目录
https://arxiv.org/abs/1909.11942
深入解析ALBERT:轻量级的BERT模型
近年来,预训练语言模型在自然语言处理(NLP)领域取得了巨大的成功,其中BERT(Bidirectional Encoder Representations from Transformers)模型尤为突出。然而,随着模型规模的扩大,训练和部署大型模型面临着计算资源和效率的挑战。为了解决这些问题,谷歌研究团队提出了ALBERT(A Lite BERT),一种更高效的BERT变体。本文将深入解析ALBERT的核心思想、技术创新和实验结果。
一、背景介绍
1.1 预训练语言模型的崛起
预训练语言模型通过在大规模无标注文本上进行自监督学习,获取通用的语言表示,然后在下游任务中进行微调。这种方法在多项NLP任务上取得了显著的性能提升。
1.2 BERT的局限性
尽管BERT在各项任务上表现优异,但其庞大的参数量带来了训练和推理效率低下的问题:
- 计算资源需求高:大型模型需要更多的GPU/TPU内存和计算能力。
- 训练速度慢:参数量庞大导致训练时间延长。
- 实际部署困难:在资源受限的环境中,部署大型模型具有挑战性。
二、ALBERT的核心贡献
ALBERT旨在提高参数效率,在不显著降低性能的前提下减少模型参数量,其主要贡献包括:
- 分解嵌入参数化(Factorized Embedding Parameterization)
- 跨层参数共享(Cross-layer Parameter Sharing)
- 句子顺序预测(Sentence Order Prediction,SOP)自监督任务
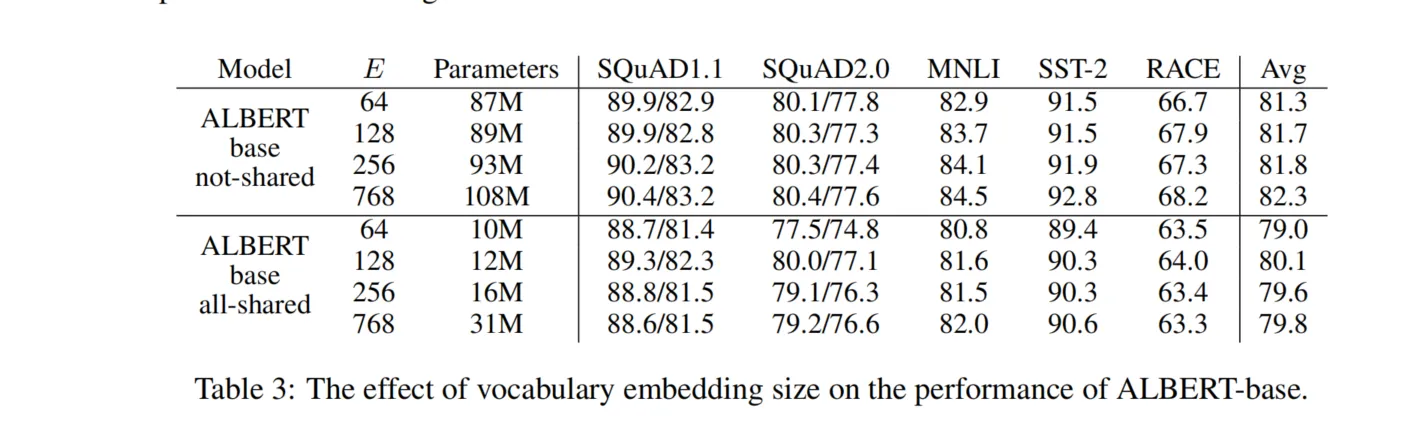
2.1 分解嵌入参数化
问题:在BERT中,词嵌入矩阵的维度与隐藏层大小相同,这导致了巨大的嵌入参数量,特别是对于大型词汇表。
解决方案:ALBERT将词嵌入矩阵分解为两个更小的矩阵:
- 低维词嵌入矩阵(维度为V×E):将词汇表大小V映射到较小的嵌入维度E。
- 嵌入投影矩阵(维度为E×H):将嵌入维度E映射到隐藏层维度H。
通过这种分解,嵌入参数量从O(V×H)减少到O(V×E + E×H),当E远小于H时,可以显著减少参数量。
2.2 跨层参数共享
问题:随着模型深度的增加,参数量也随之线性增长。
解决方案:在ALBERT中,通过在不同的Transformer层之间共享参数,可以防止参数量随着层数的增加而增长。共享方式包括:
- 全部共享:所有层共享相同的参数。
- 部分共享:仅共享特定组件的参数,如前馈网络(FFN)或自注意力(Self-Attention)模块。
2.3 句子顺序预测(SOP)任务
问题:BERT使用的下一句预测(Next Sentence Prediction,NSP)任务被发现效果不佳,主要因为其过于依赖主题预测而非真正的句子间关系。
解决方案:ALBERT引入了SOP任务,强调句子间的连贯性。具体做法是:
- 正样本:从语料中连续抽取的两个句子。
- 负样本:将上述两个句子的顺序交换。
这种设计迫使模型关注句子间的逻辑顺序,而非主题关联。
三、技术细节解析
3.1 分解嵌入参数化的实现
在传统的BERT模型中,词嵌入矩阵直接将词汇表中的每个词映射到隐藏层维度。这意味着嵌入矩阵的参数量为V×H。
