目录
https://arxiv.org/abs/2304.12210
1 什么是自监督学习以及为什么要关注它?
自监督学习(Self-supervised Learning),被称为“智能的暗物质”[^1],是推进机器学习发展的有前景的路径。与受限于标注数据的监督学习不同,自监督学习方法可以从大量未标注数据中学习 [Chen et al., 2020b; Misra and Maaten, 2020]。自监督学习(SSL)推动了深度学习在自然语言处理领域的成功,促成了从自动翻译到基于网络规模未标注文本语料库的大型语言模型的进步 [Brown et al., 2020; Popel et al., 2020]。在计算机视觉领域,自监督学习通过诸如SEER等模型在10亿图像上的训练,突破了数据规模的新界限 [Goyal et al., 2021]。计算机视觉中的SSL方法在一些情况下,甚至可以与监督学习模型相媲美,甚至超越它们,即便是在ImageNet这样竞争激烈的基准测试上 [Tomasev et al., 2022; He et al., 2020a; Deng et al., 2009]。此外,自监督学习还成功应用于视频、音频和时间序列等其他数据模态 [Wickstrøm et al., 2022; Liu et al., 2022a; Schiappa et al., 2022a]。
自监督学习通过未标注数据定义一个预设任务,以生成描述性且可解释的表征 [Hastie et al., 2009; Goodfellow et al., 2016]。在自然语言处理中,一个常见的SSL目标是遮蔽文本中的某个单词并预测其周围的单词。通过这种预测单词上下文的目标,模型能够在无需标注的情况下捕捉单词间的关系。相同的SSL模型表征可以应用于多种下游任务,如跨语言翻译、文本摘要,甚至文本生成等。在计算机视觉中,也存在类似的目标,诸如MAE或BYOL等模型,通过预测图像的遮蔽块或表征来学习 [Grill et al., 2020; He et al., 2022]。其他SSL目标则鼓励将同一图像的两个视图(例如通过添加颜色或裁剪得到)映射到相似的表征。
通过训练大量未标注数据,SSL带来了许多好处。传统的监督学习方法通常基于已知的标注数据训练特定任务,而SSL则学习可应用于多个任务的通用表征。SSL在如医学等领域尤为有用,因为在这些领域标注代价高昂或具体任务无法预先确定 [Krishnan et al., 2022; Ciga et al., 2022]。研究还表明,与其监督学习对比,SSL模型在面对对抗样本、标签污染和输入扰动时表现出更高的鲁棒性,并且更具公平性 [Hendrycks et al., 2019; Goyal et al., 2022]。因此,SSL领域正在获得越来越多的关注。然而,就像烹饪一样,训练SSL方法也是一门需要精细掌控的艺术,且入门门槛较高。
1.1 为什么需要自监督学习的“烹饪手册”?
虽然自监督学习的许多组件对于研究人员来说是熟悉的,但成功训练一个SSL方法涉及从预设任务到训练超参数等繁杂的选择。SSL研究的入门门槛高主要因为:(i) 其计算成本较高;(ii) 缺乏详细公开的论文,来描述完全发挥SSL潜力所需的复杂实现细节;以及 (iii) 缺乏统一的术语和理论视角。SSL已经确立了与传统基于重构的无监督学习方法(如去噪自编码器和变分自编码器)截然不同的范式 [Vincent et al., 2008, 2010; Kingma and Welling, 2013],但我们对SSL的统一理解仍然有限。实际上,将SSL方法统一在一个视角下的尝试直到最近才开始出现 [HaoChen et al., 2021; Balestriero and LeCun, 2022; Shwartz-Ziv et al., 2022; Garrido et al., 2022b]。在缺乏统一描述SSL方法不同组件的基础上,研究人员更难开始SSL方法的研究。同时,由于SSL已经广泛应用于现实世界,SSL研究急需更多的研究人员加入。然而,关于SSL的一般化保证、公平性和对抗攻击或自然变化的鲁棒性等问题仍然悬而未决,而这些问题对于SSL方法的可靠性至关重要。
此外,SSL是一个经验驱动的领域,涉及许多影响最终表征关键属性的“移动部分”(主要是超参数),这些部分在已发表的工作中未必详细说明。也就是说,要开始研究SSL方法,研究人员必须首先通过大量实验来彻底理解这些“移动部分”的影响和行为。这种经验上的盲点是SSL发展的主要限制因素,因为它需要大量的计算资源和现有的实操经验。总的来说,现有的最先进性能来自看似不同但相互重叠的方法,加之有限的理论研究和SSL在现实世界中的广泛部署,使得需要一本统一技术与配方的“烹饪手册”来降低SSL研究的入门门槛。
我们的目标是通过以“烹饪手册”的方式,奠定SSL研究的基础并提供最新的SSL方法配方,从而降低研究SSL的门槛。为了成功“烹饪”,首先必须学习基础技巧:如切菜、煸炒等。在第二节中,我们将使用通用的术语描述自监督学习的基本技术,具体地讲述方法的类别及理论线索,以统一的视角连接它们的目标。我们会在概念框中突出显示关键概念,如损失项或训练目标。接着,研究人员需要熟练运用这些技术来做出美味的“菜肴”。这需要学习现有配方、组装原料并评估成品。在第三节中,我们介绍成功实施SSL方法的实际考虑因素。我们将讨论常见的训练配方,包括超参数选择、组件如模型架构和优化器的组装方法,以及如何评估SSL方法。我们还将分享来自顶尖研究人员的实用建议,帮助研究人员规避常见的训练配置陷阱。我们希望本手册能够成为成功训练和探索自监督学习的实用基础。
2 自监督学习的类别与起源
自2020年以来,SSL方法得到了显著复兴,这在很大程度上要归功于超大数据集和高内存GPU的可用性。然而,SSL的起源可以追溯到深度学习时代的初期。
2.1 自监督学习的起源
当代SSL方法建立在早期实验中获得的知识之上。本节概述了2020年之前SSL的主要思想。尽管其中许多具体方法因不再提供基准测试中的最先进性能而逐渐淡出主流,并不会在此作详细讨论,但这些论文中的思想构成了许多现代方法的基础。例如,恢复输入的缺失或扭曲部分、或对比同一图像的两个视图的核心目标,为现代SSL方法奠定了基础。早期SSL的进展主要集中在以下几个(有时重叠的)类别的方法的发展上:
-
信息恢复:这一类方法中开发了许多技术,它们通过遮蔽或移除图像中的某些内容,然后训练神经网络来恢复缺失信息。基于着色的SSL方法将图像转换为灰度图像,然后训练网络来预测原始的RGB值 [Zhang et al., 2016; Larsson et al., 2016; Vondrick et al., 2018]。由于着色需要理解物体的语义和边界,它成为了对象分割的早期SSL方法之一。最简单的信息恢复应用是遮蔽图像的一部分,然后训练网络来修复缺失的像素值 [Pathak et al., 2016]。这个想法发展成了遮蔽自编码(masked auto-encoding)方法 [He et al., 2022],其中遮蔽区域由图像块的集合组成,可以通过transformer进行预测。
-
利用视频中的时序关系:虽然本综述主要关注图像处理(而非视频),但已有一些专门方法通过在视频上进行预训练来学习单一图像的表示。值得注意的是,信息恢复方法在视频处理中特别有用,因为视频包含多种信息模态,可以被遮蔽。Wang和Gupta [2015] 使用三元损失(triplet loss)预训练模型,促使不同帧中相同物体的表示相似。Pathak等人 [2017] 训练模型来预测单帧中物体的运动,并将得到的特征应用于单帧检测问题。Agrawal等人 [2015] 预测相机的自运动,给定多个帧。Owens等人 [2016] 提出了从视频中移除音轨,然后预测缺失声音的任务。在深度映射等特定应用中,自监督方法已经被提出,以便从未标注的图像对 [Eigen et al., 2014] 或来自单摄像机视频的帧 [Zhou et al., 2017] 中学习单目深度模型。这些方法仍是活跃的研究领域。
-
学习空间上下文:此类方法训练模型理解场景中物体的相对位置和方向。RotNet [Gidaris et al., 2018] 通过施加随机旋转并让模型预测旋转角度来屏蔽重力方向。Doersch等人 [2015] 是最早的SSL方法之一,方法是简单地预测图像中随机采样的两个块的相对位置。这一策略被“拼图”方法所取代 [Pathak et al., 2016; Noroozi et al., 2018],该方法将图像分割成多个不相连的块,并预测每个块的相对位置。另一种空间任务是学习计数 [Noroozi et al., 2017]:模型被训练成以自监督的方式输出图像中的物体数量。
-
将相似图像分组:通过将语义上相似的图像分组,可以学习丰富的特征。K-means聚类是经典机器学习中最广泛使用的方法之一。已有许多研究将k-means方法与神经网络相结合来执行SSL。深度聚类(deep clustering)在特征空间中执行k-means分配图像标签,并更新模型以符合这些指定的类标签 [Caron et al., 2018]。更近的一些研究使用均值漂移(mean-shift)更新,将特征推向其簇中心,并已被证明可与BYOL(一种基于两个网络的方法,其目标是预测每个样本的伪标签)互补 [Koohpayegani et al., 2021](在2.3节讨论)。深度聚类的其他改进包括在特征空间中使用最优传输方法来创建更具信息性的簇 [Asano et al., 2019]。
-
生成模型:早期一个有影响力的SSL方法是逐层贪心预训练 [Bengio et al., 2006],即通过自编码器损失逐层训练深度网络。类似的方法使用受限玻尔兹曼机(RBM),通过逐层训练并堆叠创建深度信念网络 [Hinton et al., 2006]。虽然这些方法被更简单的初始化策略和更长的训练过程所取代,但它们在历史上是影响深远的SSL应用,因为它们使得训练首个“深层”网络成为可能。后续的进展改进了自编码器的表示学习能力,包括去噪自编码器 [Vincent et al., 2008]、跨通道预测 [Zhang et al., 2017] 和深度典型相关自编码器 [Wang et al., 2015]。尽管如此,最终发现,当自编码器被要求恢复输入的缺失部分时,其表示的可转移性更好,形成了SSL方法的“信息恢复”类别。
生成对抗网络(GANs) [Goodfellow et al., 2014] 包含图像生成器和判别器,分别用于生成图像和区分真实与生成的图像。该模型对可以无监督地训练,并且两者都有潜在的迁移学习价值。早期的GANs论文 [Salimans et al., 2016] 在下游图像分类任务中实验了使用GAN组件。还有一些专门的特征学习流程,通过修改判别器 [Springenberg, 2015]、添加生成器 [Dai et al., 2017] 或学习从图像到潜在空间的额外映射 [Donahue et al., 2017],以改进迁移学习。
-
多视图不变性:许多现代SSL方法,尤其是本文重点讨论的那些,使用对比学习来创建对简单变换不变的特征表示。对比学习的思想是鼓励模型对输入的两个增强版本表示相似。一些方法在对比学习广泛采用之前,通过不同方式来实现不变性。
其中一种从未标注数据中学习的流行框架是使用弱训练的网络对图像应用伪标签,然后在标准监督方式下使用这些标签进行训练 [Lee et al., 2013]。这种方法后来通过施加对变换的不变性得到了改进。虚拟对抗训练(virtual adversarial training)[Miyato et al., 2018] 使用伪标签训练网络,并进行对抗训练,以便使得学到的特征对输入图像的小扰动几乎不变。后来的工作则专注于保持数据增强变换的不变性。这一类别的重要早期方法包括MixMatch [Berthelot et al., 2019],它通过对训练图像进行多个不同的随机增强来平均网络输出,从而产生对增强不变的标签。差不多在同一时间,研究发现通过最大化不同视图下图像表示的互信息,也可以取得良好的SSL性能 [Bachman et al., 2019]。这些基于增强的方法在老旧方法和本文重点讨论的现代方法之间架起了桥梁。
基于这些起源,我们接下来将SSL划分为四大类:深度度量学习(Deep Metric Learning)家族、自蒸馏(Self-Distillation)家族、典型相关分析(Canonical Correlation Analysis)家族,以及遮蔽图像建模(Masked Image Modeling)家族。
2.2 深度度量学习家族:SimCLR/NNCLR/MeanSHIFT/SCL
