3和Class-RAG模型。两个模型的训练设置相同,使用以下超参数:在配备8个A100 80GB GPU的单台机器上训练,批量大小为1,模型并行度为1,学习率为。我们在不到3.5个GPU小时内完成了单个epoch的训练。
改进的Chain-of-Thought
在训练期间,我们的模型通过利用检索到的参考示例来评估输入文本。我们采用了一种改进的**Chain-of-Thought (CoT)**方法 (Wei et al., 2023)。CoT已被证明可以提高大语言模型的响应质量。与典型的CoT设置不同,后者的答案通过推理过程得出,我们选择将答案放在推理过程之前,以最小化延迟。具体来说,我们强制第一个token为答案,后跟引用和推理部分(如图4所示)。引用部分表明了使用了哪些参考示例进行评估,而推理部分则提供了评估的解释。在评估时,我们只输出单个token,并使用“unsafe”token的概率作为不安全概率。
评估指标
我们采用了**精确-召回曲线下面积(AUPRC)**作为所有实验的主要评估指标。我们选择AUPRC是因为它关注正类的性能,更适合于不平衡数据集的评估。
5.2 分类与鲁棒性
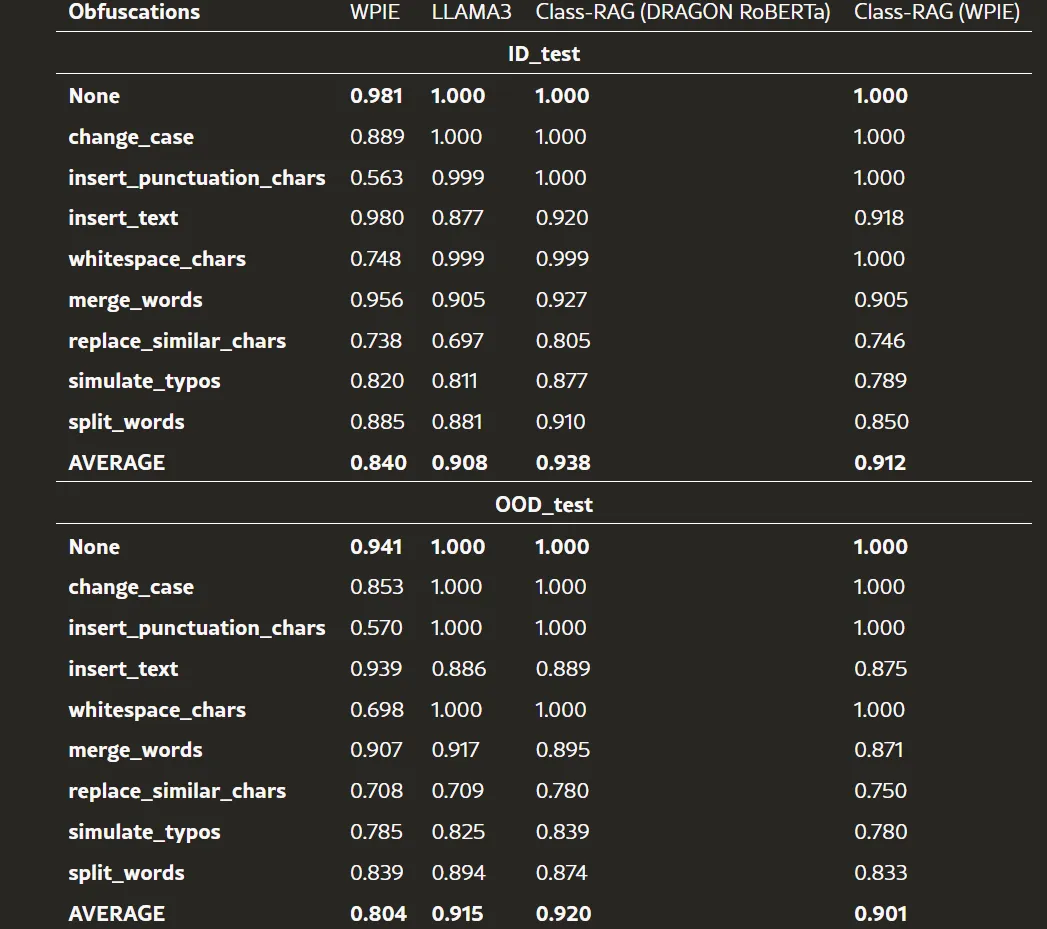
我们对Class-RAG进行了全面评估,将其性能与两个基线模型WPIE和LLAMA3在CoPro的分布内(ID)测试集和分布外(OOD)测试集上进行了比较。为了评估模型对抗对抗性攻击的鲁棒性,我们使用Augly库 (Papakipos and Bitton, 2022) 对测试集进行了8种常见的混淆技术增强。结果如表3所示,表明Class-RAG优于两种基线模型。值得注意的是,LLAMA3
和Class-RAG在分布内和分布外测试集中都获得了1的AUPRC得分,显示出出色的分类性能。然而,Class-RAG (DRAGON RoBERTa)在面对对抗性攻击时表现出比LLAMA3更好的鲁棒性,突显了其在混淆输入的情况下维持性能的能力。
5.3 对外部数据的适应性
