目录
如何测试 ONNX Runtime 是否使用了 GPU 进行推理
在使用 onnxruntime-gpu 时,我们常常需要确认推理过程中是否使用了 GPU,而不是回退到 CPU。本文将介绍如何创建一个简单的 ONNX 模型,并使用 onnxruntime-gpu 进行推理,确保其在 GPU 上运行。我们还会通过一个简单的循环让程序等待,以便我们有时间检查 GPU 的显存占用情况。
安装 ONNX Runtime GPU 版
首先,你需要安装 onnxruntime-gpu。
我是cuda12.1,我下载这里的whl文件安装了:
https://anaconda.org/search?q=onnxruntime
bash展开代码wget https://aiinfra.pkgs.visualstudio.com/PublicPackages/_apis/packaging/feeds/d3daa2b0-aa56-45ac-8145-2c3dc0661c87/pypi/packages/ort-nightly-gpu/versions/1.17.dev20240118002/ort_nightly_gpu-1.17.0.dev20240118002-cp310-cp310-manylinux_2_28_x86_64.whl/content
mv content ort_nightly_gpu-1.17.0.dev20240118002-cp310-cp310-manylinux_2_28_x86_64.whl
pip install ort_nightly_gpu-1.17.0.dev20240118002-cp310-cp310-manylinux_2_28_x86_64.whl
pip install onnx
一个测试代码,执行后看显存即可
python展开代码import onnx
import onnxruntime as ort
import numpy as np
import torch
# 创建一个简单的 ONNX 模型
def create_random_model(input_size, output_size, model_path):
# 使用 PyTorch 构建一个简单的线性模型
class SimpleModel(torch.nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = torch.nn.Linear(input_size, output_size)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
dummy_input = torch.randn(1, input_size) # 创建一个随机输入
torch.onnx.export(model, dummy_input, model_path, input_names=['input'], output_names=['output'])
# 创建并保存随机模型
model_path = "random_model.onnx"
input_size = 10 # 输入维度
output_size = 5 # 输出维度
create_random_model(input_size, output_size, model_path)
# 加载 ONNX 模型并使用 onnxruntime 测试是否在 GPU 上运行
def test_onnxruntime_gpu(model_path):
# 创建会话,使用 GPU 执行提供者
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
session = ort.InferenceSession(model_path, providers=providers)
# 打印当前使用的执行提供者
print("Execution providers:", session.get_providers())
# 生成一个随机输入
input_data = np.random.randn(1, input_size).astype(np.float32)
inputs = {session.get_inputs()[0].name: input_data}
# 推理
result = session.run(None, inputs)
# 输出结果,确认模型运行成功
print("Model output:", result)
# 进入一个循环等待用户输入以退出
input("模型已加载并运行完毕,按下任意键退出程序...")
# 测试 GPU
test_onnxruntime_gpu(model_path)
创建一个简单的 ONNX 模型
为了测试,我们将使用 PyTorch 创建一个简单的全连接线性模型,并导出为 ONNX 格式。即使你没有现成的 ONNX 模型,也可以通过这种方式生成一个供测试使用的模型。
这段代码使用 PyTorch 创建了一个线性模型,并生成了一个随机输入。接着,我们使用 torch.onnx.export() 将模型保存为 ONNX 格式文件。
使用 ONNX Runtime 测试 GPU 推理
接下来,我们使用 onnxruntime 来加载这个模型,并进行推理。我们会打印出 ONNX Runtime 当前使用的执行提供者,以确认是否使用了 GPU。
解析代码
-
选择执行提供者:通过
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']指定优先使用 GPU 执行。如果没有 GPU 或无法使用CUDAExecutionProvider,则会自动回退到 CPU。 -
确认执行提供者:通过
session.get_providers()打印当前的执行提供者,能够确认是否成功使用了 GPU。如果输出中包含CUDAExecutionProvider,说明推理正在 GPU 上进行。 -
随机输入与推理:我们生成一个随机输入,并通过
session.run()进行推理,结果会打印出来。 -
等待用户输入:为了让你有时间检查显存占用情况,程序在推理结束后会进入一个等待状态,直到你按下任意键退出程序。这段时间你可以使用
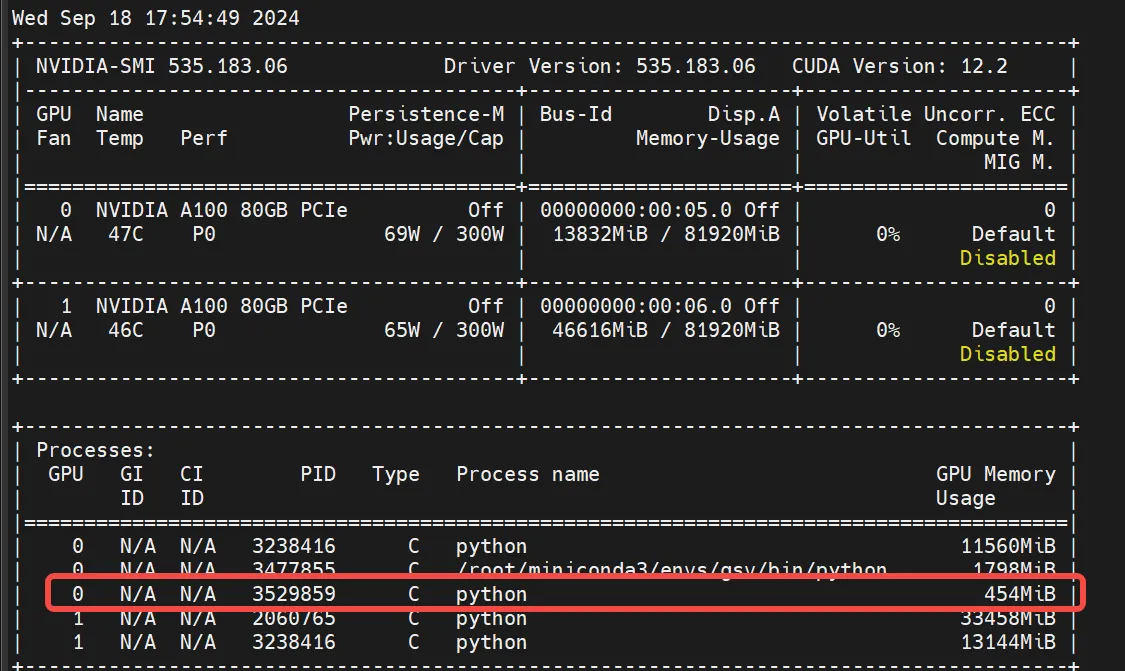
nvidia-smi命令查看 GPU 的显存使用情况。
如何检查 GPU 显存使用情况
在程序运行时,你可以打开一个新的终端窗口,运行以下命令来检查显存占用情况:
bash展开代码nvidia-smi
如果推理过程中显存占用增加,说明 GPU 正在被使用;否则,说明模型可能是在 CPU 上运行。
总结
通过这个简单的例子,我们可以轻松测试 ONNX Runtime 是否在 GPU 上运行模型,并通过显存占用情况进一步确认 GPU 是否参与推理。这种方法特别适合在开发环境中快速验证 GPU 的使用情况。
希望这篇博客能帮助你了解如何在 onnxruntime-gpu 中测试 GPU 推理,并为你的项目提供参考。如果你有任何问题,欢迎在评论区讨论!


本文作者:Dong
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC。本作品采用《知识共享署名-非商业性使用 4.0 国际许可协议》进行许可。您可以在非商业用途下自由转载和修改,但必须注明出处并提供原作者链接。 许可协议。转载请注明出处!