深度度量学习(Deep Metric Learning, DML)家族的方法基于鼓励输入的语义变换版本之间的相似性。DML起源于对比损失(contrastive loss)的概念,它将这种相似性原则转化为一个学习目标。对比损失首次由[Bromley et al., 1993]引入,随后在[Chopra et al., 2005; Hadsell et al., 2006]中被更正式地定义。在DML中,模型被训练以预测两个输入是否来自相同类别,并通过让它们的嵌入相互接近(或远离)来实现。由于数据没有标签,为了识别相似的输入,我们通常通过已知的语义保持变换来生成单个输入的不同变体。这些输入的变体称为“正样本对”,而我们希望让其相异的样本称为“负样本”。通常,设有一个参数,它规定了不同类别的样本之间的距离应大于。类似于对比损失,三元组损失(triplet loss)[Weinberger and Saul, 2009; Chechik et al., 2010; Schroff et al., 2015]也遵循相同的原理,但它由三元组(query、positive和negative)组成。
从DML到SSL的转变可能始于[Sohn, 2016]引入的(N+1)-tuple loss,这种损失类似于[Oord et al., 2018]的对比预测编码(contrastive predictive coding, CPC)损失。CPC中使用的InfoNCE损失[Henaff, 2020]成为SSL的核心组成部分。DML和对比SSL之间的主要范式转变体现在几个关键变化上,即使用数据增强而不是采样来获得正/负样本对,使用更深层的网络,以及引入预测网络(predictor network)。在深度学习家族中,从DML转变到SSL的突出方法之一是SimCLR。
SimCLR通过鼓励图像的两个增强视图之间的相似性来学习视觉表示。在SimCLR中,这两个视图是通过随机调整大小、裁剪、颜色抖动和模糊等变换的组合生成的。每个视图编码后,SimCLR使用一个投影器(通常是一个多层感知机MLP,并辅以ReLU激活)将初始嵌入映射到另一个空间,在该空间中应用对比损失以鼓励视图之间的相似性。在下游任务中,提取投影器之前的表示通常被证明能提高性能。SimCLR还使用了一种非参数化的softmax [Wu et al., 2018],通过与其他表示进行比较来计算softmax,从而消除了在表示上方使用参数化线性层的需求。
除此之外,通过语义保持变换来形成正样本对之外,还可以自然地从数据中挖掘正样本对。例如,基于视频帧的三元组损失,正样本对来自邻近帧,而负样本则来自远离帧的对比学习方法(例如[Sermanet et al., 2018]的Time-Contrastive Learning)。另一种考虑是“困难负样本挖掘”(hard negative mining),即选择接近但与正样本有细微区别的负样本,以形成更具挑战性的学习目标。
2.3 自蒸馏家族:BYOL/SimSIAM/DINO
自蒸馏(Self-Distillation)方法(如BYOL [Grill et al., 2020]、SimSIAM [Chen and He, 2021]、DINO [Caron et al., 2021])及其变体依赖于一种简单的机制:将两个不同的视图输入两个编码器,并通过预测器将一个视图映射到另一个视图。为防止编码器因对任何输入预测恒定值而崩溃,各种技术被采用。防止崩溃的常见方法是用一个编码器的权重的运行平均来更新另一个编码器的权重。
BYOL(bootstrap your own latent)首先将自蒸馏引入,以避免崩溃。BYOL使用两个网络和一个预测器,将一个网络的输出映射到另一个网络。预测输出的网络称为在线网络(online network)或学生网络(student network),而生成目标的网络称为目标网络(target network)或教师网络(teacher network)。两个网络分别接收相同图像的不同视图,这些视图通过包括随机调整大小、裁剪、颜色抖动和亮度变化等图像变换生成。学生网络通过梯度下降进行更新,而教师网络通过在线网络权重的指数移动平均(EMA)进行更新。指数移动平均的缓慢更新导致的非对称性是BYOL成功的关键。损失函数可以定义为:
其中,向量在表示空间中被自动归一化,即:
其中通常设为。是由参数表示的在线编码器网络(学生网络),而是由参数表示的预测器网络。是从数据分布中采样的输入,和是的两个增强视图,其中,是两种数据增强方法。目标网络与学生网络架构相同,通过EMA更新,并且控制目标网络保留历史的程度,即:
初始化时。
以上描述的自蒸馏方法,通过避免对比学习中的明确负样本选择,提供了一种无需对比的训练方式,为自监督学习研究开辟了新的方向。

图的解释》 噪声对比估计:学习非规范化密度
噪声对比估计(Noise Contrastive Estimation, NCE)由[Gutmann和Hyvärinen, 2010]提出,用于在给定独立同分布样本的情况下学习未规范化的概率分布。NCE允许通过参数化函数来近似,而无需在训练期间强制满足的归一化条件。
-
首先引入噪声变量,并考虑以下混合分布:
其中,表示参数为的Bernoulli分布,和分别表示指示变量。
-
使用贝叶斯公式,并设,我们可以得到:
-
参数化,其中且包含可学习参数。
-
通过最小化逻辑回归的负对数似然(通常的二分类设置),损失函数表示为:
-
当足够强大时,可以设,并且模型将自归一化[Mnih和Teh, 2012]。在这种情况下,目标函数的最小值达到,前提是当时,有。
-
Ceylan和Gutmann [2018]将NCE扩展至非独立的噪声实现情况,即依赖于,而Ma和Collins [2018]考虑了条件分布。Dyer [2014]对比了NCE和负采样(Negative Sampling)[Mikolov et al., 2013],后者是前者的一个特例。两者均扩展了对分区函数(归一化因子)的重要性采样估计[Bengio和Senécal, 2003]。
噪声对比估计不仅在无监督学习中广泛应用,还在包括词嵌入学习等各种场景中使用。NCE通过将学习转化为二分类问题,避免了传统密度估计中的归一化困难,并为SSL方法提供了理论基础。


图的解释》InfoNCE损失的简史
在以下描述中,表示样本的模型表示,表示正样本集,是温度超参数。
-
Bromley et al. [1993], Chopra et al. [2005] 引入对比损失(Contrastive Loss)用于深度度量学习(Deep Metric Learning):
该损失函数通过最小化正样本对之间的距离并惩罚负样本对之间距离小于一个阈值的情况来实现学习目标。
-
Goldberger et al. [2004] 引入邻域成分分析(Neighbourhood Component Analysis, NCA):
NCA通过学习一个基于二次距离的度量(如Mahalanobis距离)来改进最近邻分类器(NN-classifier)的最大边界。
-
Weinberger and Saul [2009], Chechik et al. [2010] 将公式(1)扩展为三元组损失(Triplet Loss):
三元组损失依赖于正样本和负样本对的相对距离,并且要求正样本对距离小于负样本对的距离减去一个边界。
-
Sohn [2016] 将三元组损失和NCA损失扩展为(N+1)-tuple损失:
其中分母仅对其他样本的一种视图进行求和,负距离被内积和特征图的惩罚项所替代。显式归一化在[Yu和Tao, 2019]中被引入。
-
Wu et al. [2018] 引入无正样本对的噪声对比估计(Noise-Contrastive Estimation, NCE)损失:
其中“非参数化softmax”术语被引入,NCE损失包括显式归一化、温度参数,并通过近端优化方法引入了动量编码器的概念。NCE被用于当较大时近似分母。
-
Oord et al. [2018, CPC] 称之为InfoNCE,通过移除近端约束并使用正样本对: InfoNCE损失是对NCE的进一步发展,用于通过正样本对构建更精确的信息估计和表征学习。这在对比学习中引入了高效的采样策略,为自监督学习中的正负样本对选择提供了灵活的框架。
InfoNCE损失及其衍生方法已经成为自监督学习(SSL)中的重要工具,通过温度参数控制对比度,能够灵活地调整正负样本对的权重,从而适应不同数据集的特性和任务需求。


SimSiam 的目标是理解在 BYOL 中哪些组件最为重要。SimSiam 研究表明,Exponential Moving Average (EMA) 在实践中并不是必要的,即使它可以带来少量的性能提升。这使得使用简化的损失函数成为可能,该损失函数定义如下:
在上述公式中, 表示模型参数, 是投影头的参数, 是输入数据, 和 是两种不同的数据增强方式, 表示投影头, 函数用于重新归一化输出, 表示停止梯度操作,以确保该分支的梯度不会被反向传播。

为了简洁起见,我们省略了 的采样分布。许多研究致力于理解 BYOL 和 SimSiam 是如何避免崩溃的,比如 Tian et al. [2021] 和 Halvagal et al. [2022]。他们发现,两条分支之间的不对称性是关键,同时训练过程中对嵌入的方差进行隐式正则化的动态过程也很重要。
DINO 通过使用滑动平均值对学生网络的输出进行中心化,以避免对 mini-batch 大小的敏感性,并通过带有温度参数 的 softmax 函数平滑离散表示。通常情况下, 的取值大约为 0.1,其损失函数定义如下:
类似于 BYOL,DINO 中的教师网络再次使用学生网络权重的移动平均值。移动平均值的权重通常为 ,在训练过程中遵循余弦调度,从 0.996 到 1 逐渐增大。DINO 中 softmax 引起的离散化可以解释为一种在线聚类机制,其中 softmax 之前的最后一层包含了聚类原型及其权重。因此,倒数第二层的输出是利用最后一层的权重进行聚类的。
iBOT 基于 DINO,并将其目标函数与直接应用于潜在空间的掩码图像建模目标相结合。在 iBOT 中,目标重建不是图像像素,而是通过教师网络嵌入的相同图像块(patches)。
DINOv2 在 iBOT 的基础上进一步改进,通过优化训练配方、改进网络架构,并引入额外的正则化器(例如 KoLeo [Sablayrolles et al., 2018]),显著提高了线性评估和 k-NN 评估的性能。此外,DINOv2 还整理了一个包含 1.42 亿张图像的更大预训练数据集(更多讨论见第 2.7 节)。
许多其他方法也属于这一自蒸馏家族。MoCo 是另一种流行的方法,它基于字典查找机制,在某些情况下被证明可以在分割和目标检测基准测试中超过监督学习 [He et al., 2020a]。最初,动量编码器是作为对比学习中队列的替代方案引入的 [He et al., 2020a],这扩展了 [Dosovitskiy et al., 2014] 的研究结果。MoCo 的移动平均使用了相对较大的动量,默认值为 。这个较高的动量值比较小的值(如 )效果更好。当 SimCLR 引入了投影头和更强的数据增强时,MoCoV2 [Chen et al., 2020d] 也随之采用了更强的数据增强和投影头以提升性能。
在类似的精神下,ISD [Tejankar et al., 2021] 使用 KL 散度来比较查询分布与学生分布的锚点,从而放松了正负样本之间的二元区分。MSF [Koohpayegani et al., 2021] 将查询的最近邻表示与学生目标的表示进行比较,并通过重新归一化来最小化它们之间的 距离(类似于最大化余弦相似度)。另一个方法 SSCD 则基于对比目标,用于拷贝检测任务,表现优于其他拷贝检测模型和对比方法 [Pizzi et al., 2022]。
除了广泛使用的对比学习目标外,许多方法也在其训练机制中采用了类似的移动平均更新。例如,自蒸馏 [Hinton et al., 2015, Furlanello et al., 2018]、强化学习中的 Deep Q Network [Mnih et al., 2013]、半监督学习中的 Mean Teacher [Tarvainen and Valpola, 2017],甚至在监督和生成建模中的模型平均 [Jean et al., 2014]。
2.4 Canonical Correlation Analysis家族:VICReg/Barlow Twins/SWAV/W-MSE
自监督学习(SSL)的典型相关分析(Canonical Correlation Analysis, CCA)家族起源于典型相关框架(Canonical Correlation Framework, CCA)[Hotelling, 1992]。CCA的高层次目标是通过分析两个变量的互协方差矩阵来推断它们之间的关系。具体来说,设和。CCA框架寻求两个变换和,使得:
满足:
其中为输出映射的维度,满足。线性CCA [Hotelling, 1992]认为两个映射为线性映射,此时最优参数可以通过的奇异值分解(SVD)找到,其中涉及、的协方差矩阵及其互协方差。Breiman和Friedman [1985]通过连接公式(13)的解与交替条件期望(Alternating Conditional Expectation, ACE)方法,在非线性CCA研究中取得了重大进展,特别是在单变量输出设置下;Makur等人 [2015]则在多变量输出设置下推进了该领域。Painsky等人 [2020]研究了利用交替条件期望优化非线性CCA表示之间的联系,并证明了新的理论界限,这些界限进一步优化了CCA。
这些概念被扩展到深度学习中,形成了深度典型相关自编码器(Deep Canonically Correlated Autoencoders, DCCAE),即通过CCA正则化的自编码器。Hsieh [2000]和Andrew等人 [2013]提出了联合学习两个网络和参数的目标,以使其输出最大程度相关。该网络的输入是两个视角和。具体来说,该目标为寻找每个网络的参数和,使得:
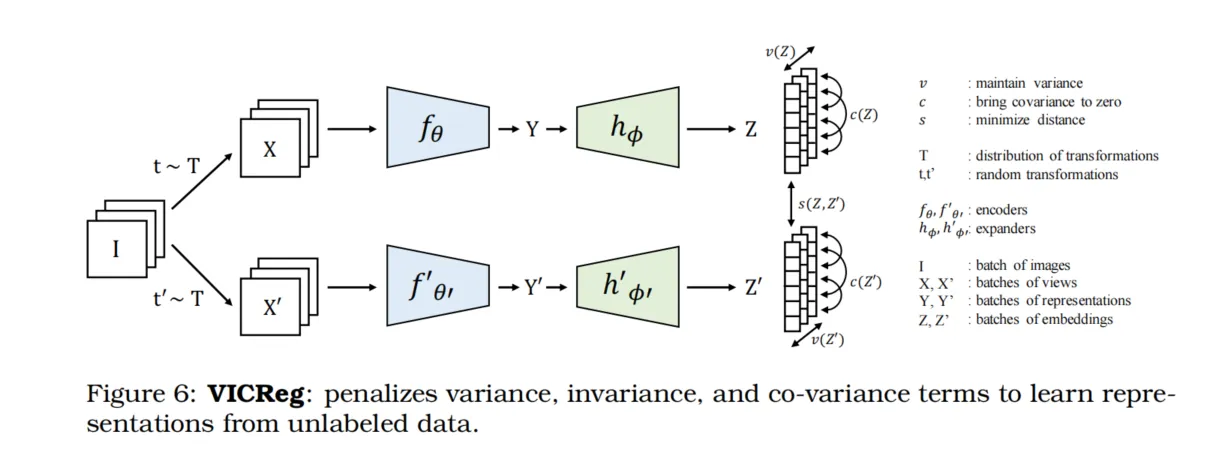
该DCCAE目标在Wang等人 [2015]的研究中被扩展至多变量输出和任意深度神经网络(DDNs)。基于这些起源,发展出一系列SSL方法,如VICReg [Bardes et al., 2021]、Barlow Twins [Zbontar et al., 2021]、SWAV [Caron et al., 2020]和W-MSE [Ermolov et al., 2021]。VICReg是这些方法中最新的,它基于来自两个视角的表示的协方差矩阵平衡了三个目标:方差、不变性和协方差(参见图6)。在每个表示维度上正则化方差可以防止坍缩,不变性确保两个视角被相似地编码,而协方差鼓励表示的不同维度捕捉不同的特征。
2.5 掩码图像建模
早期许多重要的自监督视觉预训练算法通过对训练图像施加退化处理来进行,如去色 [Zhang et al., 2016]、噪声 [Vincent et al., 2008]或打乱图像块 [Noroozi and Favaro, 2016],并训练模型恢复这些退化。上下文编码器则掩盖图像的大部分区域,用白色填充这些像素值,从而训练自编码器来修复这些白色区域 [Pathak et al., 2016]。这一早期的掩码图像建模尝试未能在下游任务中实现与监督学习相竞争的性能,并且是在视觉Transformer架构出现之前进行的。此后,BERT [Devlin et al., 2019]在自然语言处理中引入了变革性的影响,通过将输入到Transformer语言模型的文本标记替换为可学习的掩码标记,并教模型恢复原始文本。这种被称为掩码语言建模(Masked Language Modeling, MLM)的范式,可以解释为上述策略的一种形式,通过掩码使样本退化并训练模型来逆向还原这种退化。MLM及其延伸的跨度填充技术仍然是大型语言模型常用的SSL目标 [Raffel et al., 2020; Wang et al., 2022a; Tay et al., 2022]。
类似地,我们也可以掩盖图像的一部分并训练模型修复这些部分。这种预训练视觉策略被称为掩码图像建模(Masked Image Modeling, MIM)。受BERT启发,Dosovitskiy等人利用视觉Transformer架构,通过掩盖图像块标记并用学习的掩码标记替换它们,训练模型直接预测像素值。然而,他们发现这种预训练策略的效果远不如监督预训练 [Dosovitskiy et al.]。Bao等人 [2021a]指出,直接将BERT策略应用于图像是困难的,因为文本标记可以只有少量可预测的值(作为分类问题),而图像块可以具有远多于分类问题适合的可能值和类。因此,作者将MIM作为回归问题,通过首先使用自编码器将图像块编码为离散标记,然后预训练Transformer来预测掩码标记的离散值。BEiT在下游图像分类和语义分割上显著超越了先前的监督和自监督基线,但其训练流程较为复杂,因为它需要强大的自编码器来将图像块转换为离散标记。
为了简化MIM预训练,He等人 [2022]和Xie等人 [2022]提出了两种简化算法,即掩码自编码器(Masked Autoencoders, MAE)和SimMIM,它们直接重建被掩盖的图像块,而不是像BEiT那样使用从编码器中提取的离散图像标记。此外,这些简化的预训练策略在下游图像分类、语义分割和目标检测任务上表现优于BEiT。自此,掩码图像建模在各种视觉任务上取得了竞争力的性能 [Zhou et al., 2022a; Woo et al., 2023; Oquab et al., 2023],甚至在视觉-语言表示学习中也有应用 [Fang et al., 2022a]。当使用冻结编码器时,最成功的方法如iBOT [Zhou et al., 2022a]和DINOV2 [Oquab et al., 2023]结合了掩码图像建模和传统方法如自蒸馏。然而,它们的掩码图像建模目标是在潜在空间中重建,使用教师网络提供目标,而不是使用原始图像作为重建目标。
需要指出的是,MIM本质上是一种生成建模任务。这类模型被训练生成基于观察到的图像部分的缺失图像部分。需要注意的是,BEiT、MAE和SimMIM通过移除解码器并替换为预测头部来应用于下游预测问题。然而,掩码图像模型在生成建模上也有较强表现 [Chang et al., 2022],包括文本条件生成 [Chang et al., 2023]。与逐步生成图像块的自回归模型相比,基于MIM的生成模型显著提高了效率,因为它们可以并行生成图像块。
在第3.6节中,我们将讨论当代掩码图像建模系统为实现这种竞争力性能所采用的各种技术。

- Pathak等人 [2016] 实现了一种掩码预训练策略,将图像的大部分区域用白色填充,并通过编码器-解码器模型进行修复。
- Devlin等人 [2019] 提出掩码语言建模(Masked Language Modeling)自监督学习任务。BERT在多种下游语言问题上取得了最先进的性能。
- Dosovitskiy等人将BERT预训练策略应用于视觉Transformer架构。
- Bao等人 [2021a] 提出BEiT,用预测离散VAE编码器提取的离散视觉标记替代像素级重建损失。
- He等人 [2022] 通过移除VAE编码器简化了BEiT,使用像素级重建损失并调整整个流程以获得更优性能。掩码自编码器(MAE)在无需额外数据的条件下,在ImageNet 1k数据集上达到了最先进的性能。
- SimMIM同时期以类似方式简化了掩码自编码,取得了与MAE相似的图像分类性能,同时在目标检测、动作识别和语义分割等任务上也达到了最先进水平 [Xie et al., 2022]。
- Muse使用掩码Transformer方法达到了最先进的文本条件图像生成性能 [Chang et al., 2023]。
2.6 自监督学习的理论统一
2.6.1 自监督学习的理论研究
许多研究尝试将各种自监督学习(SSL)方法统一起来。在Huang等人 [2021] 的研究中,证明了Barlow Twins准则与对比损失的上界有关联,这表明对比方法与基于协方差的方法之间存在联系。Garrido等人 [2022b] 进一步研究了这一方向,通过推导出这两种方法之间的精确差距,证明了基于协方差的准则和对比准则在归一化条件下是等价的。这些结果也通过实证得到了验证,因为这些方法在ImageNet数据集(120万样本)上的表现和表示属性显示出相似性。Tao等人 [2021] 也从损失梯度的角度研究了方法之间的相似性,从而探讨了这种统一性。
对比学习与其他目标之间的关系
最初,InfoNCE被提出作为两个视角之间互信息的变分近似 [Aitchison and Ganev, 2023; Wang and Isola, 2020; Oord et al., 2018]。Li等人 [2021a] 从Hilbert-Schmidt独立准则(Hilbert-Schmidt Independence Criterion, HSIC)的角度解释了InfoNCE在对比学习中的作用,HSIC用于呈现不同变换之间互信息的变分下界。Tschannen等人 [2020] 指出,InfoNCE的性能不能仅通过互信息来解释,特征提取器和互信息估计器的具体形式等其他因素同样重要,这些因素会导致性能的显著差异 [Guo et al., 2022a]。其他理论则表明,InfoNCE在“正”样本的对齐性和整体特征表示的均匀性之间达到平衡 [Wang and Isola, 2022];或者在强假设下,它可以识别假设数据生成过程中的潜在结构,类似于非线性独立成分分析(nonlinear ICA)[Khemakhem et al., 2020]。Wang和Isola [2020] 的定理1表明,使用RBF核(将特征映射到更高维空间的表达式)进行的对比学习会收敛到具有匹配对的球体上的均匀分布。[Tian, 2022] 表明,使用深度线性网络进行对比学习等价于主成分分析(PCA),而 [Tian, 2023] 进一步分析了在使用对比损失训练时,非线性在网络结构中所起的作用,指出非线性导致多个局部最优解,可以容纳训练数据中的多样性模式,而线性网络则只允许学习到一个主导模式。Hjelm等人 [2019] 提出了Deep InfoMax(DIM),其通过使用输入的局部特征来最大化深度神经网络编码器输入与输出之间的互信息,这一思想在Veličković等人 [2018] 中被扩展到图上。
统一对比损失
Tian [2022] 统一了对比损失,将其视为最小化一族通用损失函数,其中和是单调递增且可微的标量函数:
其中表示表示向量,索引和从1到。通过选择不同的和,公式(15)可以涵盖许多损失函数(见图8)。特别地,设置和可以得到InfoNCE损失的广义形式 [Oord et al., 2018]:
这个公式表示了InfoNCE损失的通用形式,通过适当选择参数,可以涵盖自监督学习中的多种对比损失形式。
其中ϵ > 0是某个常数。例如,ϵ = 1在He等人[2020b]和Tian等人[2020a]的研究中被使用过,而ϵ = 0则会产生SimCLR [Chen et al., 2020b]的一个轻微变体,即DCL loss [Yeh et al., 2021]。

左图:数据点(第个样本及其增强版本,第个样本)被送入权重为的网络,生成输出、和。基于这些输出,我们计算和之间的成对平方距离,以及和之间的类内平方距离,用于具有通用对比损失(公式15)的对比学习。
右图:不同的现有损失函数对应不同的单调函数和。其中。
此图说明了对比学习设置下,样本及其增强版本之间、以及不同样本之间距离的计算方式,并展示了如何通过选择不同的单调函数来定义多种对比损失函数。
2.6 自监督学习的理论统一
2.6.1 自监督学习的理论研究
Hard Negative Sampling
在(深度)度量学习中,负样本挖掘已经被深入研究。近来,一些研究关注于对“hard samples”赋予更高权重[Robinson et al., 2020]。然而,Kalantidis等人[2020]以及Tian[2022]表明,带有的对比自监督学习(contrastive SSL)损失在批次级别已经自然地具备关注hard-negative pairs的机制,因而无需显式的“hard-negative sampling”。这意味着对比损失需要较大的批次大小,以确保能看到足够的hard negative样本,但这也带来了额外的内存成本。
Projector的研究
Projector网络最早由Chen等人[2020b]引入,用于将表示映射到另一个空间中以计算损失。尽管有大量的实证证据表明projector能够提升模型性能,但从理论上解释其作用的研究却很少。Jing等人[2022]探讨了对比学习中线性projector的作用。他们提出,projector可以防止表示空间中的维度塌缩,只需具备对角线和低秩特性即可达到此目的。虽然不使用projector的方法在性能上优于带有单层线性projector的SimCLR,但在使用2层或3层MLP projectors的情况下,SimCLR的性能依然难以超越。Cosentino等人[2022]研究了当数据增强操作是李群变换时,projector和数据增强之间的相互关系。与Mialon等人[2022]类似,他们解释了projector的宽度和深度对模型效果的影响。关于projector作用的更多实证研究将在第3.2节中展示。
2.6.2 表示的维度塌缩(Dimensional Collapse of Representations)
虽然联合自监督学习方法的目标是学习有意义的表示,但许多方法都存在所谓的维度塌缩问题。维度塌缩指的是表示的不同维度之间编码的信息出现冗余。换言之,projector输出的嵌入是秩不足的,这可以通过嵌入的奇异值谱来近似衡量,如图12所示。