Retrieval-Augmented Generation (RAG) 集成到Class-RAG中的一个关键优势在于其无需模型重新训练即可适应外部数据的能力。为了实现这种适应性,新参考示例被添加到检索库中,允许模型利用外部知识。我们在两个外部数据集(I2P++和UD)上评估了Class-RAG的适应性,使用了如数据准备部分所述构建的检索库。具体来说,我们使用了从CoPro训练集中收集的分布内(ID)库,以及从I2P++和UD验证集中收集的外部(EX)库。
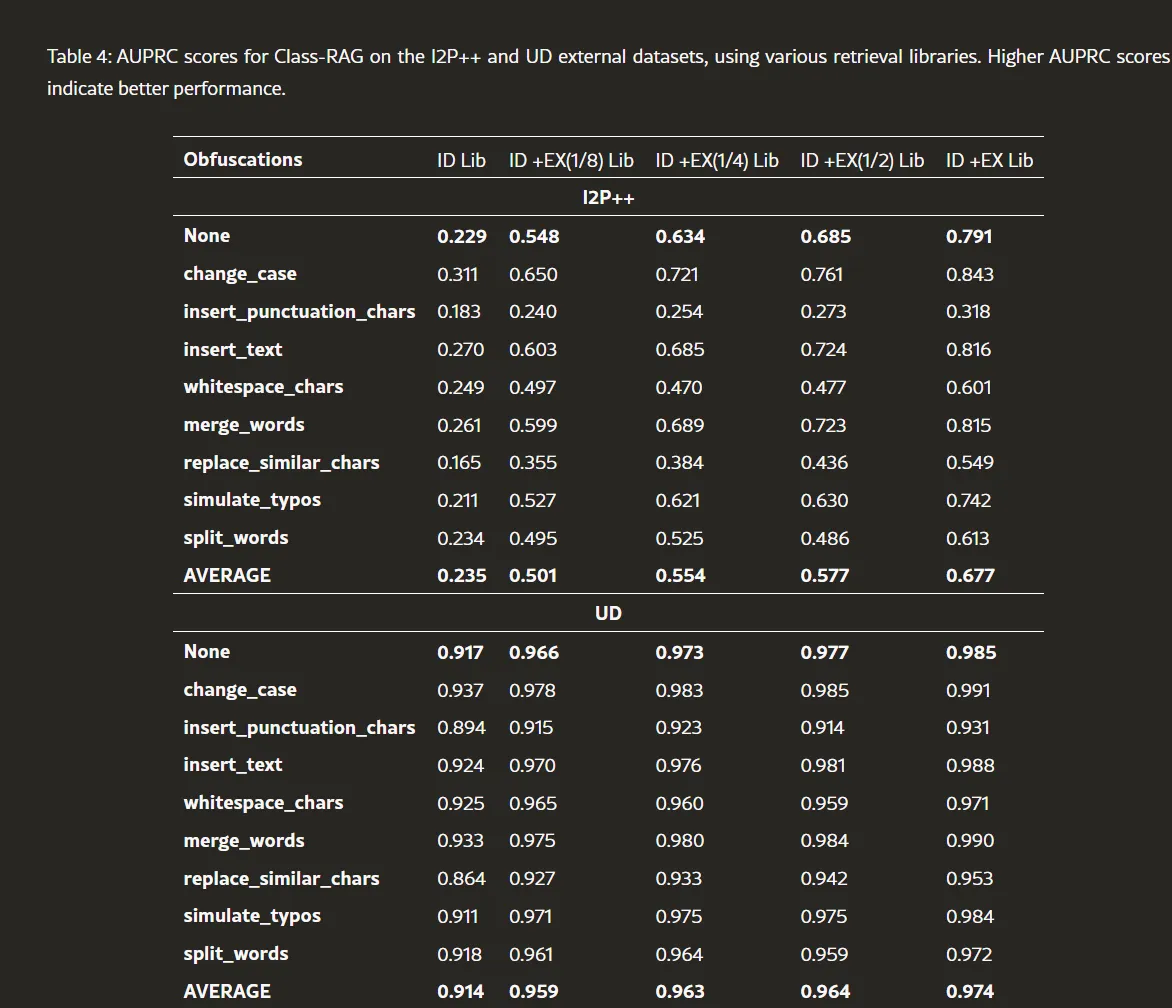
为了评估检索库大小对性能的影响,我们还创建了外部库的缩小版本,分别记为EX (1/8)、EX (1/4) 和 EX (1/2),这些库通过将完整外部库下采样至其原始大小的1/8、1/4和1/2构建。值得注意的是,这种方法确保没有标签泄漏。
表4的结果表明,当仅依赖ID库时,Class-RAG在I2P++数据集上的表现较差,AUPRC得分仅为0.229。然而,通过结合来自完整外部库的新参考示例,AUPRC得分显著提高了245%,达到0.791。此外,模型对抗对抗性攻击的表现也大幅提升,相对提高了188%,从0.235增加到0.677。在UD数据集上,我们观察到了类似的改进,AUPRC得分从0.917提高到0.985,对抗对抗性攻击的表现从0.914提高到0.976。
5.4 指令跟随能力
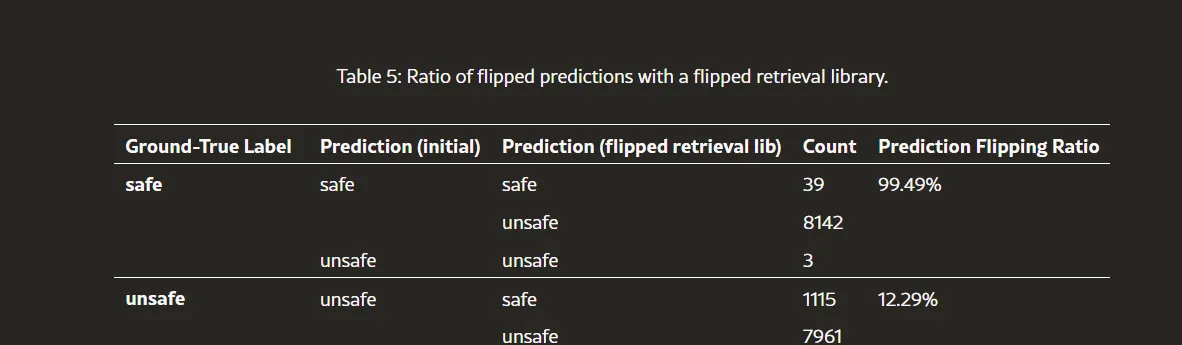
大语言模型(LLM)的指令跟随能力指的是其理解并准确响应给定指令的能力。本节中,我们探讨了Class-RAG在参考示例的指导下生成与这些示例一致的响应能力。为评估这一点,我们使用了ID测试集,其中包含一个翻转标签的ID库。该库与原始ID库中的示例相同,但标签进行了翻转(“unsafe” → “safe”,“safe” → “unsafe”),且移除了解释说明。表5中的结果显示,Class-RAG具备较强的指令跟随能力。值得注意的是,99.49%的真实标签为“safe”的示例成功地从“safe”翻转为“unsafe”,而12.29%的真实标签为“unsafe”的示例也从“unsafe”翻转为“safe”。这种真实标签为“safe”和“unsafe”示例的翻转比例差异,可以归因于Llama3模型的安全微调。该模型旨在避免生成有害的响应,并且已记住了某些不安全内容。