在ALBERT中,首先将词映射到一个较低维度的嵌入空间(E维),然后通过一个全连接层将其投影到隐藏层空间(H维)。这种方法带来了以下好处:
- 参数减少:当E远小于H时,参数量大幅减少。
- 解耦表示:词嵌入(词级别的表示)和隐藏状态(上下文相关的表示)被解耦,允许各自专注于不同的学习目标。
3.2 跨层参数共享的策略
ALBERT探索了多种参数共享策略,主要包括:
- 全部共享:所有Transformer层的参数完全共享。
- 仅共享自注意力参数:只共享自注意力模块的参数,前馈网络的参数不共享。
- 仅共享前馈网络参数:只共享前馈网络的参数,自注意力模块的参数不共享。
实验表明,尽管参数共享可能会导致性能略微下降,但在参数效率和性能之间取得了良好的平衡。
3.3 句子顺序预测任务的优势
与NSP相比,SOP任务更关注句子间的逻辑和语义连贯性。NSP任务中的负样本可能来自不同的主题,模型可能仅通过主题差异来区分正负样本,而不需要理解句子间的关系。
SOP通过交换句子顺序,使得负样本保持相同的主题,但逻辑顺序被打乱,迫使模型学习更深入的语义关系。
四、实验结果与分析
4.1 参数效率的提升
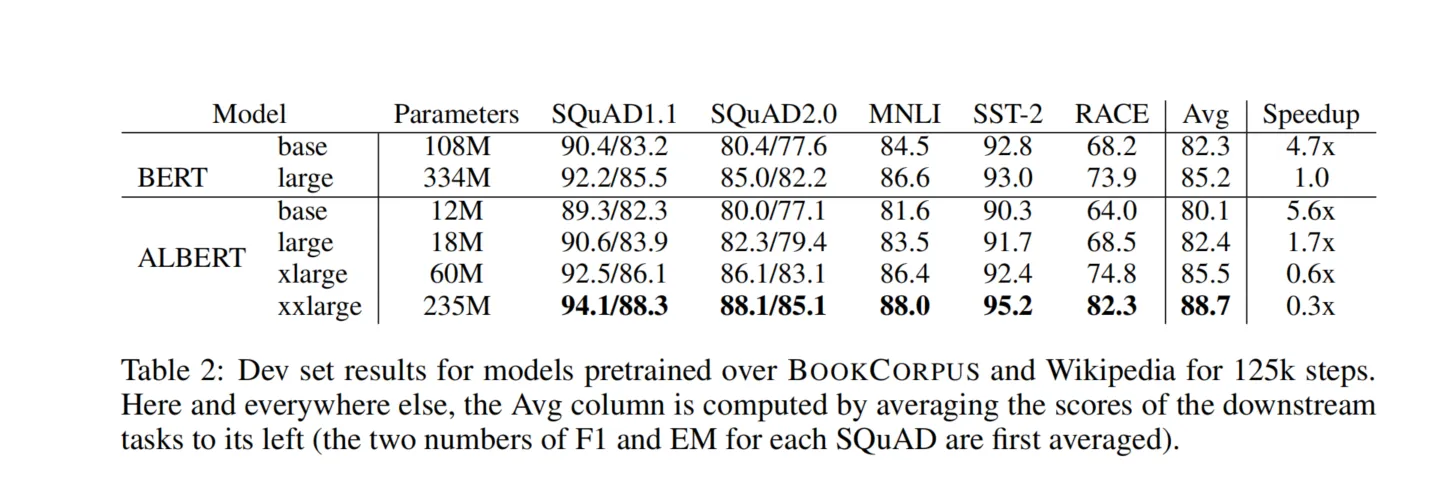
通过上述方法,ALBERT在保持或提升性能的同时,大幅减少了参数量。例如:
- ALBERT-base:参数量从BERT-base的110M减少到12M。
- ALBERT-large:参数量从BERT-large的340M减少到18M。
4.2 在下游任务中的表现
ALBERT在多项NLP基准测试中取得了优秀的成绩,包括GLUE、SQuAD和RACE等。其中:
- GLUE基准:在多个子任务上超过了BERT和其他先进模型的表现。
- SQuAD阅读理解:在SQuAD v1.1和v2.0上取得了更高的精确率和召回率。
- RACE阅读理解:显著提升了模型在复杂阅读理解任务中的表现。
4.3 SOP任务的有效性
实验显示,采用SOP任务的模型在需要句子级别理解的任务上表现更佳,证明了SOP任务在学习句子间关系上的优势。
五、结论与展望
5.1 总结
ALBERT通过创新的模型设计,实现了在参数量和计算效率上的突破:
- 参数大幅减少:通过分解嵌入和参数共享,显著降低了模型的参数量。
- 性能保持或提升:在多项基准测试中,ALBERT的性能与原始BERT持平或更优。
- 更深层次的理解:SOP任务使模型更善于理解句子间的逻辑关系。
5.2 对NLP领域的影响
ALBERT的提出为构建高效的预训练语言模型提供了新的思路,特别是在计算资源有限的情况下,有助于更广泛地应用预训练模型。
5.3 未来方向
- 更广泛的参数共享策略:探索不同的参数共享方式,进一步提高模型效率。
- 结合其他自监督任务:引入更多类型的预训练任务,提升模型的泛化能力。
- 优化模型结构:借鉴ALBERT的思想,设计更高效的Transformer变体。
参考文献
- Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2020). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv preprint arXiv:1909.11942.


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!