这个现象最早由Hua等人[2021]提出,他们使用白化批归一化(whitening batch normalization)来缓解塌缩。Jing等人[2022]也从理论上研究了对比学习方法中的维度塌缩问题。后续的一些研究将维度塌缩与模型性能之间的影响关联起来[He and Ozay, 2022; Ghosh et al., 2022; Li et al., 2022a; Garrido et al., 2022a]。一些研究关注于无监督评估[Ghosh et al., 2022; Garrido et al., 2022a],发现维度塌缩是衡量下游性能的一个良好指标。
不同的研究提出了各种衡量维度塌缩的方法,比如奇异值分布的熵[Garrido et al., 2022a]、经典的秩估计器[Jing et al., 2022]、对奇异值分布进行幂律拟合[Ghosh et al., 2022]或奇异值分布的AUC[Li et al., 2022a]。尽管这些方法不同,它们都专注于通过表示的秩来衡量学习到的表示中的维度塌缩问题。
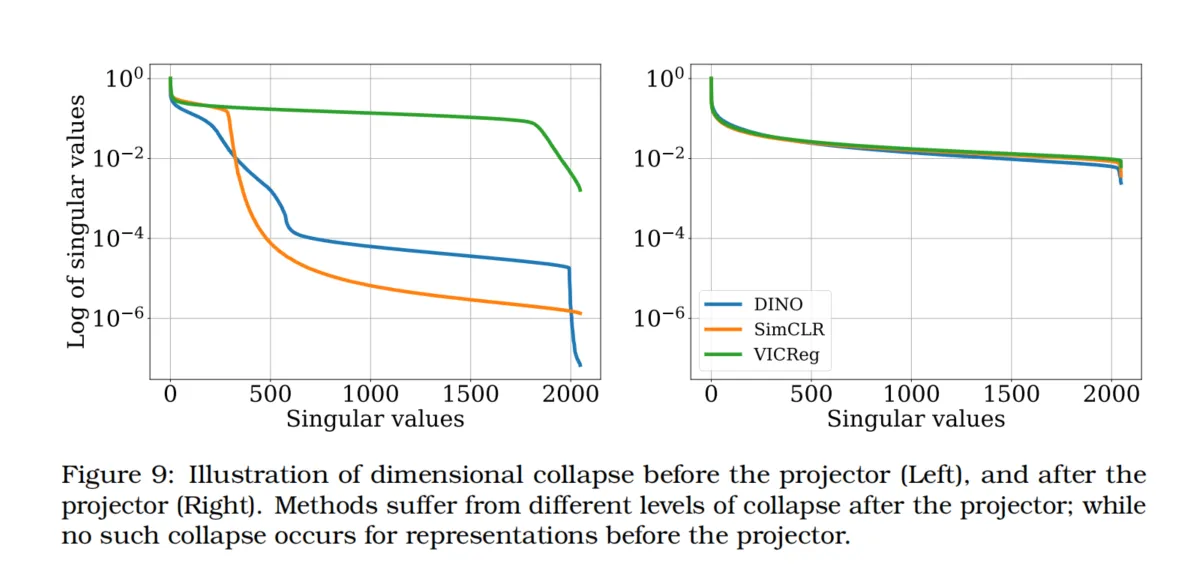
图9:维度塌缩的示意图——projector之前(左)和projector之后(右)。方法在projector之后经历了不同程度的塌缩;而在projector之前,表示则没有出现这种塌缩。
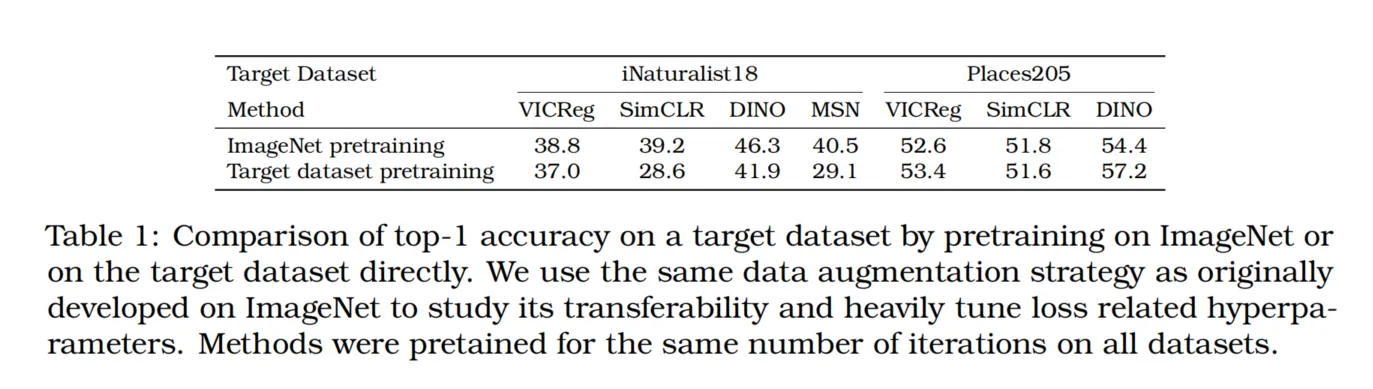
表1:在目标数据集上,通过在ImageNet或直接在目标数据集上进行预训练的Top-1准确率比较。我们使用了与ImageNet上原始开发相同的数据增强策略,以研究其可迁移性,并对损失相关的超参数进行了大量调整。所有方法在所有数据集上都经过相同次数的迭代预训练。
3 A Cook’s Guide to Successful SSL Training and Deployment
3.1 数据增强的作用
许多自监督学习(SSL)方法,尤其是从Chen等人[2020b]衍生的联合嵌入方法,需要通过对给定图像生成正样本视图,以学习不变性。这些SSL方法通常利用数据增强来定义这些不变性。例如,通过对给定图像进行不同的裁剪并作为正样本视图,SSL模型将被训练为对这些不同裁剪后的图像具有不变性。类似地,使用灰度转换或色彩抖动(ColorJitter)作为正样本视图时,模型的表示将对颜色信息具有不变性。因此,SSL模型所学习到的不变性特征本质上是由数据增强流程所定义的。
值得注意的是,由于projector的作用,并不会实现完全的不变性[Bordes et al., 2022a],这有助于在某些不完全不变的任务上提升性能。Chen等人[2020b]研究了特定数据增强对SimCLR在ImageNet上性能的影响,结果表明简单的数据增强(如噪声)在ImageNet分类任务中并不具备优势。而裁剪和多种色彩抖动操作则可以使模型在性能上接近监督学习的基线。这一数据增强的关键要素也在后续的SSL工作中得到了广泛应用[Chen et al., 2020d; Bardes et al., 2021; Zbontar et al., 2021],并没有显著的变化。唯一的变体是增加小裁剪以搭配大裁剪以学习不变性。我们将在后续小节中讨论这种大小裁剪的组合策略(称为多裁剪,multi-crop)。
然而,这种特定的数据增强组合策略是专门为在ImageNet上获得良好性能而设计的。Bordes等人[2023a]研究了在不同下游任务中选择不同数据增强策略的影响,发现虽然ColorJitter的加入对许多分类任务有益,但在其他下游任务中可能并非如此。同样,Ericsson等人[2021a]表明,不同的数据增强会导致模型学习到不同类型的不变性,这些不变性在一些下游任务中表现较好,而在另一些任务中则可能表现不佳。作者建议将使用不同数据增强学习到的表示合并,以提高跨更广泛下游任务的可迁移性。
使用复杂的数据增强流程还存在一个隐性成本:数据预处理时间。这可能显著延长训练时间。因此,在训练预算有限的情况下,仅使用随机裁剪和灰度转换可能是训练SSL模型的更优选择。我们将在3.8.1节讨论加速训练流程的常用方法。Ni等人[2021b]进一步表明,对比学习可以通过使用较激进的数据增强(如大角度旋转)获得收益,特别是在显式训练模型不对其具有不变性的情况下,这与元学习类似[Ni et al., 2021a]。
另一个研究方向是尝试消除对这些手工设计的数据增强的依赖。一种方法是使用基于重建的目标,如MAE [He et al., 2022],它在像素空间中使用重建损失,从而避免定义具体不变性的需求。另一种方法基于联合嵌入,其中目标是通过随机选取图像的部分,在表示空间中预测图像中缺失部分的表示。例如,I-JEPA [Assran et al., 2023]和Data2Vec2.0 [Baevski et al., 2022]就是这种方法的应用,它们使用图像的一部分上下文来预测缺失的小部分图像。
还有一些研究致力于保留关于数据增强的风格信息,以改善需要风格信息的下游任务(如颜色)的性能,通过预测风格信息来实现[Xiao et al., 2020; Dangovski et al., 2021; Gidaris et al., 2018; Scherr et al., 2022]。真正实现对数据增强的等变性(这需要在嵌入之间映射)是一个活跃的研究领域,相关方法如EquiMod [Dangovski et al., 2021]、SEN [Park et al., 2022]或[Marchetti et al., 2022]也旨在将表示分离为类别和姿态。将表示分为不变和等变部分的思想在SIE [Garrido et al., 2023]以及使用李群形式主义的Ibrahim等人[2022]中也有所探索。
3.1.1 多裁剪的作用
虽然诸如MoCo [Meng et al., 2021]的工作侧重于增加负样本的数量或质量,但另一种提升性能的途径是增加给定图像的正样本数量。多裁剪(multi-crop)技术由SwAV [Caron et al., 2020]引入,通过在常规的两个大裁剪(224×224)之外增加小裁剪(96×96)来实现这个目的。除了对两个大裁剪进行比较,模型还将每个大裁剪与所有其他裁剪(无论大小)进行比较。因此,如果我们有2个大裁剪和N个小裁剪,模型的正样本不变性损失会被计算次,从而增强了正样本的相关信号。使用小裁剪且不比较所有裁剪对有助于降低这些额外裁剪的计算成本。
尽管多裁剪的额外数量可能不同(如Mugs [Zhou et al., 2022b]使用10个裁剪,而SwAV使用6个裁剪),其使用方式会增加训练时间和内存消耗。为减轻这一成本,SwAV使用了160×160的大裁剪和4个96×96的小裁剪,仅导致训练时间比经典设置(即两个224×224的裁剪)增加25%,但带来了4个点的性能提升。因此,多裁剪是一种有助于提升性能的有效策略,仅需少量额外的计算资源。在最近的研究中,这种方法几乎随处可见[Caron et al., 2021; Zhou et al., 2022a,b; Bardes et al., 2022; Oquab et al., 2023]。需要指出的是,某些研究仅观察到性能的微小提升[Wang et al., 2021a],仅提升了0.3个百分点。
一些其他方法试图通过使用嵌入空间中的最近邻来减轻提供额外裁剪带来的计算负担。在NNCLR [Dwibedi et al., 2021]中,匹配的正样本裁剪被其在潜在空间中的最近邻替代,而在MSF [Koohpayegani et al., 2021]中,在嵌入空间中构建了一个k-NN图,以实现类似于多裁剪的效果并增强正样本信号。这个策略在UniVCL [Tang et al., 2022]中得到了进一步应用,结合了节点遮蔽和潜在空间中的k-NN图。与多裁剪相比,这些方法在提升性能的同时,计算成本更低。在MSF中,使用k-NN图仅增加了6%的训练时间。
3.2 Projector的作用
大多数基于联合嵌入方法的自监督学习(SSL)模型在编码器之后都包含一个projector(通常是带有ReLU的2层或3层MLP)。SSL损失是通过projector的输出计算的,而在训练完成后,projector通常会被丢弃。这个关键组件最早在SimCLR [Chen et al., 2020b]中引入,尽管它并不是避免塌缩的直接原因,但却能显著提升在ImageNet上的Top-1准确率。例如,在100个epoch的训练中,SimCLR和VICReg通过projector分别增加了约20%的Top-1准确率(从约50%提升到68%以及从48%提升到68%)。
Bordes等人[2022a]显示,projector不仅对SSL有用,在训练任务与下游任务不完全对齐的情况下,在监督学习中也非常有利(这点也在Sariyildiz等人[2022]的研究中得到验证)。实际上,Yosinski等人[2014]早已表明,在迁移学习中裁剪训练好的深度神经网络的某些层,主要是为了避免训练任务的过拟合偏差。同样,对于SSL任务,由于训练任务始终不同于下游任务,因此也需要使用projector。为了将SSL和迁移学习中的术语对应起来,Bordes等人[2022a]提出将这种对中间表示的探测或层裁剪称为“Guillotine Regularization(GR)”。他们还强调了在SSL中将GR和projector区分开的重要性,因为最佳的探测表示层不一定总是骨干网络层(在Chen等人[2020c]的研究中可能是projector的中间层)。最后,Bordes等人[2022a]展示了通过在对比学习中使用类别标签来确定正样本对,从而减少训练和预训练任务之间的不一致性,能够让网络在ImageNet上的最佳线性探测性能出现在projector的最后一层(而非骨干网络层),如图10所示。

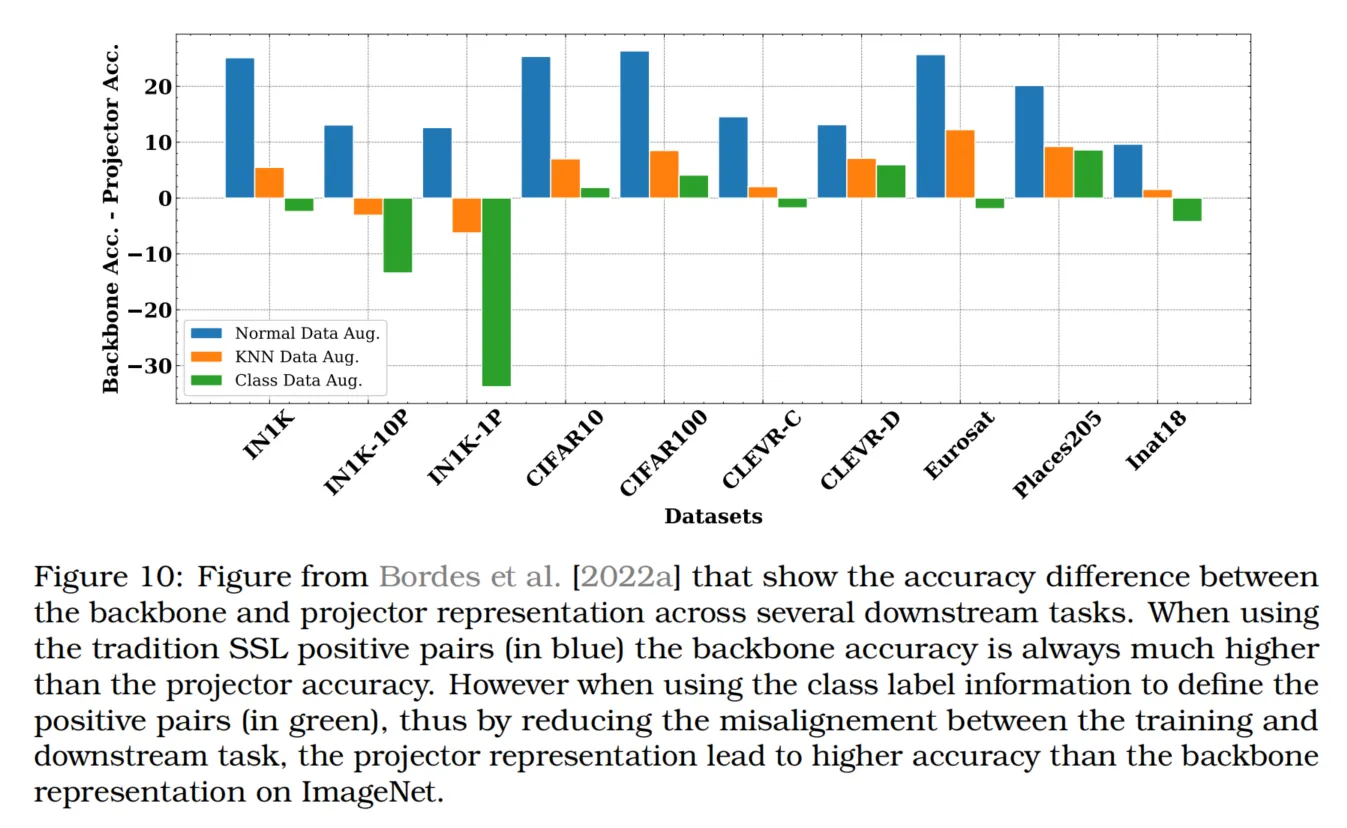
图10:来自Bordes等人[2022a]的图示,展示了在多个下游任务中,骨干网络表示和projector表示之间的准确率差异。当使用传统的SSL正样本对(蓝色)时,骨干网络的准确率始终显著高于projector的准确率。然而,当使用类别标签信息来定义正样本对(绿色),即通过减少训练任务和下游任务之间的不一致性,projector表示在ImageNet上的准确率高于骨干网络表示。
使用projector来处理噪声图像增强
Projector还可以用于减轻数据增强噪声带来的影响。如3.1节所述,SSL方法通常会对输入图像进行随机增强,以生成同一图像的两个不同视图。在某些情况下,对两个截然不同的视图强制不变性可能会成为一种强约束,反而会影响性能,例如当两个视图的内容差异很大时。为展示projector在这方面的作用,我们使用“oracle”(如一个在ImageNet上完全监督训练的ResNet50)在语义上相似的图像增强情况下,对VICReg [Bardes et al., 2021]进行了有projector和无projector的预训练,并在100个epoch后记录了线性探测结果,见表2。没有projector且有oracle的情况下,Top-1性能比没有oracle的情况下高出6.3%。然而,当有projector时,使用oracle去除噪声视图仅将Top-1性能提升了0.6%。这表明projector在SSL训练过程中可能起到了处理不一致或噪声增强视图的作用。
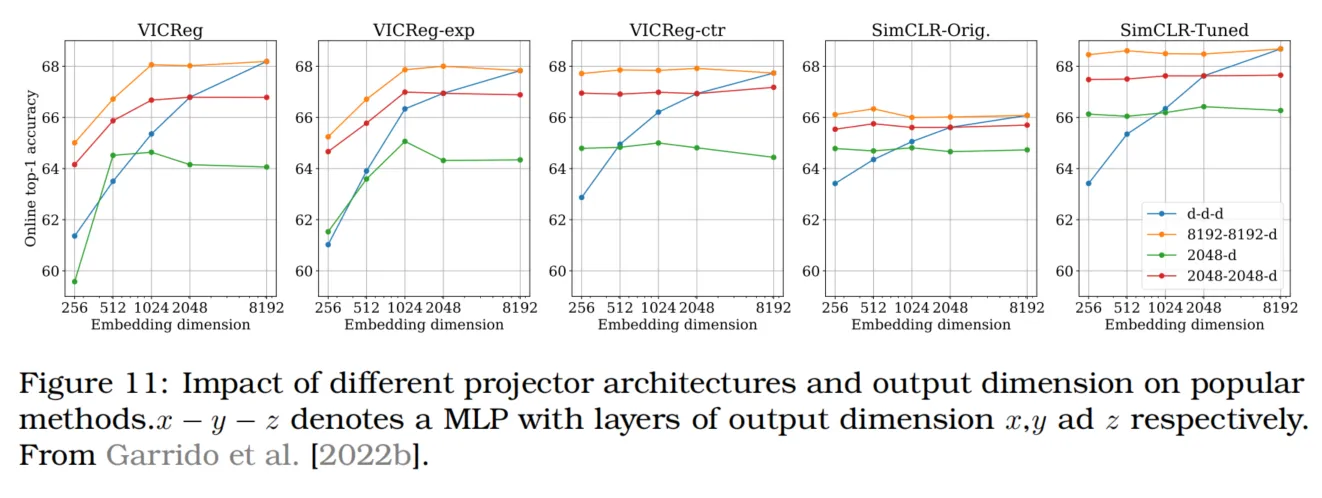
Projector输出维度的影响
类似于对比方法需要大批量大小的要求,大输出维度的projector被认为是基于协方差的方法的需求。Zbontar等人[2021]的图4和Bardes等人[2021]的表12中展示了这一点:在ImageNet上的Top-1准确率下降可达15%。Garrido等人[2022b]指出,这种下降是由于projector中间层和输出维度以及损失权重需要同时调整的缘故。通过调节这些参数,VICReg的Top-1准确率在256维嵌入下从55.9%提高到65.1%。性能峰值出现在1024维,并随后趋于平稳。尽管VICReg对projector的输出维度比SimCLR更敏感,但其鲁棒性比之前认为的更高,并不一定需要非常大的输出维度。由于与Barlow Twins方法的相似性,可以预见其结果也是可比的。
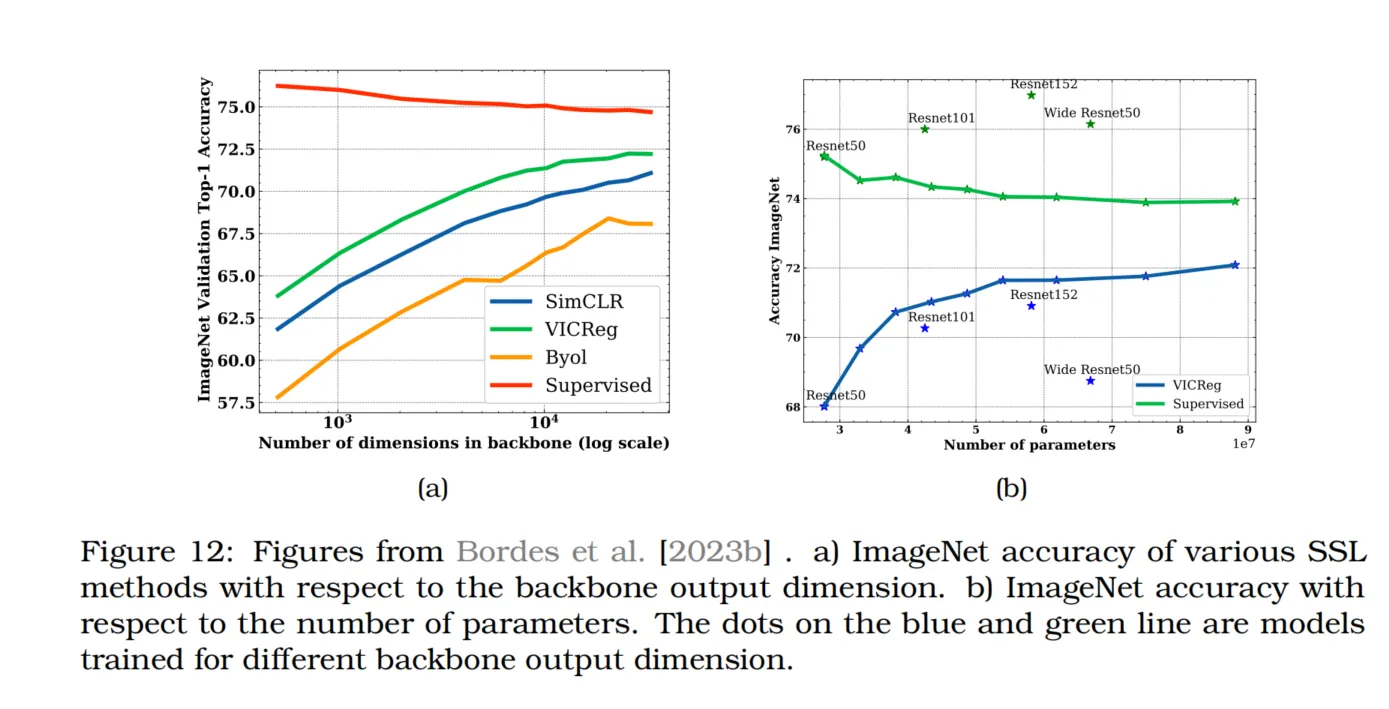
骨干网络输出维度的影响
最近的研究还探讨了骨干网络(backbone)维度的影响。Dubois等人[2022]发现,当使用CISSL时,较大的骨干网络表示能够提升线性探测性能。Bordes等人[2023b]则更深入地研究了骨干维度对常见SSL方法(如VICReg、SimCLR和BYOL)的影响。研究显示,传统的监督方法在骨干网络维度增加时性能会下降,而SSL方法却能极大地从更宽的骨干网络表示中获益,如图12a所示。事实上,在SSL中增加ResNet的宽度比增加其深度或宽度更为有利,如图12b所示。这一观察结果突显了目前SSL中使用的架构(通常与监督学习相同)可能并不是最佳选择。