5.5 检索库规模对性能的扩展性
我们进行了研究,以考察检索库规模对Class-RAG性能的影响,结果如表4所示。具体而言,我们使用了从CoPro训练集中收集的in-distribution(ID)库,以及从I2P++和UD的验证集中收集的external(EX)库。为评估检索库规模对性能的影响,我们创建了外部库的缩小版本,分别命名为EX()、EX()和EX(),这些版本是通过重新聚类外部库的全部内容,将其缩减至原始规模的、和。
我们的结果表明,模型性能随着检索库规模的增加而稳定提升。在I2P++数据集上,当添加0、、、和全量外部库时,AUPRC得分分别为0.235、0.501、0.554、0.577和0.677。同样地,在UD数据集上,AUPRC得分从0.914提升至0.959、0.963、0.964和0.974,对应的外部库规模分别为0、、、和全量外部库。
值得注意的是,我们的研究表明,性能随检索库规模的增长而扩展,这表明通过增加库的规模是提升Class-RAG性能的一种有效方法。此外,检索库仅需承担存储和检索索引的成本,这相较于模型训练的成本相对较低。因此,扩大检索库规模是提升模型性能的一种具有成本效益的手段。
5.6 参考示例数量对性能的扩展性
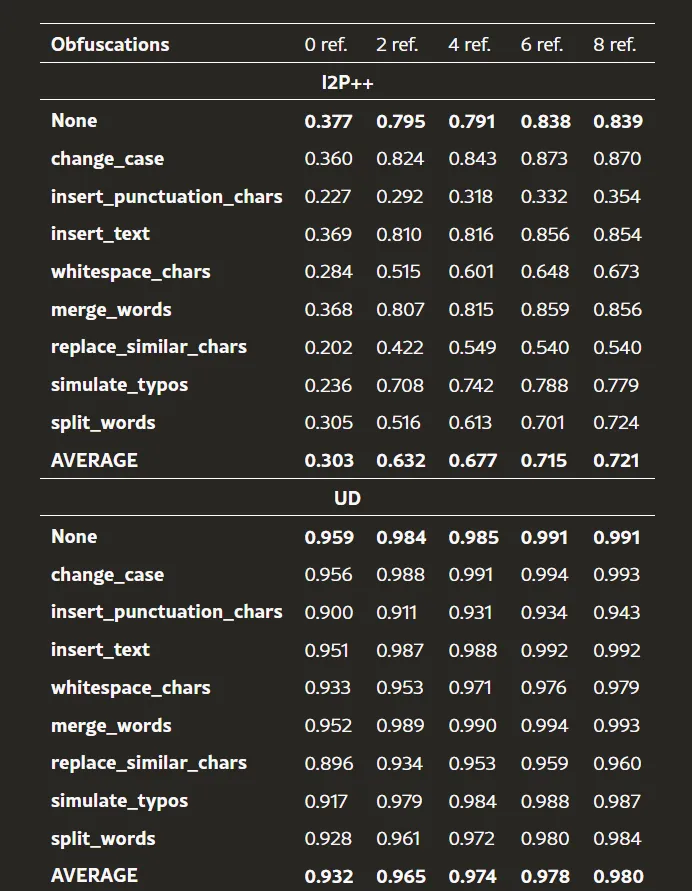
我们进一步研究了参考示例数量对Class-RAG性能的影响。具体来说,我们评估了在添加0、2、4、6和8个参考示例时模型的表现,每种情况下都增加了相同数量的“safe”和“unsafe”示例。表6中的结果表明,Class-RAG的性能随着参考示例数量的增加而持续提升。在I2P++数据集上,当使用0、2、4、6和8个参考示例时,平均AUPRC得分分别为0.303、0.632、0.677、0.715和0.721。同样地,在UD数据集上,平均AUPRC得分从0.932提升至0.965、0.974、0.978和0.980,随着参考示例数量从0增加到2、4、6和8。