Projector诱导的表示属性
Mialon等人[2022]提出,projector通过在VICReg、Barlow Twins和W-MSE [Bardes et al., 2021; Zbontar et al., 2021; Ermolov et al., 2021]的随机projector设置中实现特征的成对独立性。特别地,更宽的projector可以实现更高程度的独立性。在非监督学习中,这种成对独立性(或其弱形式)比相互独立性更适合用于真实世界数据集(如ImageNet)[Li et al., 2019]。如果需要完全的相互独立性,可能需要寻求替代的SSL正则化方法,而不是VICReg。值得注意的是,将VICReg(即VICReg中的反塌缩项)应用于projector的输出并不需要对projector参数进行优化,而是对编码器参数进行优化。这一分析是否完全适用于其他SSL方法仍是一个开放问题。
在没有projector的情况下进行SSL训练
Jing等人[2022]提出了DirectCLR,表明通过在子向量上应用InfoNCE(SimCLR)目标并不需要可训练的projector,就足以使DirectCLR在ImageNet的Top-1准确率上超越带线性projector的SimCLR。
3.3 自监督学习中的均匀先验及其在不平衡数据上的失败
尽管自监督学习(SSL)方法最近取得了显著成功,但它们在不平衡数据集上的性能较差,这一重要限制对在大规模未处理数据中应用SSL方法提出了挑战。Assran等人[2022a]解释了这一限制的原因在于许多SSL方法中存在隐藏的均匀先验。通过在表示空间中均匀分布数据,SSL方法倾向于在给定的小批量中找到最具区分度的特征。当类别标签均匀分布时,模型学到的最具区分性的特征将是类别特定的。然而,在使用不平衡数据时,小批量中的最具区分性的特征可能不再是类别特征,而是更低级别的信息,从而导致下游分类任务性能下降。为了解决这一问题,Assran等人[2022a]在SSL方法MSN [Assran et al., 2022c]中引入了一个额外的正则项,以改变SSL聚类的分布。
3.4 教师-学生架构的特定技巧
3.4.1 滑动平均教师的作用
尽管原始的BYOL方法基于对目标(教师)网络权重的指数滑动平均(EMA)更新,但随后研究表明EMA并不是必需的(即在线网络和目标网络可以相同)。SimSiam [Chen and He, 2021]也证实了这一点,只要预测器更新得更频繁或者学习率更高即可。在DQN的情况下,带有EMA的目标网络有助于消除偏差[Fan et al., 2020; Piché et al., 2021],并且可以通过使用合适的正则化器来消除目标网络中的EMA。对于BYOL,当在线网络的梯度被截断(即目标网络的衰减率为0)时,如Grill等人[2020]的表5所示,会导致网络塌缩。Pham等人[2022]展示了指数滑动平均提供了训练稳定性,这种稳定性甚至可以在非学生-教师框架(如SimCLR)中使用。他们特别指出,在SimCLR的projector上应用EMA更新可以提升性能。Wang等人[2022c]进一步表明,在教师-学生设置中使用其他形式的不对称(例如在学生侧进行更强的增强)也有利于训练。
3.4.2 自监督标签中的预测器作用
预测器网络在BYOL中发挥了关键作用,通过从学生网络的表示预测教师网络的表示。Shi等人[2020]显示,移除预测器会使ImageNet的Top-1准确率从68%骤降至21%(相比于BYOL中的原始两层MLP预测器)。在Shi等人[2020]的图1中,他们证明了即使使用线性预测器,也能在10-20个epoch的训练中从不佳的初始化状态中恢复。对于SimSiam,Chen和He[2021]的表1显示,移除预测器同样会导致网络塌缩,Top-1准确率低于1%。Tian等人[2021]进一步证明,在存在预测器的情况下,BYOL和SimSiam的训练动力学包含非平凡的稳定固定点,从而避免在训练过程中陷入平凡解,即使这些平凡解在全局上是最优的。他们还提出了一种对比方法DirectPred,通过在训练过程中直接使用特征值分解设置预测器,并在ImageNet上获得了可比的性能。其后续工作DirectSet [Wang et al., 2021b]进一步减少了特征值分解的开销。
3.5 标准超参数的作用
SSL研究中的一个常见问题是每种方法的超参数配置不同,因此不同SSL方法或模型之间的直接比较通常具有挑战性。本节将介绍和描述每个超参数的影响,以帮助SSL研究人员根据自己的设置确定最重要的参数。
3.5.1 小批量大小的作用
最初认为SimCLR或MoCo等对比方法需要较大的批量大小或记忆库才能有效。然而,事实证明这并非必要,因为这两种方法在小批量条件下也能有效。Chen等人[2020b]的附录中讨论了学习率的平方根缩放,这在ImageNet的100个epoch训练中将Top-1准确率提升了多达5个百分点。同样,Bordes等人[2023a]研究了小批量下学习率的影响,发现可以在不显著降低性能的情况下在单个GPU上训练SimCLR。此外,DCL [Yeh et al., 2021]等研究表明,通过调整超参数设置,可以在批量大小为256或更大的情况下达到最佳性能,同时在MoCo中使用队列大小为256或更大的情况下,只需移除softmax分母中的正样本即可。同样,Zhang等人[2022a]显示,通过分解MoCo中的字典并为正负样本对使用不同的温度参数,可以提高字典维度的鲁棒性。
3.5.2 学习率(调度器)和优化器的作用
以下概述了常见方法中学习率调度器和优化器的标准设置。为了确定学习率,通常根据批量大小按照Goyal等人[2017]的启发式方法来调整基本学习率:学习率 = 批量大小 / 256 × 基本学习率。在ImageNet预训练中,VICReg、Barlow Twins、BYOL和SimCLR使用0.2-0.3的基本学习率并结合LARS优化器[You et al., 2017]。此外,对于Barlow Twins等方法,更新偏差项和批归一化参数时使用更小的学习率(如0.0048)。而MAE、DINO和iBot等方法则使用AdamW优化器[Loshchilov and Hutter, 2017],学习率范围为1e-5到5e-4。大多数训练计划包括一个通常为10个epoch的预热期,其中学习率线性增加到其基本值,之后大多数方法使用余弦衰减。
3.5.3 权重衰减的作用
权重衰减是许多SSL方法反向传播中的重要组成部分。BYOL [Grill et al., 2020]的表15显示,没有权重衰减可能导致不稳定的结果。Tian等人[2020b]的图4中解释了权重衰减对初始条件的记忆效果的影响。权重衰减有助于在线网络和预测器更好地建模增强的不变性,而不受初始条件的影响。
3.5.4 Vision Transformers的特殊考虑
训练Vision Transformers(ViT)[Dosovitskiy et al.]需要特别关注。它们更容易出现塌缩和不稳定性,并且对超参数设置更为敏感[Touvron et al., 2021a]。
-
批量大小:Chen等人[2021b]发现,用大批量(例如4096)训练联合嵌入ViT SSL方法可能会导致不稳定性。这种不稳定性不会反映为最终准确率的大幅下降,但在训练期间当梯度的L∞-范数剧增时,会在kNN探测准确率中出现下降。使用随机(而非学习到的)补丁投影层将像素补丁嵌入ViT的输入标记中,能够稳定MoCo-V3、SimCLR和BYOL的训练,并提高最终准确率。Goyal等人[2017]和Dosovitskiy等人建议使用10k次迭代的学习率预热期也有助于训练稳定性。Caron等人[2021]则发现使用非常小的批量(128)进行训练时k-NN准确率会下降。因此,批量大小1024或2048似乎是ViT SSL预训练的最佳选择。
-
补丁大小:Caron等人[2021]发现使用更小的补丁尺寸(5×5或8×8而非16×16)可以提高DINO ViT预训练的线性探测准确率。虽然增加补丁尺寸会减少运行时间,但会增加内存使用,使得训练8×8以下的补丁变得困难。
-
随机深度(Stochastic Depth):最初来源于自然语言处理,随后被用于视觉模型[Touvron et al., 2021b],用于训练更深的模型。它通过随机丢弃ViT的块作为正则化。每层的丢弃率可以线性依赖于层深度或均匀设置。对于较大的模型(如ViT-L、ViT-H等),这非常重要。例如,Touvron等人[2022]在ViT-H模型中使用
0.5的丢弃路径率。对于较小的模型(如ViT-B),这种正则化通常会降低性能[Steiner et al., 2021]。
-
层衰减(LayerDecay):逐层几何减少学习率。换句话说,最后一层不会受到影响,而第一层的学习率非常小。在SSL视觉模型中,LayerDecay在下游任务上进行微调时提高了性能[Bao et al., 2021b; Zhou et al., 2022a; He et al., 2022]。根据模型大小,该参数设置在0.65到0.85之间——较大的模型通常需要更高的值,因为层数更多。其基本原理是SSL构建了强大的模型骨干,因此只需微调最浅的层即可。
-
层缩放(LayerScale):对transformer的每个残差块产生的向量进行按通道乘法。它增加了优化的稳定性,并允许更深的ViT模型(大于ViT-B)。
-
[cls] token:如果方法不显式需要[cls] token,用补丁tokens的平均值代替类token可以节省内存,并且对网络的准确率影响不大[Zhai et al., 2022a]。
3.6 高性能掩码图像建模的技术
虽然存在多种掩码预训练(Masked Image Modeling, MIM)的方法,但最先进的系统通常将MIM与其他技术结合使用。例如,ConvNextV2架构在发布时是ImageNet上的最新技术(仅使用公开数据进行训练),采用了MAE预训练[Woo et al., 2023]。值得注意的是,作者指出,仅使用MAE框架对ConvNextV2进行预训练并不能达到最佳效果。他们建议添加一种称为“全局响应归一化”的新型归一化层,以达到最新技术水平的性能[Woo et al., 2023]。
在其他宣称在图像分类和语义分割方面达到最新性能的工作中,MIM预训练与蒸馏(distillation)技术相结合。一些MIM方法在像素空间中重建输入图像的掩码部分,而另一种选择是使用教师网络生成未掩码图像的目标表示。Zhou等人[2022a]提出了iBOT,它在基于蒸馏的MIM中使用ViT作为教师和学生,并在ImageNet分类任务上优于先前的方法。随后,Liu等人[2022b]提出了dBOT,一种更新的基于蒸馏的MIM方法,在图像分类和语义分割上也达到了最新性能。他们的一个主要发现是,如果分阶段进行蒸馏,教师模型的选择就不需要特别谨慎。在这种情况下,教师模型会定期更新以匹配学生的权重,然后学生会重新初始化。Oquab等人[2023]也采用类似的蒸馏方法,从一个ViT-g教师训练小模型,其性能远远优于从头训练。这些研究表明,将蒸馏与MIM结合是极其有效的。
对于利用MIM来超越之前工作的目标检测器来说,MIM与性能较高的金字塔型ViT(如Swin)的结合至关重要。由于金字塔型ViT会对补丁进行折叠,随机掩码可能会导致某些局部窗口中没有信息。Li等人[2022d]提出了一种称为“均匀掩码”的方法,适用于这些模型的层次结构。他们限制掩码,使每个局部窗口中被隐藏的信息量相等,以确保每个窗口中仍有一些信息保留。这种技术使得自监督模型(在ImageNet1K上)在目标检测基准测试中超越了监督模型(即使是在ImageNet22K上)[Li et al., 2022d]。
3.7 自监督学习模型的评估
3.7.1 使用标签进行评估
自监督预训练主要在图像分类任务上进行评估,因为图像分类在计算机视觉领域中已有数十年的核心地位。三种常见的评估协议是:k-最近邻(KNN)、线性探测和全量微调(按复杂度排序)。这些是离线评估,独立于自监督训练过程进行。与之相对的是在线评估,它是在训练过程中进行的。虽然在线评估可以提供下游性能的有用信号,但由于它与变化中的自监督学习目标同步优化,可能会产生误导。此外,除了需要下游任务标签的这些评估程序,RankMe [Garrido et al., 2022a]最近被提出作为一种成本更低的替代方法,用作预测最终准确率的“oracle”而无需实际训练。
KNN是机器学习中最为人知的算法之一,并广泛应用于各个领域。在图像分类中,KNN分类器通过其邻居的标签确定数据点的标签。具体而言,首先用模型提取出所有训练数据集中图像的冻结特征(通常为l2正则化)。要分类一张新图像,我们提取其特征表示,并检索出它的k个最近邻,即在训练集中与具有最高余弦相似度的k个向量。然后,使用多数投票方案:每个邻居在其对应标签上计数+1,最终选择得票最多的标签。一些更复杂的方法使用加权投票方案,例如DINO实现中采用 [Caron et al., 2021]。这种加权方法可以应对不平衡训练集和非独立同分布的特征,通常能产生更准确的结果,但会引入额外的超参数。
K-NN分类器的优势在于其对超参数的依赖性小,部署速度快且轻量化,不需要任何领域适应。
线性探测
在线性探测评估(linear probing evaluation)中,在预训练的特征表示上训练一个线性分类器,这一评估方法由Zhang等人[2016, 2017]引入。它是最受欢迎的评估协议,原因有几点:其准确率较高,性能依赖于表示的质量,因为其判别能力较低;它模拟了如何实际使用这些特征;最后且同样重要的是,它的计算成本不高。通常,只需在冻结的骨干网络末端添加一个线性层,并优化其参数若干个epoch(大约100个)。有时,正如Bao等人[2021b]所介绍的,可以利用线性评估的轻量化特性,同时评估多个线性头,以测试多种超参数(如学习率、特征平均化或使用ViT架构中的类标记、特征数量等)。线性探测也可以在训练过程中进行,通过在表示上截断梯度来实现。尽管这只是一种近似,在线性探测非常便宜,因为它重复利用了SSL预训练的计算,并且如图13所示,能很好地反映下游性能。
多层感知器(MLP)
与简单的线性探测相比,还可以使用两层或三层的多层感知器(MLP)来提取SSL模型学习到的信息。非线性评估在SSL研究中较少出现,但在学习到的特征不可线性分离、且线性模型难以提取信息时,它是必要的。事实上,将线性探测与非线性探测的结果进行比较,可以帮助我们了解表示结构的良好程度。Bordes等人[2023a]展示了一些使用线性和非线性探测的不同评估方式的比较结果。如图13所示,使用多层感知器探测器代替线性探测器可以提高准确率。然而,增加探测器容量的主要问题是过拟合:最佳的MLP头可能不会出现在100个epoch后,如图13所示。
全量微调
《Masked Auto-encoders (MAE)》论文[He et al., 2022]重新引入了全量微调作为主要评估指标。其主要论点是,线性探测与微调和迁移学习性能无关,而且小型MLP头无法评估方法在创建强但非线性特征方面的能力。随后的大多数研究[Bao et al., 2021b; Zhou et al., 2022a; Dong et al., 2021]都集中在这种类型的评估上(有时不报告线性或MLP结果)。研究表明,在微调方面,对比方法表现不如掩码图像建模(MIM),因为对比方法的优化不够友好[Wei et al., 2022]。微调是这些评估方法中计算成本最高的,因为它需要重新训练整个网络。ImageNet上的常见基准在较小的ViT模型上进行100个epoch的优化,而较大的模型进行50个epoch[He et al., 2022]。其他研究[Bao et al., 2021b; Peng et al., 2022; Wang et al., 2022b]先在ImageNet-21k上微调60个epoch,再在ImageNet-1k上进一步微调,这相当于预训练阶段成本的1/5到2倍。
3.7.2 无标签评估
正如之前讨论的,大多数评估依赖于标签并训练辅助模型。这会使评估变得昂贵,并且对超参数或其优化敏感。为了缓解这些问题,已经提出了多种方法来在不依赖标签的情况下评估或帮助调整超参数。例如,使用自监督任务(如旋转预测)可以在没有标签的情况下进行性能评估,正如Reed等人[2021]在数据增强策略选择中的应用所展示的。然而,这种方法的缺点是需要训练用于自监督任务的分类器,并假设旋转并未成为预训练增强的一部分,否则模型会对其不变。
Li等人[2022a]使用表示的特征值谱与损失值结合来评估性能。尽管显示出与性能的相关性,但这需要训练一个基于秩和损失值的性能分类器,因此难以用于无监督评估。Agrawal等人[2022]提出了α-ReQ方法,通过观察projector之前表示的特征值谱衰减来评估方法。
另一种简单的SSL评估方法是RankMe,由Garrido等人[2022a]提出。其核心思想是使用表示的有效秩(effective rank),定义为嵌入奇异值分布的熵。它的计算公式如下:
这种方法被证明是获得良好性能的必要条件,但也可能在获得全秩表示的情况下出现退化结果(例如,从高斯分布独立采样的随机矩阵)。尽管它不能用于评估不同方法,但在超参数选择方面表现良好,如表3所示。
3.7.3 超越分类任务的评估
虽然分类是评估自监督学习模型的常用性能指标,但也需要考虑其他类型的视觉任务。目标检测和语义分割等任务要求模型学习更复杂的视觉信息表示,因此逐渐受到欢迎。最近的一些研究[Caron et al., 2021; Zhou et al., 2022a; Bardes et al., 2022]展示了自监督学习在这些任务上的有效性。然而,目前没有针对这些任务的标准化评估协议。现有的评估方法包括在下游任务上微调编码器或将编码器用作特征提取器。需要进一步研究以在自监督学习的背景下建立这些任务的标准化评估协议。
3.7.4 可视化评估
另一种评估表示中包含或缺失的信息的方法是使用解码器将该表示映射回像素空间。有些方法(如[He et al., 2022])包含特定的解码器,便于进行这样的视觉分析,但大多数SSL方法并未附带解码器。为了解决这个问题,并允许研究人员可视化任何类型SSL方法可以学习到的内容,Bordes等人[2022b]建议训练一个条件生成扩散模型,以SSL表示作为条件。通过分析在特定条件下生成的样本中保持不变的信息以及不保持不变的信息(由于生成模型的随机性),可以获得表示中包含的信息的线索。
如果一个表示编码了关于每个像素的所有信息,条件生成模型将利用所有这些信息来进行完美重建,从而在不同样本间不产生变化。如果表示仅编码类别信息,条件生成模型将只能使用类别信息来重建图像,这意味着在生成不同样本时,对象类别保持不变,但背景/上下文/颜色可能在样本间变化。图14展示了Bordes等人[2022b]如何使用RCDM来比较在projector层和骨干网络层学习的表示。在该图中可以看到,projector层的表示在颜色/背景信息方面更具不变性,而骨干网络层的表示则不具备这种不变性。
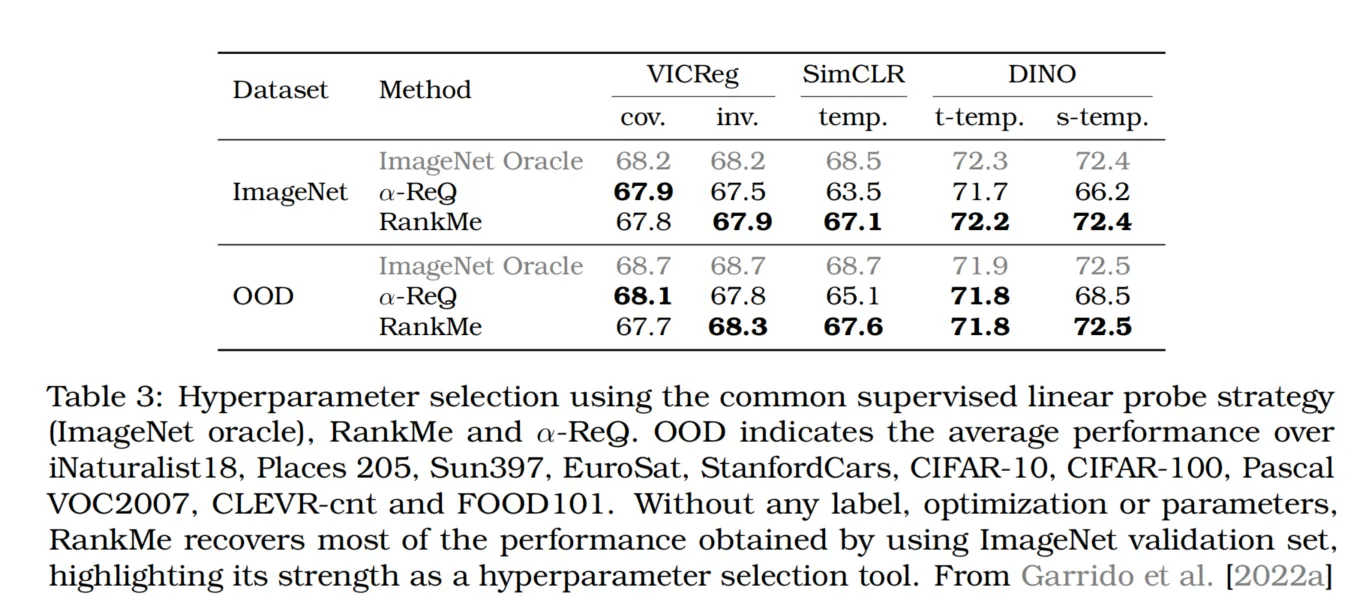
表3:使用常见的监督线性探测策略(ImageNet oracle)、RankMe和α-ReQ进行超参数选择。OOD表示在iNaturalist18、Places 205、Sun397、EuroSat、StanfordCars、CIFAR-10、CIFAR-100、Pascal VOC2007、CLEVR-cnt和FOOD101上的平均性能。无需任何标签、优化或额外参数,RankMe恢复了大部分通过ImageNet验证集获得的性能,突显了其作为超参数选择工具的优势。数据来自Garrido等人[2022a]。
3.8 加速训练
3.8.1 分布式训练
训练自监督模型通常需要较大的批量大小[Chen et al., 2020b; He et al., 2020b],或者可以通过增加批量大小显著加速训练,而批量大小的上限取决于训练设备的内存容量。分布式训练通过在多个设备上并行运行分割批次,从而增加了整体批量大小。这主要通过DDP(Distributed Data Parallel)或FSDP(Fully Sharded Data Parallel)实现,可以在FairScale [FairScale, 2021]或Apex [NVidia, 2021]等库中找到。然而,一些自监督方法依赖于当前批次的统计信息来计算损失值[Chen et al., 2020b; Zbontar et al., 2021; Bardes et al., 2021],在多设备分布训练时必须考虑到这一点。在本节中,我们介绍了分布训练常见自监督学习方法时需要考虑的要素。我们称“有效批量大小”为分布在所有设备上的完整批次大小,“每设备批量大小”为每个设备上的子批次大小。
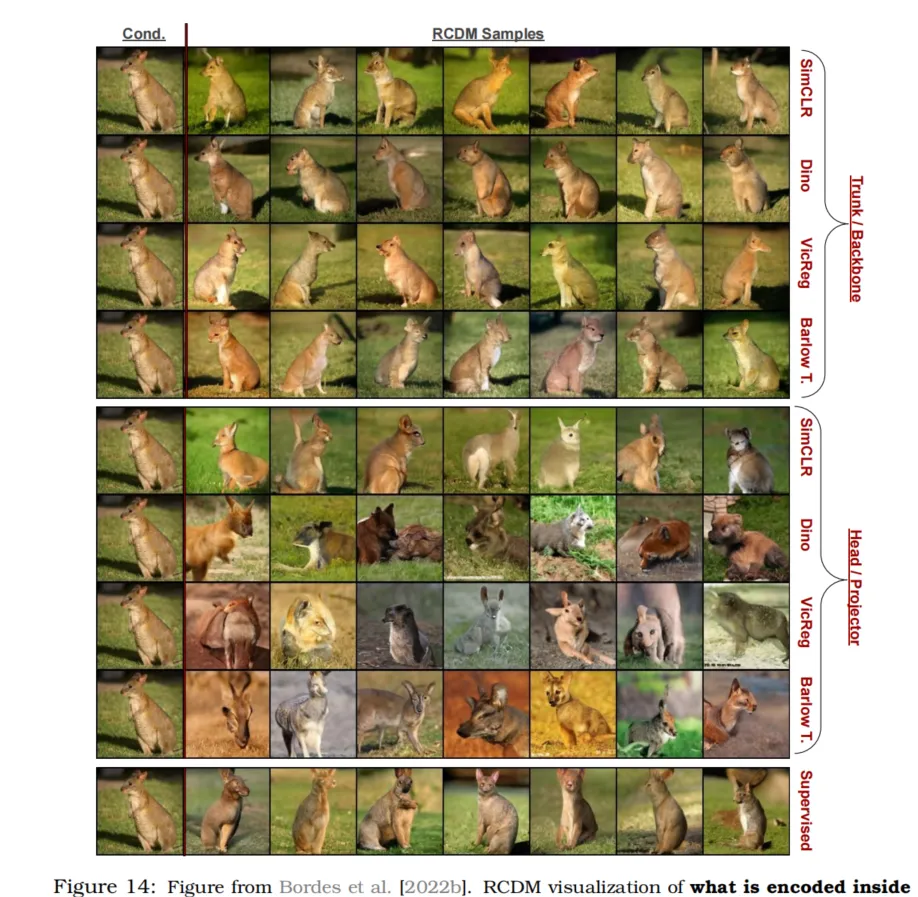
图14:来自Bordes等人[2022b]的图示。该图通过RCDM(条件生成扩散模型)可视化不同表示中编码的信息。第一至第四行展示了以常规ResNet50骨干网络表示(大小为2048)为条件生成的样本;第五至第八行则展示了以各种自监督学习模型的projector/头部表示为条件生成的样本。(请注意,为每种表示专门训练了单独的生成模型)。在一组生成图像中表现出一致/稳定的特征,揭示了条件表示中编码的信息;而变化的特征则展示了未被表示编码的信息。
可以清楚地看到,projector表示仅保留了全局信息,而不包含上下文信息,这与骨干网络表示相反。这表明,SSL模型中的不变性大多是在projector表示中实现的,而非骨干网络中。此外,这也证实了表a中的线性分类结果,即骨干网络表示更适合分类任务,因为它们比projector表示包含更多关于输入的信息。
同步批归一化
批归一化(Batch Normalization)是稳定神经网络训练并提高网络性能的最常见技术之一。它存在于大多数用于自监督学习的卷积骨干网络中,特别是在ResNet中。批归一化使用当前批次的统计信息,因此在分布式训练中需要聚合这些统计信息。这可以在PyTorch中轻松实现,只需按以下方式包装分布式模型即可:
python展开代码model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
这将把网络中的所有BatchNorm模块替换为自定义BatchNorm类,以自动聚合统计信息。
聚合批次以精确计算损失
批归一化并不是唯一依赖批次的操作,多种自监督损失函数也依赖批次。例如,SimCLR [Chen et al., 2020b]使用当前批次中的样本作为其对比损失的负样本,而VICReg [Bardes et al., 2021]则计算其嵌入的协方差矩阵。在这些情况下,需要手动将每个设备的批次聚合为完整批次。这可以通过PyTorch中的all_gather操作完成,但此操作不允许反向传播。因此,我们实现了一个支持反向传播的自定义gather操作,代码如下所示:
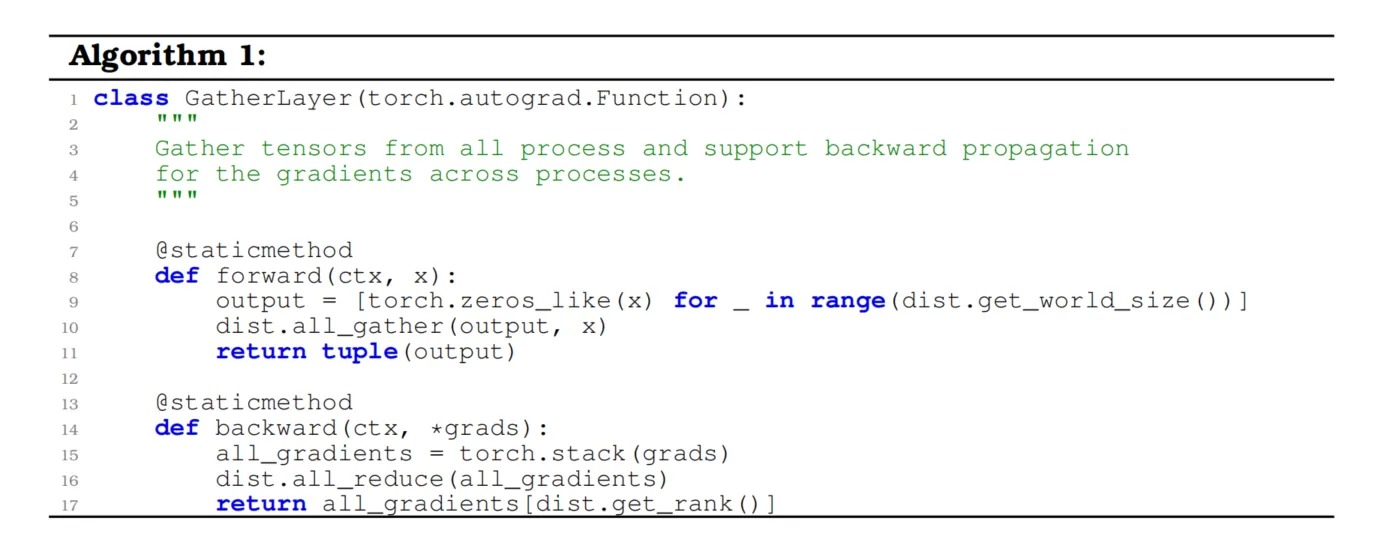
python展开代码
import torch
import torch.distributed as dist
class GatherLayer(torch.autograd.Function):
"""
从所有进程中收集张量,并支持跨进程的梯度反向传播。
"""
@staticmethod
def forward(ctx, x):
# 初始化一个列表,用于存储每个进程上的张量
output = [torch.zeros_like(x) for _ in range(dist.get_world_size())]
# 使用 all_gather 收集所有进程上的张量
dist.all_gather(output, x)
# 将收集到的张量列表转换为元组返回
return tuple(output)
@staticmethod
def backward(ctx, *grads):
# 将所有梯度堆叠成一个张量
all_gradients = torch.stack(grads)
# 使用 all_reduce 聚合所有进程上的梯度
dist.all_reduce(all_gradients)
# 返回当前进程的梯度
return all_gradients[dist.get_rank()]
在分布式训练中,我们对梯度使用了 all_reduce 操作来求和,因为DDP(Distributed Data Parallel)会在之后将其除以设备数量。可以通过简单调用 FullGatherLayer.apply(x) 来使用此操作。对于上面提到的方法,需要在计算损失之前对嵌入进行此操作。
附加技巧
-
使用有效批量大小:我们建议在训练脚本中使用有效批量大小作为参数,并用于比较不同的训练运行结果。
DataLoader类接收每设备的批量大小参数,这可以通过将有效批量大小除以设备数量(即PyTorch中的world_size)获得。 -
自适应学习率:建议使用自适应学习率,其与有效批量大小成比例。例如,使用
effective_lr = base_lr * effective_batch_size / 256,其中base_lr是训练脚本的参数。这种做法在更改批量大小时减少了对学习率搜索范围的需求。对于较小的批量大小,Chen等人[2020b]建议使用effective_lr = base_lr * \sqrt{(\text{effective\_batch\_size})} / 256。
这样做的目的是在调整批量大小时,保持学习率与批量大小之间的平衡,从而优化训练过程的稳定性和效果。
3.8.2 使用FFCV及其他方法进一步加速训练