虽然结果表明性能随参考示例数量增加而提升,但我们也观察到这一提升在约8个参考示例时趋于饱和。此外,增加更多的参考示例比扩大检索库规模带来更高的计算成本。因此,尽管增加参考示例数量可以提升性能,但需要在此提升和相关的计算开销之间进行平衡。
5.7 不同嵌入模型的性能表现
嵌入模型的选择对于我们所提出的方法中检索相关内容的效果至关重要。在本节中,我们研究了两种不同嵌入模型对Class-RAG性能的影响:DRAGON RoBERTa(Lin et al., 2023)和WPIE。DRAGON是一个双编码器密集检索模型,它将查询和文档嵌入到密集向量中,从而能够在大量文档中有效搜索相关信息。在实验中,我们使用了DRAGON的上下文编码器组件。相比之下,WPIE是一个预训练于安全数据的4层XLM-R(Conneau et al., 2020)模型,产生两个输出:一个“unsafe”概率和一个提示嵌入。
表3中的结果显示,DRAGON RoBERTa嵌入模型的表现优于WPIE。具体而言,DRAGON RoBERTa在ID测试集上的平均AUPRC为0.938,在OOD测试集上的平均AUPRC为0.920,均优于WPIE的表现,后者在ID测试集上获得0.912的AUPRC,在OOD测试集上获得0.901的AUPRC。未来的工作将探索更多先进嵌入模型的有效性,以进一步提升Class-RAG的性能。
6 结论
我们提出了Class-RAG,一个模块化框架,集成了嵌入模型、检索库、检索模块以及经过微调的大语言模型(LLM)。Class-RAG的检索库可以在实际应用中作为一种灵活的“热修复”方法,来减轻即时的危害。通过在分类提示中使用检索到的示例和解释,Class-RAG为其决策过程提供了可解释性,从而促进了模型预测的透明性。全面的评估结果表明,Class-RAG在分类任务上显著优于基线模型,并且在对抗性攻击中表现出较强的鲁棒性。此外,我们的实验表明,Class-RAG能够通过更新检索库有效地整合外部知识,从而实现对新信息的高效适应。我们还观察到,Class-RAG的性能与检索库的规模以及参考示例的数量呈正相关关系。值得注意的是,我们的研究表明,性能随库的规模扩展,这提示了一种新颖且具成本效益的提升内容审核的方式。总之,我们提出了一个稳健、适应性强且可扩展的架构,用于检测生成式AI领域中的安全风险,为减轻AI生成内容中的潜在危害提供了有前景的解决方案。
7 未来工作
未来有几条值得探索的研究方向。首先,我们计划扩展Class-RAG的能力至多模态语言模型(MMLMs),使系统能够有效处理和生成文本以及其他模态的信息。其次,我们在5.4节的分析中发现,Class-RAG在跟随不安全参考示例的指导方面表现优异,但在安全示例上表现欠佳。为了解决这一问题,我们计划研究提升其跟随安全示例的指令能力的方法。此外,我们还打算探索更先进的嵌入模型,评估Class-RAG的多语言能力,并开发更有效的检索库构建方法。这些方向有很大的潜力进一步提升Class-RAG的性能和多功能性。
8 局限性
我们承认使用检索增强生成(Class-RAG)进行稳健内容审核的分类方法存在一些潜在风险和局限性:
- 我们的分类器可能会产生误报或漏报,从而导致意想不到的后果。
- 我们依赖开源的英语数据集,这些数据集可能包含偏见,可能会影响审核决策。这些偏见可能是人口统计学、文化背景或反映某些刻板印象的。例如,我们的模型可能会不成比例地屏蔽某些群体的内容或不公平地审核某些类型的内容。
- 我们模型的常识知识受到其基础模型和训练数据的限制,可能无法在超出其适用范围的知识或非英语语言上表现良好。
- 存在被滥用的风险,例如过度审查或不公平地针对某些用户群体。
- 如果在聊天环境中使用,模型可能会生成不道德或不安全的语言,或易受提示注入攻击。
9 伦理披露
Class-RAG的训练和评估数据中不包含任何能够识别私人个体身份的信息。尽管Class-RAG可以作为AI安全系统的重要组成部分,但它不应作为内容审核决策的唯一或最终裁决者,必须有其他的检查和权衡机制。我们相信,谨慎部署和负责任地使用此技术以减轻风险是非常重要的,并强调单靠模型无法实现完全稳健的内容审核,必须结合人工辅助策略,以缓解偏见。最终,我们强调不断评估和开发模型,以应对潜在的和未来的偏见和局限性。为了更有效地传达我们的想法,本文的部分原始文本在Meta AI的帮助下进行了精炼和综合,然而,原始写作、研究和编码均由我们自主完成。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!