由于大多数联合嵌入SSL方法需要使用多种手工设计的数据增强,因此数据处理可能成为训练SSL模型的瓶颈。一些方法采用了DALI作为PyTorch Vision的替代数据加载器,而其他方法则使用基于FFCV库的FFCV-SSL[Leclerc et al., 2022]。FFCV-SSL[Bordes et al., 2023a]展示了使用FFCV可以在不到2天内使用单个GPU训练SimCLR,或者在8个GPU上训练只需数小时(如图15所示)。
3.8.3 加速Vision Transformers的训练
加速ViT(Vision Transformer)的训练有两个原因。首先,ViT不需要处理所有图像补丁,这一点在使用掩码预测预训练目标(如MAE [He et al., 2022]或Masked Siamese Networks [Assran et al., 2022b])时尤为重要。例如,使用ViT和这些目标,Data2vec 2.0 [Baevski et al., 2022]在32个GPU上仅预训练3小时后即可达到84%的Top-1准确率。
第二个原因与架构有关。由于Transformers [Vaswani et al., 2017]已被广泛应用于计算机科学的各个领域,许多研究致力于减少注意力机制的计算和内存需求。一种方法是采用低秩和/或稀疏近似机制[Kitaev et al., 2020; Choromanski et al., 2020; Wang et al., 2020a; Chen et al., 2021a; Zaheer et al., 2020]。例如,Li等人[2022b]在自监督视觉模型中使用稀疏自注意力以提高效率。另一种方法是利用I/O优化技术[伊万诺夫 et al., 2021],其中最知名的可能是FlashAttention [Dao et al., 2022]。
这些加速方法已在多个开源库中提供:如Fairseq[Ott et al., 2019]、FairScale[FairScale, 2021]、XFormers[Lefaudeux et al., 2022]、Apex[NVidia, 2021]等。此外,加速训练ViT的一个简单方法是使用PyTorch的bfloat16精度,该精度比float16具有更宽的数值范围,从而避免在训练中遇到的数值不稳定问题,同时保持与float32相同的精度范围。
通过这些方法,训练速度可以显著提高,尤其是在大型数据集和复杂模型的训练中。
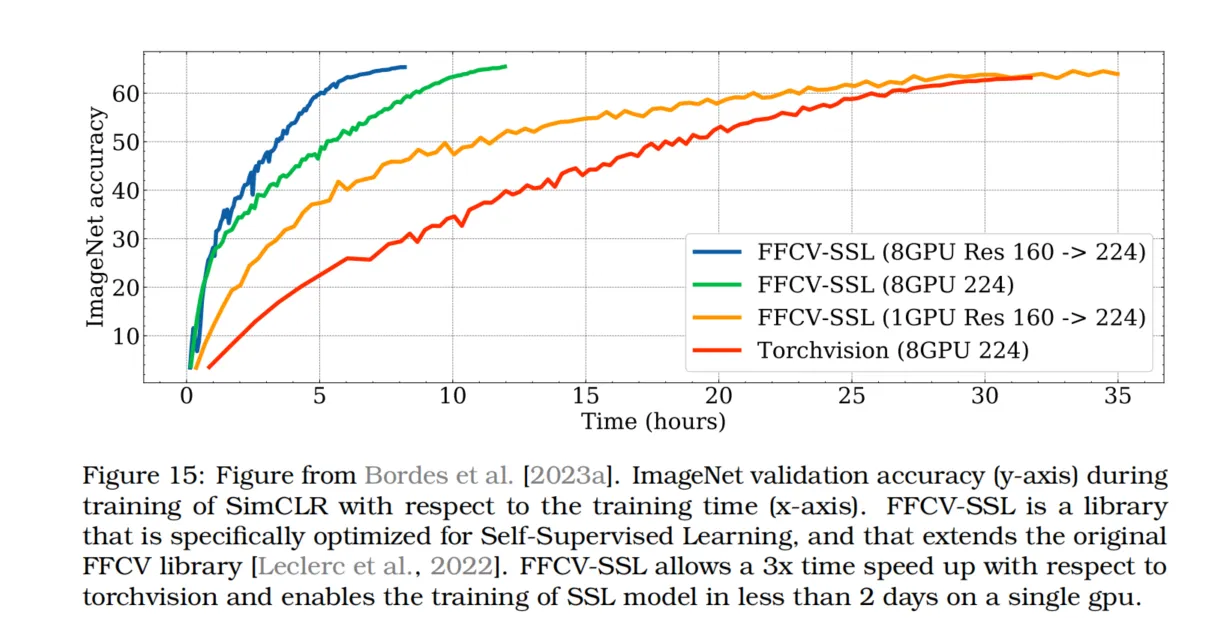
图15:来自Bordes等人[2023a]的图示。图中展示了SimCLR在训练过程中的ImageNet验证准确率(y轴)与训练时间(x轴)之间的关系。FFCV-SSL是一个专为自监督学习优化的库,扩展了原始FFCV库[Leclerc et al., 2022]。使用FFCV-SSL,相比torchvision可以实现3倍的加速,使得在单个GPU上用不到2天即可完成自监督学习模型的训练。
4. 扩展自监督学习到图像和分类之外
4.1 其他数据领域的策略
在大模型的预训练中应用自监督目标,不仅在视觉系统中流行,也在音频、文本和表格数据中得到了广泛应用。然而,自监督学习(SSL)方法在这些不同领域的表现不一——在语言模型方面取得了显著进展,但在表格数据上取得的成功有限。这可能反映了自监督学习在某些领域的适用性较好,也可能是因为SSL文献中对不同领域的关注程度差异较大。
将SSL技术应用于这些数据领域中的任意一个需要特别注意,因为每个领域都有独特的挑战,要求采取特殊的考虑。例如,应用于视觉数据的SSL通常依赖于数据增强,这些增强方法在语音信号上可能并不自然适用。在对比学习中,“正样本对”可以从同一图像的不同视图到完全不同的音频片段。尽管如此,对比和生成目标均可应用于这些其他数据领域。一个在不同数据类型中都普遍适用的技术是掩码预测。无论是预测句子中的缺失单词、图像中的像素,还是表格中的条目,掩码预测都是跨领域SSL方法中的有效组成部分。
这一部分并非对其他数据模态自监督学习的全面综述,因为每个领域都很庞大。可以参考各领域的特定综述,如Liu等人[2022a]关于音频、Schiappa等人[2022b]关于视频、Min等人[2021]关于文本以及Rubachev等人[2022]关于表格数据。相反,这一部分旨在讨论SSL在音频、文本和表格数据中的一些有趣的相似性和差异。
音频数据
音频信号(无论是原始音频还是梅尔频谱图)与图像有很多共同之处。作为神经网络的输入,这两者有很强的相似性。例如,卷积在这里很有用[Oord et al., 2016; Schneider et al., 2019; Baevski et al., 2021]。但作为SSL的数据,主要的差异也很明显。例如,水平翻转图像通常不会改变其语义意义(这是非常流行的数据增强方法),但对于语音记录,这会完全扭曲数据。同样,在图像中通常用随机像素进行掩码,而梅尔频谱图的两个维度分别代表时间和频率,用水平和/或垂直带进行掩码更为有效[Wang et al., 2020b]。此外,除语音外的其他音调(如背景噪音、房间噪音)在寻找对比学习的正样本对时带来了独特的挑战,即防止学习到的表示过拟合于片段中的噪音[Oord et al., 2018; Wang et al., 2020b]。事实上,高频噪音伪影通常与语义无关,使得输入空间中的重构比其他领域(如文本)更加复杂。另一方面,多模态模型可以将一个音频片段及其对应的文本[Sermanet et al., 2018; Chung et al., 2018]或视频的某些帧与相应的音频片段[Zhao et al., 2018; Alwassel et al., 2020]视为正样本对用于对比学习。
视频数据
大多数SSL图像方法都有对应的视频SSL方法。例如,Feichtenhofer等人[2021]将SimCLR、MoCo、SwAV和BYOL方法推广到时空视频数据。事实上,在这些方法中,可以将同一视频的不同时间片段之间的相似性考虑进去。最近,针对视频的掩码自动编码目标基于与图像相同的理念,但通过在时间轴上掩码图像块或管道[Feichtenhofer et al., 2022; Tong et al., 2022; Girdhar et al., 2022]。此外,使用SSL视觉预训练模型进行视频下游任务(如动作识别)是常见的做法。例如,对于ViT,将贴块嵌入的卷积层从2D转移到3D时,可以沿时间轴重复权重[Feichtenhofer et al., 2022]。视觉模型可以通过在视频任务上微调时作为初始化,从而迁移到视频模型[Fang et al., 2022a]。帧特征也可以直接使用,通过在特征顶部附加一个线性层[Radford et al., 2019],或使用更复杂的头部[Ni et al., 2022; Arnab et al., 2021]。在这种情况下,视觉系统被冻结,时间信息在之后学习。
文本数据
与音频数据相比,文本是一种相对干净的输入信号,其用于重构的表示不会过拟合到噪声部分。事实上,最流行的大型语言模型都是通过重构目标训练的,而非其他数据领域常见的对比目标[Radford et al., 2018, 2019; Brown et al., 2020; Devlin et al., 2018]。Word2Vec目标[Mikolov et al., 2013]预测被掩码的训练文本片段,已成为自然语言领域自监督学习的基础目标。尽管不常见,但可以通过对比学习进行语言建模,用于单词或字符的表示学习[Chen et al., 2022]。文本和图像之间的另一个区别在于,文本的掩码标记预测在整个词典上进行。这种方法在图像上并不占主导地位,但也在像素级上尝试过[Chen et al., 2020a]。尽管语言数据的增强方法较少,但不会改变其语义含义,大规模系统通常使用足够的数据和各种类型的掩码来克服这一问题。特别是,下一词预测[Radford et al., 2018, 2019; Brown et al., 2020]类似于掩码字符串中的最后一个标记,而双向编码器则可以在字符串中的任意位置掩码标记[Devlin et al., 2018],或填充更大范围的缺失文本[Raffel et al., 2020; Tay et al., 2022]。单向的下一词预测和双向方法之间的选择导致了下游文本应用中的显著差异[Artetxe et al., 2022]。对于对比学习,正样本对通常通过掩码和/或裁剪输入序列生成[Meng et al., 2021; Giorgi et al., 2021]。也可以通过使用dropout生成正样本对,使同一输入有两个不同的潜在表示[Gao et al., 2021]。此外,一些对比和重构预训练的方法还通过多种其他增强方式扰乱输入,包括文档旋转、句子排列和标记删除[Lewis et al., 2020; Raffel et al., 2020; Wu et al., 2018]。
表格数据
与文本、音频和图像不同,传统机器学习工具在处理表格数据时仍然很受欢迎。尽管在表格数据上的深度学习相对较小,但寻找合理的数据增强策略已是一个研究充分的课题。几个用于表格数据的SSL方法在多种方式上使用了掩码,一些技术还创造性地采用了图像领域开发的增强方法,例如mixup[Zhang et al., 2018]。与图像和音频一样,一些算法旨在生成缺失或损坏的值,而另一些算法则采用对比学习。在组合优化问题中,如混合整数规划(MIP),目标函数被用作指导,生成具有相似目标的正样本对,以及尽管只有少数变量发生微小变化但目标值差异较大的负样本对[Huang et al., 2023]。类似的方法也被用于引导语言生成[Yang et al., 2023]。
掩码重构方法包括了多种掩码策略。此外,在表格数据中常见的做法是预测掩码向量作为预训练任务的一部分[Yoon et al., 2020; Iida et al., 2021]。由于预测掩码本身是预训练目标的一部分,输入中的掩码条目必须被填充,通常这是通过从该列或特征的经验分布中抽样实现的。
使用相同的增强策略,即掩码和从经验边际分布中抽样,Bahri等人[2021]提出了使用对比损失的预训练。他们具体提出了使用InfoNCE损失[Gutmann and Hyvärinen, 2010; Ceylan and Gutmann, 2018]来比较干净输入和损坏输入的
表示。
其他一些研究则详细阐述了如何将生成和对比学习结合起来进行数据增强。例如,表格数据可以分成列组,这样每个样本(行)可以有多个视图[Ucar et al., 2021]。借鉴视觉系统,将CutMix[Yun et al., 2019]和mixup[Zhang et al., 2018]结合使用在表格数据增强中也是有效的[Somepalli et al., 2021]。这些方法生成的增强视图与干净的输入一起用于对比学习。然而,对于SAINT模型[Somepalli et al., 2021]和SubTab[Ucar et al., 2021],对比预训练在与重构损失项结合时效果最佳。
在专注于比较表格数据SSL方法的研究中,Rubachev等人[2022]发现预训练目标通常有助于提升表格模型的性能。但具体而言,他们发现使用标签的预训练目标效果最好,这表明SSL在表格数据领域尚未达到该领域的最高水准[Rubachev et al., 2022]。同样,Levin等人[2023]展示了与计算机视觉不同的是,现有的SSL预训练在表格数据上产生的特征可迁移性比监督预训练更低。
强化学习
SSL已被用于改进视觉输入上的强化学习(RL)。这种设置类似于视频,除了图像序列外,我们还可以访问动作序列。在此领域应用SSL的最常见方法是使用对比学习训练模型,将当前状态表示与下一时间步的表示匹配,或将相同状态在不同增强下的表示匹配。CURL是其中较早的例子[Srinivas et al., 2020]。最近,SSL被用于提升在具有挑战性的Atari100k基准上的样本效率[Kaiser et al., 2020]。一些最新的研究修改了BYOL[Grill et al., 2020]或Barlow Twins[Zbontar et al., 2021],通过将连续时间步的观察图像输入到双路网络的两个分支:SGI[Schwarzer et al., 2021b]和Barlow Balance[Zhang et al., 2022c]用于离线预训练,而SPR[Schwarzer et al., 2021a]将其用作在线设置中的额外目标。表现最佳的方法是EfficientZero[Ye et al., 2021],它修改了MuZero[Schrittwieser et al., 2020],其中一个重要修改是添加了SimSiam[Chen and He, 2020]目标,以训练编码器和前向模型,并在Atari100k上设立了新标准。Parisi等人[2022]提出了基于MoCo的PVR方法,改善了控制任务中的样本效率。Eysenbach等人[2022]展示了RL环境中的对比学习与目标条件RL直接相关,并展示了一种基于InfoNCE的方法在机器人手臂控制任务中表现出色。
SSL已被证明能生成良好的表示以用于行为克隆。Pari等人[2022]展示了经过ImageNet预训练并用BYOL微调的模型可以非常有效地用于机器人在开放、推送和堆叠任务中的视觉模仿,而Arunachalam等人[2022]使用类似的方法并成功地从一个小型的VR采集的操控数据集中学习。Guzey等人[2023]提出了一种方法,通过BYOL从机器人手臂上的触觉传感器中提取信息并改善灵巧操控。Cui等人[2022]展示了BYOL对视觉输入表示的有用性,可以用于用Transformer架构建模目标条件的轨迹。
在将SSL应用于RL时有一些额外的挑战。首先,如果数据是在线记录的,个体观察之间高度相关,并且不满足独立同分布(IID)假设,因此从重放缓冲区中抽样时需要小心。SSL目标在应用于RL代理的数据时可能会失效,因为其容易锁定“慢特征”[Sobal et al., 2022]。例如,对比目标可能会学习仅通过观察天空中的云模式来区分自驾数据集中的帧,因此必须谨慎设计增强方式以去除图像中无用的静态特征,或相应地抽样数据。
SSL不仅用于提升样本效率,还用于改善探索。Guo等人[2022b]提出了BYOL-Explore,利用BYOL学习编码器和前向模型,并使用前向模型的分歧作为探索目标。后续的工作由Jarrett等人[2022]解决了BYOL-Explore锁定在噪音电视上的问题。Yarats等人[2021]提出使用类似于SwAV的聚类方法进行无监督探索,即仅用内在奖励进行探索。
一些研究也探讨了使用大量自然视频数据来预训练RL代理的表示。Xiao等人[2022]提出了MVP,该方法使用掩码自动编码器预训练Transformer编码器以进行机器人控制;而Ma等人[2022]提出了VIP,这是一种使用ResNet-50主干网络和基于观察帧之间时间的监督信号学习RL的通用特征的方法。另一个用于训练RL基础模型的方法是R3M[Nair et al., 2022],该方法结合了时间对比和视频-语言对齐目标。VIP和R3M均在大规模的Ego4D数据集上训练[Grauman et al., 2022],而MVP则结合了ImageNet、Ego4D和额外的手部操控数据。Majumdar等人提出了基于掩码自动编码的VC-1方法。作者测试了该方法及其他基础模型在新的CortexBench测试集上,该基准包括控制、对象操控和导航任务,不同方法在基准的不同部分表现优异。
此外,还有一些专门针对RL学习表示的无监督方法,这些方法并不常用于图像,例如拉普拉斯特征映射[Laplacian eigenmaps, Machado et al., 2017]、前向-后向表示[forward-backward representations, Touati et al., 2023]。Zhang等人[2021]提出,通过使相同奖励的状态表示相同、而不同奖励的状态表示不同来学习表示。
4.2 在自监督学习训练中引入多模态
自监督学习不必局限于单一模态。特别是在视觉-语言多模态领域,最近取得了显著的成效。Contrastive Language–Image Pre-training (CLIP) [Radford et al., 2021] 和 ALIGN [Jia et al., 2021] 是利用图像-字幕对来学习图像和字幕联合嵌入空间的自监督学习方法。在这种方法中,目标是对比学习,将图像和对应的字幕输入不同的编码器模型中,将每种模态编码为定长的嵌入向量。训练数据中的图像-字幕对的嵌入被对齐,而批次中的其他组合则被分开。
这一方法在与基于纯视觉的对比SSL(参见第2.6.1节)的比较中特别有趣。使用第二模态(如文本)可以固定整个SSL训练,不再需要生成多种增强视图来形成稳健表示,因为联合方法通过观察相似的字幕与相似的图像共同出现来学习语义上有意义的表示。因此,这种联合预训练生成的图像编码器在面对保持语义不变的视觉变化(如ImageNet-Sketch中的对象素描[Wang et al., 2019; Radford et al., 2021])时,特别稳健,并在跨领域泛化任务上表现出色。然而,这种表示并非总是理想的,Ghiasi等人[2022]的可视化研究表明,这些模型还会将视觉上不相似但语义或字面上相似的特征分组。为解决这一问题,并提高整体性能(如线性探测),可以结合图像-文本SSL和图像-图像SSL,如Mu等人[2022]结合了CLIP和SimCLR[Radford et al., 2021; Chen et al., 2020b]。
最近的研究进一步将这些视觉-语言系统扩展到更大规模[Ding et al., 2021; Yuan et al., 2021; Singh et al., 2022; Wang et al., 2022d; Fang et al., 2022b],这些研究基于从互联网收集的免费图像-字幕对,例如[Schuhmann et al., 2022]。这些现代SSL模型能够表示视觉和文本,并可用于许多多模态应用,从视觉问答到多模态生成[Alayrac et al., 2022; Li et al., 2022c; Nichol et al., 2022; Rao et al., 2022]。
作为一种替代于单纯视觉学习的稳健视觉表示,视觉-语言预训练的未来尚需进一步探索。尽管其在视觉-语言下游应用中的优势显而易见[Shen et al., 2022; Dou et al., 2022],共享嵌入空间也可以通过先训练视觉编码器、再固定其参数并训练匹配的语言编码器来构建,如[Zhai et al., 2022b]中所述。总体而言,视觉-语言模型只是从多模态中进行大规模自监督学习的第一步。一些原型系统(如Reed等人[2022])在多种输入流(从视觉和文本到表格和代理行为)上进行自监督训练,从而学习到对通用任务有帮助的可重用表示。
4.3 构建用于密集预测任务的具有定位功能的特征提取器
除了语义理解,计算机视觉中的许多任务,如目标检测、分割和深度估计,需要能够提取局部化特征的模型,换句话说,模型需要包含指示输入图像中对象位置的信息。自监督学习对于这些密集预测任务尤为有价值,因为为训练图像收集分割掩码或边界框注释比收集分类标签要昂贵得多。然而,经过精心调优以适应图像分类基准的数据框架可能缺乏对这些密集预测任务有价值的特性。多项研究表明,现有自监督学习策略在下游密集预测任务中表现出不同的效果[Goyal et al., 2019; Purushwalkam and Gupta, 2020; Zhao et al., 2021; Ericsson et al., 2021b; Shwartz-Ziv et al.]。以下将深入探讨这一主题。
自监督学习者在定位任务中的局限性
一些依赖于增强视图或拼图转换(如MoCo[He et al., 2020b]和PIRL[Misra and Maaten, 2020])的SSL方法,因在ImageNet上使用随机裁剪进行训练,学到了遮挡不变性,因为前景对象通常很大,使得不同裁剪包含同一对象的不同部分[Purushwalkam and Gupta, 2020]。然而,这些方法缺乏视角不变性和类别实例不变性。此外,Zhao等人[2021]认为,自监督学习者也缺乏定位信息,因为模型可以使用图像的所有部分(包括前景和背景)来进行预测。这些研究主要在卷积架构上进行实验。值得注意的是,Ericsson等人[2021b]指出,在他们测试的流行SSL算法中,表现最好的依然是卷积神经网络(CNN),在一些检测和分割场景中,其性能与监督学习的对手相当有竞争力。有趣的是,较早的预训练任务,如拼图或上色任务,尽管在MoCo和SimCLR引发的SSL热潮之前就已存在,但在将预训练任务设定为足够“困难”的情况下,也能达到与监督学习框架相当的性能[Goyal et al., 2019]。
CNN还是ViT?
近期研究表明,与卷积架构相比,视觉Transformer(ViT)在其学习的表示中包含了更优越的定位信息[Caron et al., 2021]。而CNN需要特意设计的分割管道来从其特征中提取定位信息,这些信息在ViT的贴块特征中自然而然地出现。专门为Transformer设计的现有SSL方法确认了训练好的模型在下游检测和分割任务中的有效性,特别是在微调后[Li et al., 2021b; He et al., 2022]。需要注意的是,这些SSL算法在其目标函数中显式要求定位,例如通过掩码自动编码,使贴块特征包含图像相应部分的内容信息[He et al., 2022]。最近,掩码自动编码预训练策略也被有效地改编用于卷积架构,使其在下游目标检测和实例分割任务中取得了竞争性表现[Woo et al., 2023]。此外,我们将在下文中看到,一系列专门设计用于定位的预训练策略在Transformer和卷积网络上都能取得不错的效果。
如何在没有标注的情况下学习局部化特征?
为了使表示适应下游的密集预测任务,许多研究提出了修改SSL程序,以专门增强特征中的定位能力。由于这些SSL预训练算法不使用分割或检测注释,因此它们依赖于精心选择的无监督对象先验。
一种对象先验风格是对从单一图像中提取的特征位置之间的关系进行约束,类似于自监督学习过程通常对不同图像之间的关系进行约束。一个这样的先验利用了相邻ViT贴块往往包含相同对象的事实。与鼓励图像增强视图生成相似特征的对比目标不同,SelfPatch鼓励单一图像中相邻贴块生成相似特征[Yun et al., 2022]。另一种相关方法,DenseCL[Wang et al., 2021c],匹配从增强样本中提取的最相似的像素级特征,以自动处理增强在图像中移动对象的情况,只匹配对应于同一对象的特征。更近一步的VICRegL[Bardes et al., 2022]结合了几何和学习匹配,采用非对比损失。类似于基于聚类的方法聚集相关图像,Leopart[Ziegler and Asano, 2022]微调预训练模型以聚类贴块级特征。
除了修改训练损失以改善定位,我们还可以通过将对象放置在多个场景中以增强数据,从而使得模型从对象中提取出相同的特征,而不论其位置如何。Instance Localization[Yang et al., 2021]利用RoIAlign[He et al., 2017](一种用于对象检测的算法),该算法提取对应于特定图像贴块的特征。为此,Instance Localization在两张图像上随机粘贴来自一个图像前景的贴块,并仅提取对应于粘贴前景贴块的
特征,通过对比损失确保前景贴块在不同背景和位置下生成相似的特征。一种竞争方法利用显著性图估计训练图像中对象的位置,然后将这些对象粘贴到背景上并优化相似的目标[Zhao et al., 2021]。除了使用增强来移动对象,Purushwalkam和Gupta[2020]指出,临近的视频帧包含相同对象但在不同位置或视角,这样视频数据上的对比学习也能达到类似的目的。
最近,UP-DETR[Dai et al., 2021]和DETReg[Bar et al., 2022]提出了DETR系列检测器的端到端SSL预训练方法。UP-DETR提出在像素值的条件下检测图像中随机选择的贴块区域的边界框,同时预测它们对应的SwAV嵌入。在DETReg中,检测目标是通过Selective Search算法获得的,不需要人工标注。类似地,检测器为每个目标边界框预测一个关联的SwAV嵌入[Caron et al., 2018]。
用于密集预测任务的视觉-语言模型
在第4.2节中,我们了解到视觉-语言模型可以提取语义上有意义的特征。这些特征也被最近的研究用于开放词汇的对象检测[Kamath et al., 2021; Gu et al., 2021; Zareian et al., 2021; Minderer et al., 2022]。这些研究利用之前讨论的图像-字幕数据库预训练的视觉和语言骨干网络,并在对象检测数据上进行微调。重要的是,预训练的语言模型与图像特征提取器配对,使得开放词汇对象检测器可以通过用合适的提示词查询语言模型,从而检测到微调阶段从未见过的新对象。
5 结论
自监督学习(Self-Supervised Learning, SSL)为推进机器智能建立了一个全新的范式。尽管取得了许多成功,但SSL依然是一个充满挑战的领域,拥有眼花缭乱的各种方法,每种方法都具有复杂的实现。由于研究进展迅速且SSL方法广泛多样,理解并掌握这一领域的难度依然很大。这对那些新加入该领域的研究人员和实践者来说尤其成问题,从而形成了SSL研究和应用的高门槛。我们希望我们的指导手册能够帮助降低这些门槛,使任何背景的好奇研究者都能更好地理解各种方法的细节,掌握其中各个参数的作用,并获得在SSL中取得成功所需的技能。


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!